Úvod
Databáze NoSQL nám umožňují ukládat obrovské množství dat a přistupovat k nim kdykoli, z jakéhokoli místa a zařízení. Je však obtížné rozhodnout, která technika datového modelování je pro vaše potřeby nejvhodnější. Naštěstí pro každý případ použití existuje technika modelování dat.
V tomto tutoriálu se budeme zabývat všemi různými technikami modelování dat NoSQL, které můžete použít při vytváření databáze NoSQL.

Co je datový model NoSQL?
NoSQL nebo ‚Not Only SQL‘ je datový model, který se výrazně liší od tradičních očekávání SQL.
Primární rozdíl je v tom, že NoSQL nepoužívá techniku relačního datového modelování a klade důraz na flexibilní design. Neexistence požadavků na schéma činí navrhování mnohem jednodušším a levnějším procesem. To neznamená, že nemůžete použít schéma úplně, ale spíše je návrh schématu velmi flexibilní.
Další užitečnou vlastností datových modelů NoSQL je, že jsou navrženy pro vysokou efektivitu a rychlost, pokud jde o vytváření až milionů dotazů za sekundu. Toho je dosaženo tím, že všechna data jsou obsažena v jedné tabulce, takže JOINS a křížové odkazy nejsou tak náročné na výkon.
NoSQL je unikátní také tím, že je horizontálně škálovatelné , ve srovnání s SQL, který je pouze vertikálně škálovatelný. S NoSQL můžete jednoduše použít jiný shard, který je levný, než kupovat další hardware, což není.
Čtyři typy databází NoSQL
Obecně řečeno, existují čtyři různé typy NoSQL databází, na kterých jsou založeny desítky datových modelů:
Obchod Key-Value
Úložiště párů klíč–hodnota, vytvořené speciálně pro požadavky na vysoký výkon a pravděpodobně jeden z nejběžnějších datových modelů, používají k ukládání dat hodnoty klíče s ukazateli.
Tento ukazatel je jedinečný a odkazuje přímo na určitou informaci, kterou může být cokoliv, co byste chtěli. Pokud chcete, můžete dokonce jako klíč hodnoty použít prázdný řetězec, ačkoli existují horní limity velikosti hodnoty v závislosti na databázi.
Zajímavé je, že to byl Amazon, kdo původně pomohl rozjet tento datový model a používá ho pro DynamoDB. Vzhledem k tomu, že jsou jedním z největších online tržišť na světě, můžete vidět, jak výkonný tento datový model může být.
Obchod založený na dokumentech
U SQL bývají XML a JSON svázány, což zpomaluje dotazy a brzdí celý proces. Vzhledem k tomu, že NoSQL nepoužívá relační model, nemusí to dělat, což je místo, kde přicházejí na řadu úložiště dokumentů.
Všechna data jsou uložena v jedné tabulce, takže není třeba křížových odkazů a informace se místo ukládání do tabulky ukládají do dokumentu. I když je to velmi podobné úložišti klíč-hodnota a může být někdy považováno za jeho zastřešení, rozdíl je v tom, že NoSQL založené na dokumentech má obecně nějakou formu kódování, jako je XML.
Existuje databáze NoSQL specifická pro XML, která používá úložiště dokumentů. Ve skutečnosti Strider CD používá MongoDB jako podpůrný obchod.
Obchod založený na sloupcích
Tento typ datového modelu ukládá informace spíše do sloupců než do řádků, což je u SQL obvyklejší. Data se ukládají do sloupců, které jsou seskupeny do rodin a tyto rodiny se dále seskupují do více sloupců. To v podstatě vytváří téměř neomezený datový model seskupování sloupců.
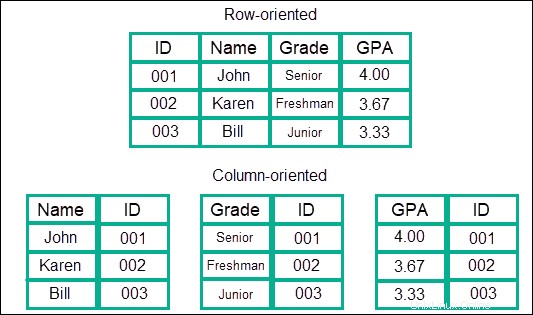
Výhodou je, že nabízí neuvěřitelně vysoké rychlosti ve srovnání s jinými modely nebo NoSQL, pokud jde o vyhledávání. S daty se zachází jako s jedním souvislým záznamem, a proto není potřeba přeskakovat přes řádky nebo různé oblasti, kde jsou informace uloženy.
Obchod založený na grafech
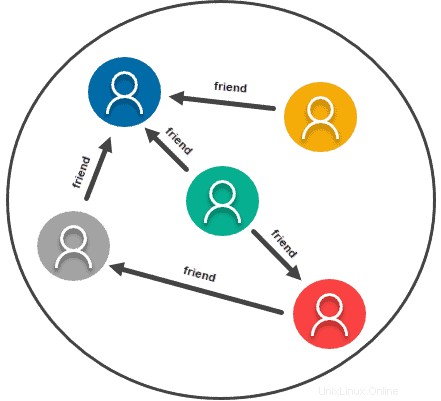
Grafové nebo síťové datové modely v podstatě považují vztah mezi jakýmikoli dvěma informacemi za stejně důležitý jako informace samotné. Jako takový je tento typ datového modelu skutečně vytvořen pro jakoukoli informaci, kterou byste obvykle představovali v grafu. Využívá vztahy a uzly, přičemž data jsou samotnou informací a vztah se vytváří mezi uzly.
Jak jsou data uložena v NoSQL?
Ukládání dat NoSQL závisí na tom, jaký typ databáze používáte. Protože NoSQL nevyžaduje schéma, neexistuje žádný plán, jak by měla být data uložena, a proto se liší mezi databázemi.
Obecně existují dva způsoby, jak úložiště dat NoSQL funguje:
- Na disku pomocíB-Stromů , přičemž horní část je trvale v paměti RAM.
- In-memory, kde je vše na RAM pomocí RB-Stromů a cokoli uloženého na disku je pouze příloha.
Návrh schématu pro NoSQL
Vzhledem k tomu, že databáze NoSQL ve skutečnosti nemají stanovenou strukturu, vývoj a návrh schémat se zaměřují na fyzický datový model. To znamená vývoj pro velká, horizontálně rozsáhlá prostředí, v čem NoSQL vyniká. Proto jsou v popředí specifické zvláštnosti a problémy, které přináší škálovatelnost.
Prvním krokem je tedy definování obchodních požadavků, protože optimalizace přístupu k datům je nutností a lze jí dosáhnout pouze tehdy, když budeme vědět, co firma chce co dělat s daty. Váš návrh schématu by měl doplňovat pracovní postupy spojené s vaším případem použití.
Existuje několik způsobů, jak vybrat primární klíč, a nakonec to závisí na samotných uživatelích. Jak již bylo řečeno, některá data mohou naznačovat efektivnější schéma, zejména pokud jde o to, jak často jsou tato data dotazována.
Techniky datového modelování NoSQL
Všechny techniky modelování dat NoSQL jsou seskupeny do tří hlavních skupin:
- Koncepční techniky
- Obecné techniky modelování
- Techniky modelování hierarchie
Níže stručně probereme všechny techniky modelování dat NoSQL.
Koncepční techniky
Existují tři koncepční techniky pro modelování dat NoSQL:
- Denormalizace . Denormalizace je docela běžná technika a zahrnuje kopírování dat do více tabulek nebo formulářů za účelem jejich zjednodušení. Pomocí denormalizace snadno seskupte všechna data, která je třeba dotazovat, na jednom místě. To samozřejmě znamená, že objem dat se pro různé parametry zvyšuje, což značně zvyšuje objem dat.
- Souhrny . To umožňuje uživatelům vytvářet vnořené entity se složitými vnitřními strukturami a také měnit jejich konkrétní strukturu. V konečném důsledku agregace redukuje spojení tím, že minimalizuje vztahy jedna ku jedné.
Většina datových modelů NoSQL má nějakou formu této techniky měkkého schématu. Například databáze úložišť grafů a klíč-hodnota mají hodnoty, které mohou mít jakýkoli formát, protože tyto datové modely nekladou na hodnotu žádná omezení. Podobně další příklad, jako je BigTable, má agregaci prostřednictvím sloupců a rodin sloupců. - Připojení na straně aplikace. NoSQL obvykle nepodporuje spojení, protože databáze NoSQL jsou orientované na otázky, kde se spojení provádějí během návrhu. To je porovnáno s relačními databázemi, kde se provádějí při provádění dotazu. To má samozřejmě tendenci vést k penalizaci za výkon a někdy je to nevyhnutelné.
Obecné techniky modelování
Existuje pět obecných technik pro modelování dat NoSQL:
- Vyčíslitelné klíče . Z velké části jsou neuspořádané hodnoty klíčů velmi užitečné, protože položky lze rozdělit na několik vyhrazených serverů pouhým hashováním klíče. I tak je přidání určité formy funkcí řazení pomocí uspořádaných klíčů užitečné, i když to může přidat trochu složitější a zvýšit výkon.
- Snížení rozměrů . Geografické informační systémy mají tendenci používat R-Strom indexy a je třeba je aktualizovat na místě, což může být drahé, pokud se jedná o velké objemy dat. Dalším tradičním přístupem je zploštit 2D strukturu do prostého seznamu, jako je to, co se dělá s Geohash.
Pomocí redukce rozměrů můžete mapovat vícerozměrná data na jednoduché modely klíč–hodnota nebo dokonce na vícerozměrné modely.
Použijte redukci dimenzionality k mapování vícerozměrných dat na model klíč-hodnota nebo na jiný nemultidimenzionální model. - Tabulka indexů. S indexovou tabulkou využijte výhod indexů v obchodech, které je nutně interně nepodporují. Snažte se vytvořit a poté udržovat jedinečnou tabulku s klíči, které se řídí specifickým přístupovým vzorem. Například hlavní tabulka pro ukládání uživatelských účtů pro přístup podle ID uživatele.
- Složený index klíče . I když je to poněkud generická technika, složené klíče jsou neuvěřitelně užitečné, když se používají uspořádané klíče. Pokud jej vezmete a zkombinujete se sekundárními klíči, můžete vytvořit vícerozměrný index, který je velmi podobný výše uvedené technice redukce rozměrů.
- Invertované vyhledávání – přímá agregace. Koncept této techniky spočívá v použití indexu, který splňuje specifickou sadu kritérií, ale poté tato data agregovat s úplnými skeny nebo nějakou formou originální reprezentace.
Jedná se spíše o model zpracování dat než o modelování dat, přesto jsou datové modely jistě ovlivněny použitím tohoto typu vzoru zpracování. Vezměte v úvahu, že náhodné vyhledávání záznamů vyžadovaných pro tuto techniku je neefektivní. Ke zmírnění tohoto problému použijte zpracování dotazů v dávkách.
Techniky modelování hierarchie
Existuje sedm technik modelování hierarchie pro data NoSQL:
- Agregace stromů. Stromová agregace je v podstatě modelování dat jako jediného dokumentu. To může být opravdu efektivní, pokud jde o jakýkoli záznam, který je vždy přístupný najednou, jako je vlákno na Twitteru nebo příspěvek na Redditu. Problémem pak samozřejmě nastává, že náhodný přístup k jakémukoli jednotlivému záznamu je neefektivní.
- Seznamy sousedství. Jedná se o přímou techniku, kde jsou uzly modelovány jako nezávislé záznamy polí s přímými předky. To je složitý způsob, jak říci, že vám umožňuje vyhledávat uzly podle jejich rodičů nebo dětí. Stejně jako stromová agregace je však také docela neefektivní pro načtení celého podstromu pro jakýkoli daný uzel.
- Materializované cesty. Tato technika je druh denormalizace a používá se k zamezení rekurzivních procházení ve stromových strukturách. Ke každému uzlu chceme především přiřadit rodiče nebo děti, což nám pomáhá určit případné předchůdce nebo potomky uzlu bez obav z procházení. Mimochodem, materializované cesty můžeme uložit jako ID, buď jako sadu nebo jeden řetězec.
- Vnořené sady . Standardní technika pro stromové struktury v relačních databázích, je stejně tak použitelná pro NoSQL a databáze klíč-hodnota nebo databáze dokumentů. Cílem je uložit listy stromu jako pole a poté namapovat každý nelistový uzel na rozsah listů pomocí počátečních/koncových indexů.
Modelování tímto způsobem je efektivní způsob, jak se vypořádat s neměnnými daty, protože vyžaduje pouze malé množství paměti a nemusí nutně používat procházení. Jak již bylo řečeno, aktualizace jsou drahé, protože vyžadují aktualizace indexů. - Sloučení vnořených dokumentů:Názvy číselných polí. Většina vyhledávačů má tendenci pracovat s dokumenty, které jsou plochým seznamem polí a hodnot, spíše než s něčím se složitou vnitřní strukturou. Jako taková se tato technika datového modelování pokouší zmapovat tyto složité struktury na prostý dokument, například mapování dokumentů s hierarchickou strukturou, což je běžný problém, se kterým se můžete setkat.
Tento typ práce je samozřejmě bolestivý a není snadno škálovatelný, zvláště když se vnořené struktury zvětšují. - Sloučení vnořených dokumentů:Dotazy na blízkost. Jedním ze způsobů, jak vyřešit potenciální problémy s technikou modelování dat číslovaných názvů polí, je použití podobné techniky zvané Dotazy na blízkost. Ty omezují vzdálenost mezi slovy v dokumentu, což pomáhá zvýšit výkon a snížit dopad na rychlost dotazu.
- Dávkové zpracování grafů. Dávkové zpracování grafů je skvělá technika pro zkoumání vztahů nahoru nebo dolů pro uzel v několika krocích. Je to drahý proces a nemusí se nutně velmi dobře škálovat. Pomocí Message Passing a MapReduce můžeme provést tento typ zpracování grafu.