
V tomto tutoriálu vám ukážeme, jak nainstalovat Apache Hadoop na CentOS 7. Pro ty z vás, kteří nevěděli, Apache Hadoop je open-source softwarový framework napsaný v Javě pro distribuované úložiště a distribuční procesy, zpracovává velmi velké soubory dat tím, že je distribuuje mezi počítačové clustery. Spíše než se spoléhat na hardware při poskytování vysoké dostupnosti, je samotná knihovna navržena tak, aby detekovala a řešila selhání na aplikační vrstvě, takže poskytuje vysoce -dostupná služba nad shlukem počítačů, z nichž každý může být náchylný k selhání.
Tento článek předpokládá, že máte alespoň základní znalosti Linuxu, víte, jak používat shell, a co je nejdůležitější, hostujete své stránky na vlastním VPS. Instalace je poměrně jednoduchá. ukázat vám krok za krokem instalaci Apache Hadoop na CentOS 7.
Předpoklady
- Server s jedním z následujících operačních systémů:CentOS 7.
- Abyste předešli případným problémům, doporučujeme použít novou instalaci operačního systému.
- Přístup SSH k serveru (nebo stačí otevřít Terminál, pokud jste na počítači).
non-root sudo usernebo přístup kroot user. Doporučujeme jednat jakonon-root sudo user, protože však můžete poškodit svůj systém, pokud nebudete při jednání jako root opatrní.
Nainstalujte Apache Hadoop na CentOS 7
Krok 1. Nainstalujte Javu.
Vzhledem k tomu, že Hadoop je založen na Javě, ujistěte se, že máte v systému nainstalovanou Java JDK. Pokud v systému Java nainstalovanou nemáte, použijte následující odkaz jej nejprve nainstalujte.
- Nainstalujte Java JDK 8 na CentOS 7
root@idroot.us ~# java -version java version "1.8.0_45" Java(TM) SE Runtime Environment (build 1.8.0_45-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
Krok 2. Nainstalujte Apache Hadoop.
Pro konfiguraci apache Hadoop se doporučuje vytvořit normálního uživatele, vytvořte uživatele pomocí následujícího příkazu:
useradd hadoop passwd hadoop
Po vytvoření uživatele je také nutné nastavit klíčový ssh pro jeho vlastní účet. K tomu použijte následující příkazy:
su - hadoop ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
Stáhněte si nejnovější stabilní verzi Apache Hadoop, v době psaní tohoto článku je to verze 2.7.0:
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.0/hadoop-2.7.0.tar.gz tar xzf hadoop-2.7.0.tar.gz mv hadoop-2.7.0 hadoop
Krok 3. Nakonfigurujte Apache Hadoop.
Nastavte proměnné prostředí používané Hadoopem. Upravte soubor ~/.bashrc a na konec souboru připojte následující hodnoty:
export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Použití proměnných prostředí na aktuálně běžící relaci:
source ~/.bashrc
Nyní upravte $HADOOP_HOME/etc/hadoop/hadoop-env.sh soubor a nastavte proměnnou prostředí JAVA_HOME:
export JAVA_HOME=/usr/jdk1.8.0_45/
Hadoop má mnoho konfiguračních souborů, které je třeba nakonfigurovat podle požadavků vaší infrastruktury Hadoop. Začněme s konfigurací základním nastavením clusteru Hadoop s jedním uzlem:
cd $HADOOP_HOME/etc/hadoop
Upravit core-site.xml :
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
Upravit hdfs-site.xml :
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hadoopdata/hdfs/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hadoopdata/hdfs/datanode</value> </property> </configuration>
Upravit mapred-site.xml :
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Upravit yarn-site.xml :
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
Nyní naformátujte namenode pomocí následujícího příkazu, nezapomeňte zkontrolovat adresář úložiště:
hdfs namenode -format
Spusťte všechny služby Hadoop pomocí následujícího příkazu:
cd $HADOOP_HOME/sbin/ start-dfs.sh start-yarn.sh
Pro kontrolu, zda jsou všechny služby spuštěny dobře, použijte ‘jps ‘ příkaz:
jps
Krok 4. Přístup k Apache Hadoop.
Apache Hadoop bude ve výchozím nastavení k dispozici na portu HTTP 8088 a portu 50070. Otevřete svůj oblíbený prohlížeč a přejděte na http://your-domain.com:50070 nebo http://server-ip:50070 . Pokud používáte bránu firewall, otevřete porty 8088 a 50070, abyste umožnili přístup k ovládacímu panelu.
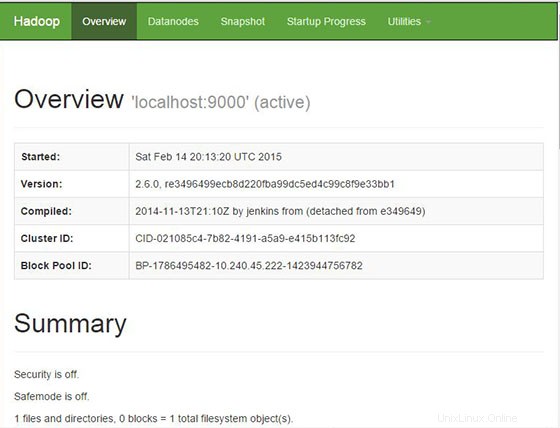
Nyní přejděte na port 8088 pro získání informací o clusteru a všech aplikacích:
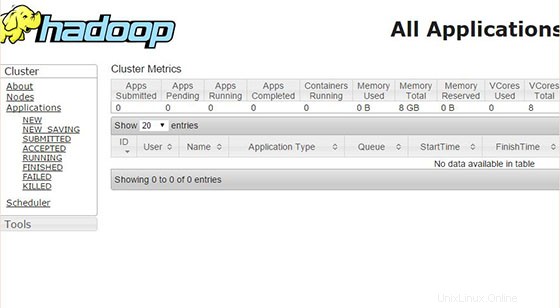
Blahopřejeme! Úspěšně jste nainstalovali Apache Hadoop. Děkujeme, že jste použili tento návod k instalaci Apache Hadoop na systém CentOS 7. Pro další pomoc nebo užitečné informace vám doporučujeme navštívit oficiální web Apache Hadoop.