Úvod
Potřeba zachytit a zpracovat velká data je hlavní hnací silou popularity databáze NoSQL. Uložená data musí být dostupná kdykoli, z jakéhokoli místa a na jakémkoli zařízení. Jedním ze způsobů, jak uspokojit rostoucí poptávku, je rozšířit a koupit větší server. Je však efektivnější škálovat a používat cluster serverů na vyžádání.
Model relační databáze není vhodný pro distribuovaný systém zahrnující více počítačů. Databáze NoSQL poskytují životaschopné řešení tím, že se zaměřují na výkon a dostupnost a zároveň obětují část konzistence obvykle identifikované u relačních databází.
Kromě odpovědi na otázku „Co je NoSQL “, tento tutoriál používá jednoduché příklady ke zvýraznění základních konceptů, funkcí a typů NoSQL .

Co je NoSQL? (definice NoSQL)
NoSQL (Not SQL nebo Not Only SQL) je obecný termín používaný pro databáze, které nezávisí na relačním modelu. Data nemusí mít striktní schéma ani obvyklou strukturu SQL tabulky. Nejčastěji jsou data agregována jako páry klíč–hodnota, dokumenty JSON, grafy, nebotabulky se širokým sloupcem.
Pomocí databází NoSQL můžete ukládat obrovské objemy nestrukturovaných dat tak, jak přicházejí, a později je strukturovat. Podle očekávání to vede k mnohem lepší propustnosti, rychlosti čtení/zápisu a umožňuje horizontálně škálovat servery.
Nerelační databáze, pokud jsou aplikovány ve správném prostředí použití, přinášejí významné výhody z hlediska výkonu a flexibility. Neaplikování schématu ve vstupním bodě dat však také znamená, že je obtížnější dotazovat se v NoSQL databázích, udržovat konzistenci dat a vytvářet vztahy mezi datovými sadami.
Jak NoSQL funguje
Základní myšlenkou NoSQL je optimalizovat výkon databáze pro horizontální škálování, velké objemy dat a nízkou latenci tím, že upustíme od některých omezení konzistence dat přítomných v RDBMS. Místo pevných datových modelů, jako jsou tabulky, sloupce nebo řádky, nabízejí databáze NoSQL flexibilní modely. V případech použití, které nevyžadují relační konzistenci, tyto modely pomáhají NoSQL fungovat lépe než relační databáze.
Funkce databází NoSQL
Databáze NoSQL jsou strukturálně rozmanité a nabízejí různé modely ukládání dat. Existuje však několik společných atributů, které odlišují NoSQL od relačních databází.
Schéma při čtení
NoSQL databáze umožňuje uložit data před použitím struktury nebo schéma .
Schéma je aplikováno kódem aplikace pouze tehdy, když přistupuje k datům. Tento proces je často označován jako schéma při čtení . Díky tomu, že data předem nestrukturujete, mohou databáze NoSQL zapisovat a číst obrovské objemy dat výrazně rychleji než relační databáze.
NoSQL vs relační databáze
Naproti tomu relační model SQL strukturuje příchozí data předtím, než jsou zapsána do databáze. Předdefinovaný návrh schématu se používá pro klasifikaci všech možných datových typů předem. Schéma je aplikováno napříč, protože data jsou strukturována a uložena v tabulkách, sloupcích a řádcích.
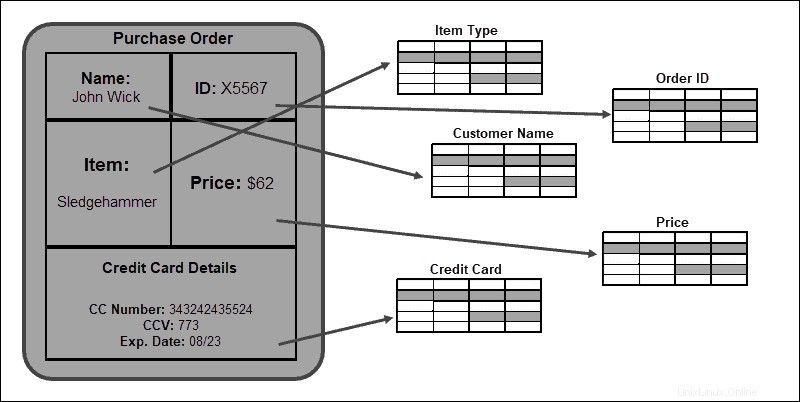
Přísná tabulková struktura je výhodou při navazování vztahů mezi tabulkami a databázovými prvky. Konzistence a integrita dat je zaručena dodržováním tohoto schématu.
Nerelační datový model
NoSQL databáze nenavazují vztahy mezi jednotlivými záznamy. Jeden záznam je obvykle uložen jako samostatný dokument JSON a replikován mezi více uzly v clusteru.
Použijeme jednoduchý příklad zahrnující data o hudebních kapelách. V nerelačním modelu BandID , Název skupiny , Země , Žánr , Štítek , ID alba , Název alba, aDatum vydání atributy jsou uloženy v jediné Radiohead dokument. Pokud potřebujete zjistit datum vydání alba Radiohead, OK Computer , odezva je blesková. Dotaz poskytuje výsledky mnohem rychleji, protože nepotřebuje získávat informace z více tabulek (jako v relačních databázích), ale spíše z jedné položky.
Agregovaná data v jednom záznamu nemohou souviset s agregovanými daty v jiném záznamu. Každý relevantní záznam v databázi je třeba aktualizovat, pokud chcete přidat atribut, jako je streamovací služba. Databáze NoSQL se proto nejlépe hodí pro velké objemy dat, která později nemusí být strukturována nebo propojena.
BASE vs ACID
Potřebuje databáze zrušit operaci a zajistit konzistenci dat v případě selhání sítě? Nebo by měly databáze riskovat nekonzistenci dat, aby byla zajištěna vysoká dostupnost?
Hlavním cílem NoSQL je udržovat dostupnost tím, že nabízí případnou konzistenci. Případná konzistence je součástí BASE sémantiky. BASE uvádí, že jakmile jsou data zapsána, nakonec se objeví pro čtení. Bez silných záruk máte jen omezenou pravděpodobnost, že budete znát aktuální stav, protože se možná ještě nesblížil. Pokud systém funguje a vy čekáte dostatečně dlouho po jakékoli dané sadě vstupů, nakonec budete znát skutečný stav databáze.
Nevýhodou je, že po vyřešení konfliktů nemusí data přetrvávat. Čtení nemusí získat poslední zápis po neznámou dobu. Příspěvek na Facebooku, který se na několik minut neobjeví, je přijatelný, ale neschopnost okamžitě vidět finanční transakci je závažný problém.
KYSELINA
- A tomicity. Operace má vliv pouze na specifikovaná data.
- C stálost. Každá operace přesune databázi z jednoho konzistentního stavu do jiného konzistentního stavu.
- Já útěcha. Jedna operace neovlivňuje ostatní souběžné operace.
- D užitkovost. Data se po úspěšné transakci neztratí.
BASE
- B asicky A k dispozici. Operace zápisu a čtení jsou dostupné v maximální možné míře, ale bez jakýchkoli přísných záruk.
- S oft State. Bez záruk nevíme, ale očekáváme, že data budou nakonec konzistentní.
- E venual Konzistence. Pokud je systém plně funkční a uplynula dostatečně dlouhá doba, nakonec budeme znát skutečný stav databáze.
Relační databáze se zaměřují na konzistenci jako nejdůležitější vlastnost, kterou je třeba udržovat. Konzistence Vlastnost databáze zajišťuje, že pokud zapíšete záznam do databáze a poté si jej okamžitě vyžádáte, zaručeně jej uvidíte. Sada vlastností ACID, aplikovaná relačními databázemi, znamená, že jakmile jsou data zapsána, máte plnou konzistenci čtení.
Zjistěte více o dvou nejoblíbenějších databázových transakčních modelech a jejich rozdílech v článku ACID vs BASE.
Horizontální měřítko
Společnosti našly efektivní způsoby, jak vydělat na datech. Rychlý růst objemu, rychlosti a rozmanitosti těchto dat vedl k nárůstu databází NoSQL.
Velké webové stránky a online platformy potřebovaly překonat některá omezení relačních databází, jako je rychlost čtení/zápisu a potřeba předem normalizovat data. Jedním z významných omezení jenepružnost relačního modelu pokud jde o škálování. V relačním modelu nejsou data obvykle rozdělena nebo segregována. Místo toho se soustředí na jeden uzel a databáze lze škálovat pouze zvýšením výkonu stávajícího hardwaru.
Databáze NoSQL jsou navrženy tak, aby efektivně fungovaly na distribuovaných systémech které se rychle horizontálně škálují. Distribuovaný systém má další výhodu v tom, že poskytuje stálou vysokou dostupnost. Na serverech a stojanech je uchováváno více replik záznamu a selhání hardwaru neovlivňuje dostupnost dat. Ke správě prudce rostoucího zatížení dat můžete bezpečně používat komoditní hardware místo drahých špičkových serverů.
Typy NoSQL databází
Nerelační databázové modely lze obecně rozdělit do čtyř kategorií.
- obchod s páry klíč–hodnota umožňuje ukládat jakýkoli typ dat pod jedinečným klíčem.
- Databáze dokumentů používá podobný přístup tím, že agreguje různé datové typy v rámci jednoho dokumentu JSON nebo XML.
- Podle sloupců báze ukládají data do sloupce dle vašeho výběru.
- Databáze grafů vytvářejí hrany a vlastnosti uzlů, které představují datové prvky.
Databáze klíč-hodnota
Databáze klíč-hodnota, někdy označované jako úložiště klíč-hodnota, používají nejjednodušší datový model – párování klíče a hodnoty. Aplikace získá hodnotu pomocí jedinečného klíče.
Hodnota může obsahovat libovolnou datovou strukturu nebo typ. Je na aplikaci, která se snaží získat přístup k datům, aby pochopila obsah.
Příklady databází klíč–hodnota zahrnují Redis, Riak , Aerospike a Oracle NoSQL .
Sloupcové databáze
Sloupcové databáze se zaměřují na efektivitu operací čtení. Pokud potřebujete rychle přečíst několik sloupců z více řádků, má smysl uspořádat data do skupin sloupců (tj. rodin sloupců).
Struktura modelu se skládá z identifikátoru řádku která definuje agregovaná data a agregaci řádků, která se skládá z podrobnějších hodnot sekundární úrovně (tj. sloupců ).
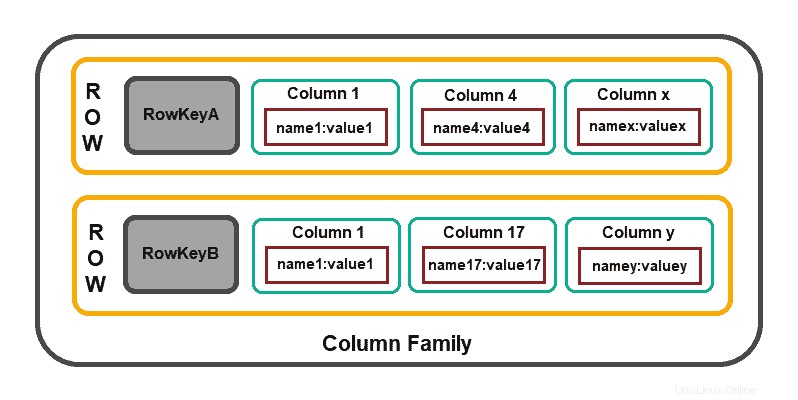
Cassandra , HBase , Amazon DynamoDB a Clickhouse , jsou některá z široce používaných řešení založených na sloupcích.
Databáze dokumentů
Databáze dokumentů ukládají částečně strukturovaná data v dokumentech pomocí formátů JSON, BSON, XML nebo jiných. Data uvnitř dokumentu jsou polostrukturovaná, aby poskytovala větší flexibilitu při dotazování. Na rozdíl od základních úložišť klíč–hodnota uživatel nemusí načítat celý záznam, ale pouze relevantní část dokumentu.

Tento datový model těží z webových dokumentů, uživatelských komentářů a aplikací pro publikování na webu. Známé NoSQL založené na dokumentech jsou MongoDB , OrientDB , Apache CouchDB a MarkLogic .
Databáze grafů
Databáze grafů organizují data do uzlů, přičemž Edge vytváří vztahy mezi těmito datovými uzly.
Tento model ukládání dat se ukázal jako užitečný v aplikacích, které kladou důraz na vztahy, jako jsou platformy sociálních médií, software pro vztahy se zákazníky a cestovní a rezervační systémy.
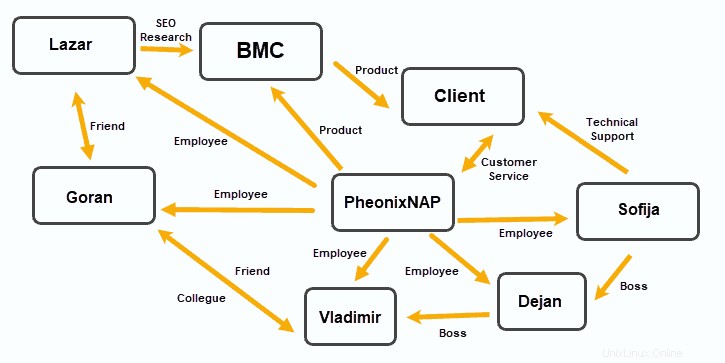
OrientDB a MarkLogic založené na dokumentech mohou fungovat jako databáze grafů. JanusGraph , RedisGraph a Neo4j jsou populární řešení založená na grafech.
Výhody NoSQL
- Výkon – Databáze NoSQL nabízejí lepší výkon v případech použití, které se zabývají daty, která nejsou vysoce relační. NoSQL očekává denormalizované schéma a podle toho optimalizuje čtení.
- Flexibilita – Dynamické schéma NoSQL usnadňuje ukládání nestrukturovaných dat optimálními způsoby pro konkrétní případ. Umožňuje vytváření dokumentu bez definování jeho struktury.
- Škálovatelnost – I když je možné vertikálně škálovat RDBMS upgradem paměti, úložiště nebo výpočetního výkonu stroje, NoSQL má další výhodu horizontálního škálování. To znamená, že je možné zvládnout nárůst provozu upgradem databáze o další servery.
Kdy použít NoSQL?
Pokoušet se použít jediné databázové řešení pro každý možný scénář není dobrý nápad. Různé typy databází uvedené v tomto článku jsou navrženy tak, aby se vypořádaly se specifickými problémy s daty. To není omezeno na databáze NoSQL. Dokonce i relační databáze se potýkají se standardizací různých datových typů do striktního schématu.
Vnitřní fungování relačních databází je dobře zdokumentováno a předvídatelné. Jazyk SQL a sada nástrojů vytvořených pomocí relačních technologií jsou všudypřítomné a zkušení zaměstnanci jsou snadno k dispozici. Model relační databáze vám umožňuje přistupovat k datům mnoha různými a kreativními způsoby, aniž byste se omezovali tím, jak jsou data uložena.
Velká data
Velká data a hodnota zachycení co největšího množství z nich technicky možného nejsou vhodnou zátěží pro relační model. Databáze NoSQL, která nepoužívá striktní schéma, je vynikající volbou pro ukládání velkého množství různorodých a nestrukturovaných dat.
Vývoj softwaru
Vývoj aplikací dramaticky těžil z NoSQL databází. Mnoho drahocenných hodin vývojářů bylo promarněno mapováním dat mezi datovými strukturami v paměti a relační databází. NoSQL databáze znamená, že si vytvoříte svůj model, takový, který je přizpůsobený potřebám aplikace, která k němu přistupuje, a případně snižuje požadované množství kódování.
Pokud databáze nemá schéma, znamená to, že aplikace přistupující k datům je musí mít. To se může rychle stát problémem, pokud více než jedna aplikace vyvinutá nezávisle na sobě potřebuje přístup ke stejné databázi.
Nekonzistence při čtení jsou nakonec vyřešeny, ale nedostatek konzistence při zápisech je vážný problém. Tento problém se často řeší omezením všech databázových interakcí v rámci jedné aplikace a její integrací s jinými aplikacemi pomocí webových služeb. Toto řešení dobře souvisí s obecným trendem využívat webové služby pro účely integrace.