Úvod
Normalizace databáze je metoda v návrhu relační databáze, která pomáhá správně organizovat datové tabulky. Cílem procesu je vytvořit systém, který věrně zobrazuje informace a vztahy bez ztráty dat nebo redundance.
Tento článek vysvětluje normalizaci databáze a způsob normalizace databáze pomocí praktického příkladu.

Co je normalizace databáze?
Normalizace databáze je technika pro vytváření databázových tabulek s vhodnými sloupci a klíči rozkladem velké tabulky na menší logické celky. Proces také bere v úvahu požadavky prostředí, ve kterém se databáze nachází.
Normalizace je iterativní proces. K normalizaci databáze obvykle dochází prostřednictvím série testů. Každý následující krok rozloží tabulky na lépe spravovatelné informace, díky čemuž je celková databáze logická a snáze se s ní pracuje.
Proč je normalizace databáze důležitá?
Normalizace pomáhá návrháři databáze optimálně distribuovat atributy do tabulek. Technika eliminuje následující:
- Atributy s násobkem hodnoty.
- Zdvojené nebo opakované atributy.
- Nepopisné atributy.
- Atributy s nadbytečnými informace.
- Atributy vytvořené z jiných funkcí .
Přestože není nutná celková normalizace databáze, poskytuje dobře fungující informační prostředí. Metoda systematicky zajišťuje:
- Struktura databáze vhodné pro obecné dotazy.
- Minimalizovaná redundance dat , což zvyšuje efektivitu paměti na databázovém serveru.
- Maximální integrita dat prostřednictvím redukovaných anomálií vkládání, aktualizace a odstraňování.
Normalizace databáze transformuje celkovou konzistenci databáze a poskytuje efektivní prostředí.
Databázové redundance a anomálie
Při změně entity v tabulce s nadbytečnostmi , musíte upravit všechny opakované výskyty informací a jakékoli další informace související se změněnými údaji. V opačném případě se databáze stane nekonzistentní a anomálie dojít při provádění změn.
Například v následující nenormalizované tabulce:

Tabulka obsahuje redundanci dat , což zase způsobuje tři anomálie při provádění změn dat:
1. Vložte anomálii . Při pokusu o zařazení nového zaměstnance do finančního sektoru musíte znát i jméno manažera. Jinak nemůžete do tabulky vkládat data.
2.Aktualizujte anomálii. Pokud zaměstnanec změní sektory, jméno manažera skončí nesprávně. Pokud se například Jacob změní na finance, Adam zůstane jeho manažerem.
3. Smažte anomálii . Pokud se Joshua rozhodne společnost opustit, smazáním řádku se také odstraní informace o tom, že existuje finanční sektor.
Řešením těchto anomálií je normalizace databáze koncepty a kroky.
Koncepty normalizace databáze
Základní pojmy používané při normalizaci databáze jsou:
- Klíče . Atributy sloupců, které jednoznačně identifikují záznam databáze.
- Funkční závislosti . Omezení mezi dvěma atributy ve vztahu.
- Normální formy . Kroky k dosažení určité kvality databáze.
Databáze normálních formulářů
Normalizace databáze je dosažena pomocí sady pravidel známých jako normální formy . Ústředním konceptem je pomoci návrháři databáze dosáhnout požadované kvality relační databáze.
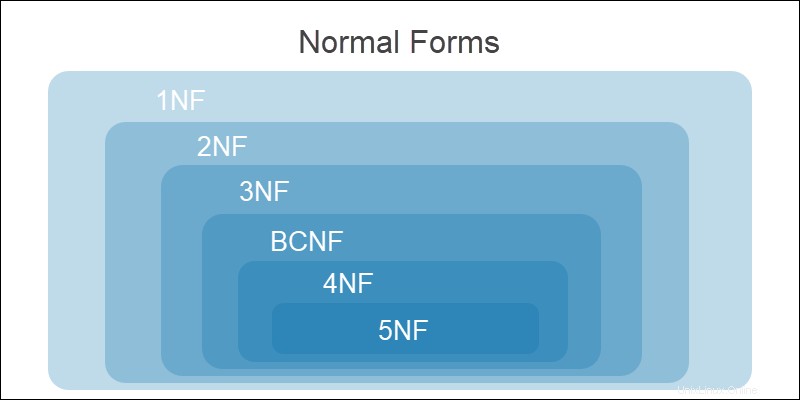
Všechny úrovně normalizace jsou kumulativní. Předchozí normální formulář musí být splněny než přejdete k následujícímu formuláři.
Stupně normalizace jsou:
| Fáze | Anomálie redundance byly vyřešeny |
|---|---|
| Nenormalizovaný formulář (UNF) | Stav před jakoukoli normalizací. Jsou přítomny redundantní a komplexní hodnoty. |
| První normální forma (1NF) | Opakující se a komplexní hodnoty jsou rozděleny, takže všechny instance jsou atomické. |
| Druhá normální forma (2NF) | Částečné závislosti se rozloží na nové tabulky. Všechny řádky funkčně závisí na primárním klíči. |
| Třetí normální forma (3NF) | Přechodné závislosti se rozkládají na nové tabulky. Neklíčové atributy závisí na primárním klíči. |
| Normální forma Boyce-Codda (BCNF) | Přechodné a částečné funkční závislosti pro všechny kandidátské klíče se rozloží na nové tabulky. |
| Čtvrtá normální forma (4NF) | Odstranění vícehodnotových závislostí. |
| Pátá normální forma (5NF) | Odstranění závislostí JOIN. |
Databáze je normalizována, když splní třetí normální formu . Další kroky v normalizaci zkomplikují návrh databáze a mohou ohrozit funkčnost systému.
Co je to KLÍČ?
Databázový klíč je atribut nebo skupina funkcí, které jedinečně popisují entitu v tabulce. Typy klíčů používaných při normalizaci jsou:
- Super klíč . Sada funkcí, které jednoznačně definují každý záznam v tabulce.
- Klíč kandidáta . Klíče vybrané ze sady super klíčů, kde je počet polí minimální.
- Primární klíč . Nejvhodnější volba ze sady kandidátských klíčů slouží jako primární klíč tabulky.
- Zahraniční klíč . Primární klíč jiné tabulky.
- Složený klíč . Dva nebo více atributů dohromady tvoří jedinečný klíč, ale nejedná se o klíče jednotlivě.
Jak se tabulky rozkládají na několik jednodušších tabulek, klíče definují referenční bod pro entitu databáze.
Například v následující struktuře databáze:

Několik příkladů super klíčů v tabulce jsou:
- ID zaměstnance
- (číslo zaměstnance, jméno)
Všechny super klíče mohou sloužit jako jedinečný identifikátor pro každý řádek. Na druhou stranu jméno nebo věk zaměstnance nejsou jedinečné identifikátory, protože dva lidé mohou mít stejné jméno nebo věk.
Klíče kandidátů pocházejí ze sady super klíčů, kde je počet polí minimální. Volba sestává ze dvou možností:
- ID zaměstnance
Obě možnosti obsahují minimální počet polí, což z nich činí optimální kandidátní klíče. Nejlogičtější volba pro primární klíč je ID zaměstnance protože e-mail zaměstnance se může změnit. Primární klíč v tabulce lze snadno označit jako cizí klíč v jiné tabulce.
Funkční závislosti databáze
Funkční závislost databáze představuje vztah mezi dvěma atributy v databázové tabulce. Některé typy funkčních závislostí jsou:
- Trviální funkční závislost . Závislost mezi atributem a skupinou funkcí, kde je původní prvek ve skupině.
- Netriviální funkční závislost . Závislost mezi atributem a skupinou, kde prvek není ve skupině.
- Transitive Dependency. Funkční závislost mezi třemi atributy, kde druhý závisí na prvním a třetí závisí na druhém. Kvůli přechodnosti je třetí atribut závislý na prvním.
- Vícehodnotová závislost. Závislost, kde na jednom atributu závisí více hodnot.
Funkční závislosti jsou zásadním krokem v normalizaci databáze. Z dlouhodobého hlediska pomáhají závislosti určit celkovou kvalitu databáze.
Příklad normalizace databáze – Jak normalizovat databázi?
Obecné kroky normalizace databáze fungují pro každou databázi. Konkrétní kroky rozdělení tabulky a také to, zda přejít přes 3NF, závisí na případu použití.
Příklad nenormalizované databáze
Nenormalizovaná tabulka má v jednom poli více hodnot a v nejhorším případě i nadbytečné informace.
Například:
| ID správce | název správce | oblast | ID zaměstnance | jméno zaměstnance | sectorID | sectorName |
|---|---|---|---|---|---|---|
| 1 | Adam A. | Východ | 1 2 | David D. Eugene E. | 4 3 | Finance IT |
| 2 | Betty B. | Západ | 3 4 5 | George G. Henry H. Ingrid I. | 2 1 4 | Zabezpečení Správa Finance |
| 3 | Carl C. | Sever | 6 7 | James J. Katy K. | 1 4 | Administrace Finance |
Vkládání, aktualizace a odstraňování dat je složitý úkol. Provádění jakýchkoli změn ve stávající tabulce má vysoké riziko ztráty informací.
Krok 1:První normální formulář 1NF
Pro přepracování databázové tabulky do 1NF musí být hodnoty v jednom poli atomické. Všechny složité entity v tabulce se rozdělí do nových řádků nebo sloupců.
Informace ve sloupcích ID správce , název správce a oblast opakujte pro každého zaměstnance, aby nedošlo ke ztrátě informací.
| ID správce | název správce | oblast | ID zaměstnance | jméno zaměstnance | sectorID | sectorName |
|---|---|---|---|---|---|---|
| 1 | Adam A. | Východ | 1 | David D. | 4 | Finance |
| 1 | Adam A. | Východ | 2 | Eugene E. | 3 | IT |
| 2 | Betty B. | Západ | 3 | George G. | 2 | Zabezpečení |
| 2 | Betty B. | Západ | 4 | Henry H. | 1 | Administrace |
| 2 | Betty B. | Západ | 5 | Ingrid I. | 4 | Finance |
| 3 | Carl C. | Sever | 6 | James J. | 1 | Administrace |
| 3 | Carl C. | Sever | 7 | Katy K. | 4 | Finance |
Přepracovaná tabulka vyhovuje první normální formě.
Krok 2:Druhá normální forma 2NF
Druhá normální forma v normalizaci databáze uvádí, že každý řádek v tabulce databáze musí záviset na primárním klíči.
Tabulka se rozdělí na dvě tabulky, aby vyhovovala normálnímu tvaru:
- Správce (managerID, managerName, area)
| ID správce | název správce | oblast |
|---|---|---|
| 1 | Adam A. | Východ |
| 2 | Betty B. | Západ |
| 3 | Carl C. | Sever |
- Zaměstnanec (ID zaměstnance, jméno zaměstnance, ID manažera, ID sektoru, název sektoru)
| ID zaměstnance | jméno zaměstnance | ID správce | sectorID | sectorName |
|---|---|---|---|---|
| 1 | David D. | 1 | 4 | Finance |
| 2 | Eugene E. | 1 | 3 | IT |
| 3 | George G. | 2 | 2 | Zabezpečení |
| 4 | Henry H. | 2 | 1 | Administrace |
| 5 | Ingrid I. | 2 | 4 | Finance |
| 6 | James J. | 3 | 1 | Administrace |
| 7 | Katy K. | 3 | 4 | Finance |
Výsledná databáze ve druhé normální podobě jsou aktuálně dvě tabulky bez částečných závislostí.
Krok 3:Třetí normální forma 3NF
Třetí normální forma rozkládá jakékoli tranzitivní funkční závislosti. Aktuálně je tabulka Zaměstnanec má tranzitivní závislost, která se rozkládá na dvě nové tabulky:
- Zaměstnanec (ID zaměstnance, jméno zaměstnance, ID manažera, ID sektoru)
| ID zaměstnance | jméno zaměstnance | ID správce | sectorID |
|---|---|---|---|
| 1 | David D. | 1 | 4 |
| 2 | Eugene E. | 1 | 3 |
| 3 | George G. | 2 | 2 |
| 4 | Henry H. | 2 | 1 |
| 5 | Ingrid I. | 2 | 4 |
| 6 | James J. | 3 | 1 |
| 7 | Katy K. | 3 | 4 |
- Sektor (ID sektoru, Název_sektoru)
| sectorID | sectorName |
|---|---|
| 1 | Administrace |
| 2 | Zabezpečení |
| 3 | IT |
| 4 | Finance |
Databáze je v současné době ve třetí normální formě s celkem třemi vztahy. Konečná struktura je:

V tomto okamžiku je databáze normalizována . Jakékoli další kroky normalizace závisí na případu použití dat.