
V tomto tutoriálu vám ukážeme, jak nainstalovat Apache Hadoop na CentOS 8. Pro ty z vás, kteří nevěděli, Apache Hadoop je open-source framework používaný pro distribuované úložiště jako a také distribuované zpracování velkých dat na klastrech počítačů, které běží na komoditním hardwaru. Spíše než se spoléhat na hardware při poskytování vysoké dostupnosti, je samotná knihovna navržena tak, aby detekovala a řešila selhání na aplikační vrstvě, takže poskytuje vysoce dostupnou službu na horní část shluku počítačů, z nichž každý může být náchylný k selhání.
Tento článek předpokládá, že máte alespoň základní znalosti Linuxu, víte, jak používat shell, a co je nejdůležitější, hostujete svůj web na svém vlastním VPS. Instalace je poměrně jednoduchá a předpokládá, že běží v účtu root, pokud ne, možná budete muset přidat 'sudo ‘ k příkazům pro získání oprávnění root. Ukážu vám krok za krokem instalaci Apache Hadoop na server CentOS 8.
Předpoklady
- Server s jedním z následujících operačních systémů:CentOS 8.
- Abyste předešli případným problémům, doporučujeme použít novou instalaci operačního systému.
- Přístup SSH k serveru (nebo stačí otevřít Terminál, pokud jste na počítači).
non-root sudo usernebo přístup kroot user. Doporučujeme jednat jakonon-root sudo user, protože však můžete poškodit svůj systém, pokud nebudete při jednání jako root opatrní.
Nainstalujte Apache Hadoop na CentOS 8
Krok 1. Nejprve začněme tím, že zajistíme, aby byl váš systém aktuální.
sudo dnf update
Krok 2. Instalace Java.
Apache Hadoop je napsán v Javě a podporuje pouze Javu verze 8. OpenJDK 8 můžete nainstalovat pomocí následujícího příkazu:
sudo dnf install java-1.8.0-openjdk ant
Zkontrolujte verzi Java:
java -version
Krok 3. Instalace Apache Hadoop CentOS 8.
Pro konfiguraci Apache Hadoop se doporučuje vytvořit normálního uživatele, vytvořit uživatele pomocí následujícího příkazu:
useradd hadoop passwd hadoop
Dále budeme muset nakonfigurovat ověřování SSH bez hesla pro místní systém:
su - hadoop ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 640 ~/.ssh/authorized_keys
Ověřte konfiguraci ssh bez hesla pomocí příkazu:
ssh localhost
Další kroky:stáhněte si nejnovější stabilní verzi Apache Hadoop. V okamžiku psaní tohoto článku je to verze 3.2.1:
wget http://apachemirror.wuchna.com/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz tar -xvzf hadoop-3.2.1.tar.gz mv hadoop-3.2.1 hadoop
Potom budete muset ve svém systému nakonfigurovat proměnné prostředí Hadoop a Java:
nano ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.232.b09-2.el8_1.x86_64/ export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"."
Nyní aktivujeme proměnné prostředí následujícím příkazem:
source ~/.bashrc
Dále otevřete soubor proměnných prostředí Hadoop:
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.232.b09-2.el8_1.x86_64/
Hadoop má mnoho konfiguračních souborů, které je třeba nakonfigurovat podle požadavků vaší infrastruktury Hadoop. Začněme s konfigurací základním nastavením clusteru Hadoop s jedním uzlem:
cd $HADOOP_HOME/etc/hadoop
Upravit soubor core-site.xml:
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
Vytvořte adresáře namenode a datanode pod hadoop user home /home/hadoop adresář:
mkdir -p ~/hadoopdata/hdfs/{namenode,datanode} Upravit hdfs-site.xml :
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hadoopdata/hdfs/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hadoopdata/hdfs/datanode</value> </property> </configuration>
Upravte soubor mapred-site.xml :
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Upravit soubor yarn-site.xml:
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
Nyní naformátujte namenode pomocí následujícího příkazu, nezapomeňte zkontrolovat adresář úložiště:
hdfs namenode -format
Spusťte démony NameNode i DataNode pomocí skriptů poskytovaných Hadoopem:
start-dfs.sh
Krok 4. Nakonfigurujte bránu firewall.
Spuštěním následujícího příkazu povolte připojení Apache Hadoop přes bránu firewall:
firewall-cmd --permanent --add-port=9870/tcp firewall-cmd --permanent --add-port=8088/tcp firewall-cmd --reload
Krok 5. Přístup k Apache Hadoop.
Apache Hadoop bude ve výchozím nastavení k dispozici na portu HTTP 9870 a portu 50070. Otevřete svůj oblíbený prohlížeč a přejděte na http://your-domain.com:9870 nebo http://your-server-ip:9870 .
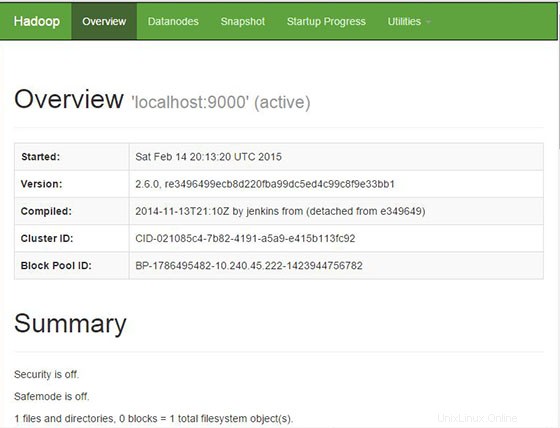
Blahopřejeme! Úspěšně jste nainstalovali Apache Hadoop. Děkujeme, že jste použili tento návod k instalaci Hadoop na systém CentOS 8. Pro další pomoc nebo užitečné informace vám doporučujeme navštívit oficiální web Apache Hadoop.