
V tomto tutoriálu vám ukážeme, jak nainstalovat Apache Hadoop na Debian 11. Pro ty z vás, kteří nevěděli, Apache Hadoop je open source softwarová platforma založená na Javě která spravuje zpracování a ukládání dat pro aplikace s velkým objemem dat. Je navržena tak, aby se škálovala z jednotlivých serverů na tisíce počítačů, z nichž každý nabízí místní výpočet a úložiště.
Tento článek předpokládá, že máte alespoň základní znalosti Linuxu, víte, jak používat shell, a co je nejdůležitější, hostujete svůj web na vlastním VPS. Instalace je poměrně jednoduchá a předpokládá, že běží v účtu root, pokud ne, možná budete muset přidat 'sudo ‘ k příkazům pro získání oprávnění root. Ukážu vám krok za krokem instalaci Apache Hadoop na Debian 11 (Bullseye).
Předpoklady
- Server s jedním z následujících operačních systémů:Debian 11 (Bullseye).
- Abyste předešli případným problémům, doporučujeme použít novou instalaci operačního systému.
- Přístup SSH k serveru (nebo stačí otevřít Terminál, pokud jste na počítači).
non-root sudo usernebo přístup kroot user. Doporučujeme jednat jakonon-root sudo user, protože však můžete poškodit svůj systém, pokud nebudete při jednání jako root opatrní.
Nainstalujte Apache Hadoop na Debian 11 Bullseye
Krok 1. Než nainstalujeme jakýkoli software, je důležité se ujistit, že je váš systém aktuální, spuštěním následujícího apt příkazy v terminálu:
Aktualizace sudo aptudo apt
Krok 2. Instalace Java.
Apache Hadoop je aplikace založená na Javě. Budete tedy muset do svého systému nainstalovat Javu:
sudo apt install default-jdk default-jre
Ověřte instalaci Java:
verze Java
Krok 3. Vytvoření uživatele Hadoop.
Spuštěním následujícího příkazu vytvořte nového uživatele s názvem Hadoop:
adduser hadoop
Dále přepněte na uživatele Hadoop, jakmile bude uživatel vytvořen:
su - hadoop
Nyní je čas vygenerovat ssh klíč, protože Hadoop vyžaduje přístup ssh ke správě svého uzlu, vzdáleného nebo místního počítače, takže pro náš jediný uzel nastavení Hadoop nakonfigurujeme tak, že máme přístup k localhost:
ssh-keygen -t rsa
Poté udělte oprávnění k souboru author_keys:
cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keyschmod 0600 ~/.ssh/authorized_keys
Potom ověřte připojení SSH bez hesla pomocí následujícího příkazu:
ssh IP-adresa-vašeho-serveru
Krok 4. Instalace Apache Hadoop na Debian 11.
Nejprve přepněte na uživatele Hadoop a stáhněte si nejnovější verzi Hadoopu z oficiální stránky pomocí následujícího wget příkaz:
su - hadoopwget https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.1/hadoop-3.3.1-src.tar.gz
Dále rozbalte stažený soubor pomocí následujícího příkazu:
tar -xvzf hadoop-3.3.1.tar.gz
Po rozbalení změňte aktuální adresář na složku Hadoop:
su rootcd /home/hadoopmv hadoop-3.3.1 /usr/local/hadoop
Dále vytvořte adresář pro ukládání protokolů pomocí následujícího příkazu:
mkdir /usr/local/hadoop/logs
Změňte vlastnictví adresáře Hadoop na Hadoop:
chown -R hadoop:hadoop /usr/local/hadoopsu hadoop
Poté nakonfigurujeme proměnné prostředí Hadoop:
nano ~/.bashrc
Přidejte následující konfiguraci:
export HADOOP_HOME =/ usr / local / hadoopexport HADOOP_INSTALL =$ HADOOP_HOMEexport HADOOP_MAPRED_HOME =$ HADOOP_HOMEexport HADOOP_COMMON_HOME =$ HADOOP_HOMEexport HADOOP_HDFS_HOME =$ HADOOP_HOMEexport YARN_HOME =$ HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR =$ HADOOP_HOME / lib / nativeexport PATH =$ PATH:$ HADOOP_HOME / sbin:$HADOOP_HOME/binexport HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Uložte a zavřete soubor. Poté aktivujte proměnné prostředí:
zdroj ~/.bashrc
Krok 5. Nakonfigurujte Apache Hadoop.
- Konfigurace proměnných prostředí Java:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Přidejte následující konfiguraci:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
Dále si musíme stáhnout aktivační soubor Javax:
cd /usr/local/hadoop/libsudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jarOvěřte verzi Apache Hadoop:
verze hadoopVýstup:
Hadoop 3.3.1
- Nakonfigurujte soubor core-site.xml:
nano $HADOOP_HOME/etc/hadoop/core-site.xml
Přidejte následující soubor:
fs.default.name hdfs://0.0.0.0:9000 Výchozí URI systému souborů
- Nakonfigurujte soubor hdfs-site.xml:
Před konfigurací vytvořte adresář pro ukládání metadat uzlů:
mkdir -p /home/hadoop/hdfs/{namenode,datanode}chown -R hadoop:hadoop /home/hadoop/hdfs Dále upravte hdfs-site.xml a definujte umístění adresáře:
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Přidejte následující řádek:
dfs.replication 1 dfs.name.dir soubor :///home/hadoop/hdfs/namenode dfs.data.dir file:///home/hadoop/hdfs/datanode
- Nakonfigurujte soubor mapred-site.xml:
Nyní upravujeme mapred-site.xml soubor:
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Přidejte následující konfiguraci:
mapreduce.framework.name příze
- Nakonfigurujte soubor yarn-site.xml:
Budete muset upravit yarn-site.xml soubor a definujte nastavení související s YARN:
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Přidejte následující konfiguraci:
yarn.nodemanager.aux-services mapreduce_shuffle
- Formátovat HDFS NameNode.
Spuštěním následujícího příkazu naformátujte Hadoop Namenode:
hdfs namenode -format
- Spusťte klastr Hadoop.
Nyní spustíme NameNode a DataNode následujícím příkazem:
start-dfs.sh
Dále spusťte správce zdrojů a uzlů YARN:
start-yarn.sh
Nyní je můžete ověřit pomocí následujícího příkazu:
jps
Výstup:
hadoop@idroot.us:~$ jps58000 NameNode54697 DataNode55365 ResourceManager55083 SecondaryNameNode58556 Jps55365 NodeManager
Krok 6. Přístup k webovému rozhraní Hadoop.
Po úspěšné instalaci otevřete webový prohlížeč a přejděte k Apache Hadoop pomocí adresy URL http://your-server-ip-address:9870 . Budete přesměrováni na webové rozhraní Hadoop:
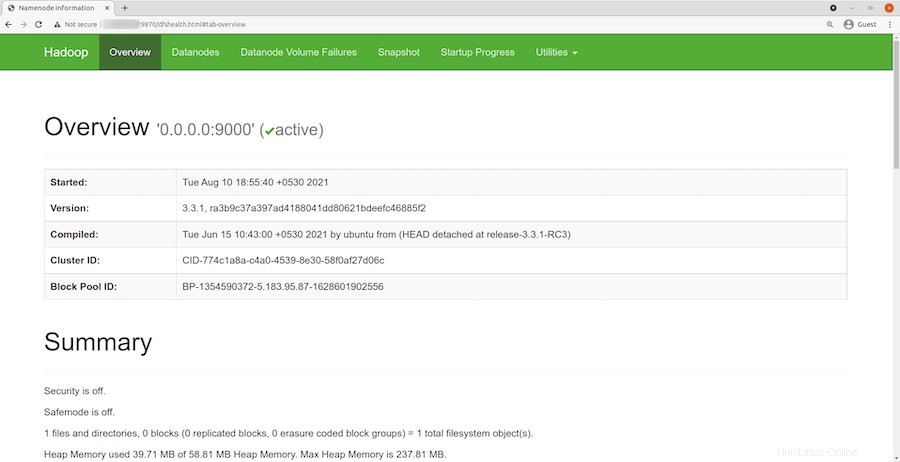
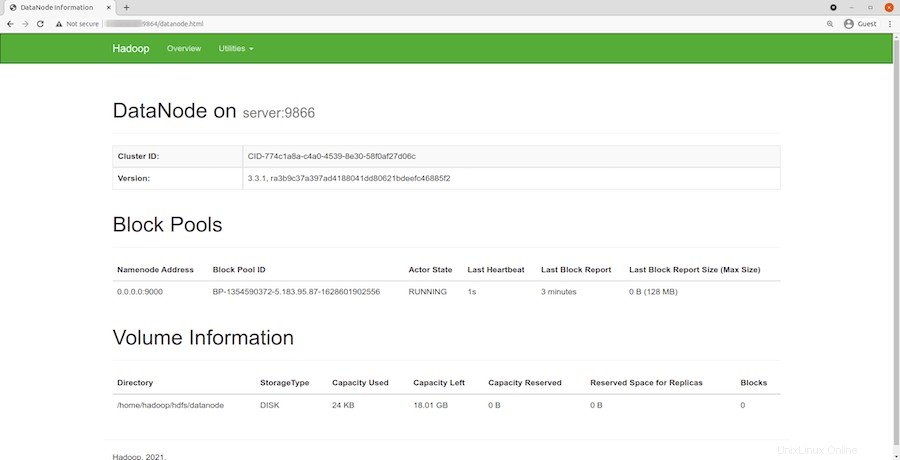
Navigujte svou adresu URL nebo IP místního hostitele pro přístup k jednotlivým DataNodes:http://your-server-ip-address:9864
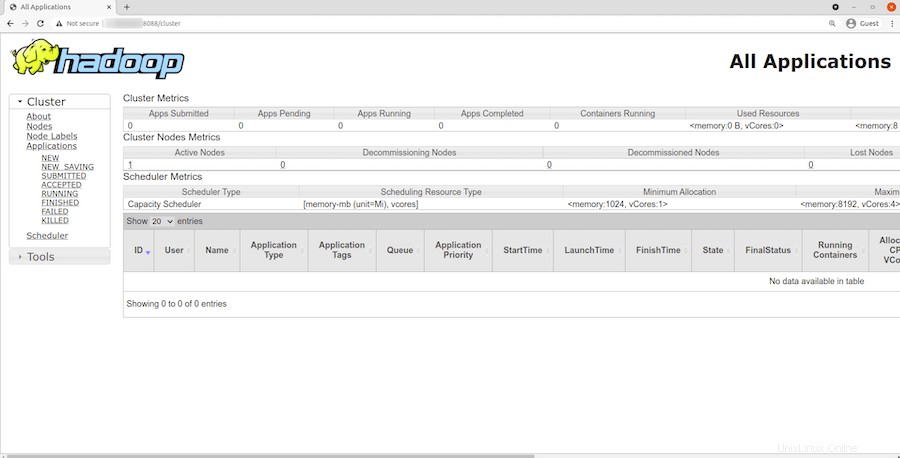
Pro přístup ke správci zdrojů YARN použijte adresu URL http://your-server-ip-adddress:8088 . Měli byste vidět následující obrazovku:
Gratulujeme! Úspěšně jste nainstalovali Hadoop. Děkujeme, že jste použili tento návod k instalaci nejnovější verze Apache Hadoop na Debian 11 Bullseye. Pro další pomoc nebo užitečné informace vám doporučujeme navštívit oficiální Apache webové stránky.