Úl je Datový sklad model v Hadoop Ekosystém. Může fungovat jako nástroj ETL nad Hadoop . Povolení vysoké dostupnosti (HA) na Hive není podobné jako u hlavních služeb, jako je Namenode a Resource Manager.
V Hive nedojde k automatickému převzetí služeb při selhání (Hiveserver2 ). Pokud existuje Hiveserver2 (HS2 ) selže, spuštěné úlohy na tom se nezdařily HS2 selže. Musíme úlohu znovu odeslat, aby mohla být spuštěna na jiném HiveServer2 . Povolení HA na HS2 není nic jiného než zvýšení počtu HS2 komponenty v Clusteru .
V tomto článku se podíváme na kroky k instalaci a povolení Vysoká dostupnost z Hive .
Požadavky
- Osvědčené postupy pro nasazení serveru Hadoop na CentOS/RHEL 7 – část 1
- Nastavení předpokladů Hadoop a posílení zabezpečení – část 2
- Jak nainstalovat a nakonfigurovat Cloudera Manager na CentOS/RHEL 7 – část 3
- Jak nainstalovat CDH a nakonfigurovat umístění služeb na CentOS/RHEL 7 – část 4
- Jak nastavit vysokou dostupnost pro Namenode – část 5
- Jak nastavit vysokou dostupnost pro Správce zdrojů – část 6
Začněme…
Instalace a konfigurace podregistru
1. Přihlaste se do Cloudera Manager na níže uvedené adrese URL a přejděte do Cloudera Manager –> Přidat službu .
http://13.233.129.39:7180/cmf/home
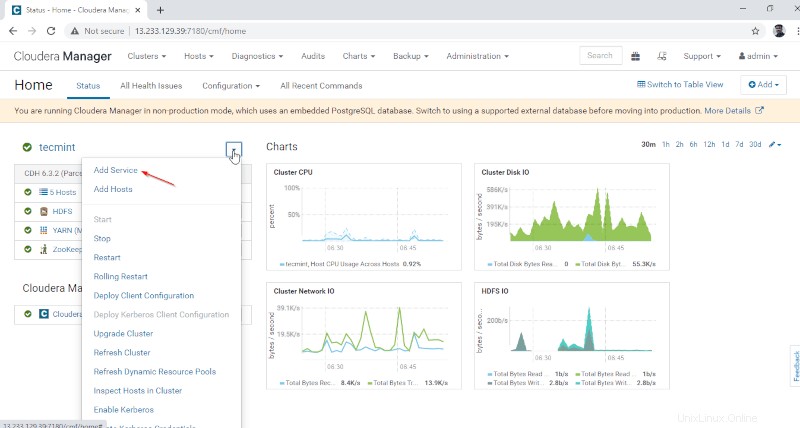
2. Vyberte službu „Hive ‘.
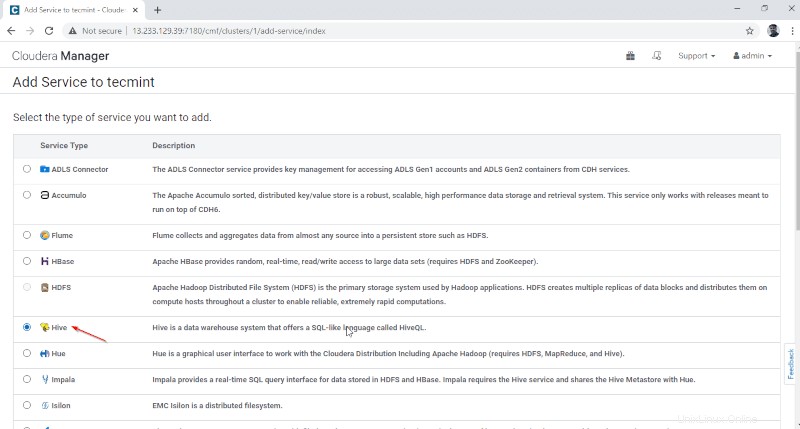
3. Přiřaďte služby uzlům.
- Brána – Je to klientská služba, kde má uživatel přístup k Hive. Obvykle bude tato služba umístěna v Edge uzly věnované uživatelům.
- Hive Metastore – Jedná se o centrální úložiště pro ukládání metadat Hive.
- Server WebHCat – Jedná se o webové rozhraní API pro HCatalog a další služby Hadoop.
- Hiveserver2 – Jedná se o rozhraní klientů pro provádění dotazů na Hive.
Po výběru serverů klikněte na tlačítko Pokračovat ‘ pokračovat.
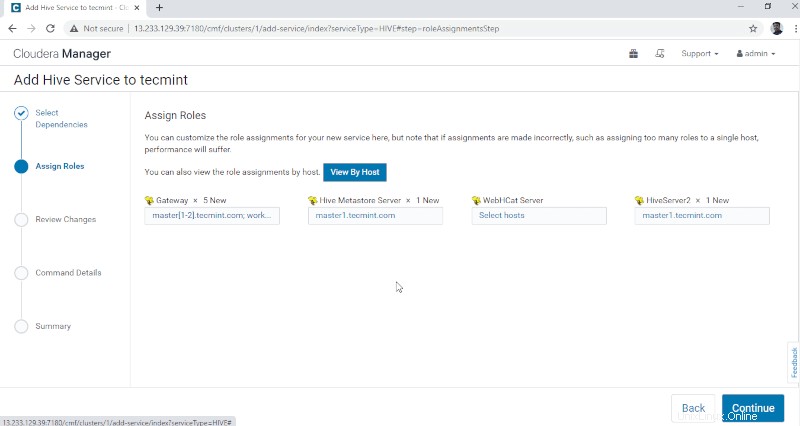
4. Hive Metastore potřebuje podkladovou databázi pro ukládání metadat. Zde používáme výchozí PostgreSQL databáze, která je integrována pomocí CDH .
Níže uvedené údaje o databázi budou automaticky zadány, ‘Test připojení “ bude přeskočen, protože zmíněná databáze bude vytvořena za běhu. V reálném čase potřebujeme vytvořit databázi v externí databázi a otestovat připojení, abychom mohli pokračovat dále. Po dokončení klikněte na tlačítko Pokračovat '.
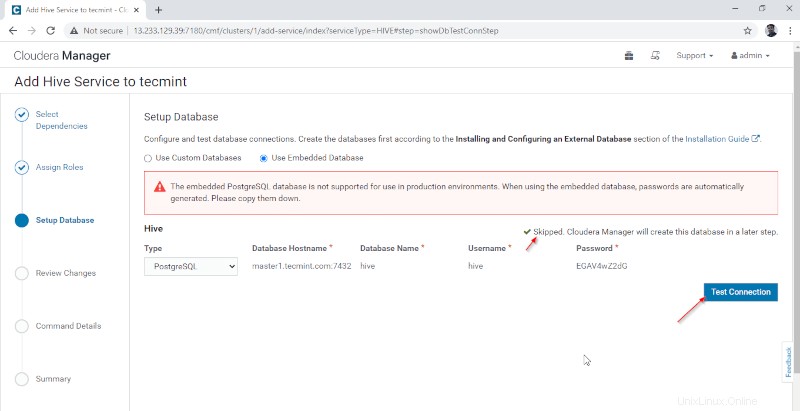
5. Nakonfigurujte Hive Warehouse adresář, /user/hive/sklad je výchozí cesta k adresáři pro ukládání tabulek Hive. Klikněte na tlačítko Pokračovat '.
6. Instalace Hive je spuštěna.
7. Po dokončení instalace můžete získat „Dokončeno stav. Klikněte na tlačítko Pokračovat “ pokračovat dále.
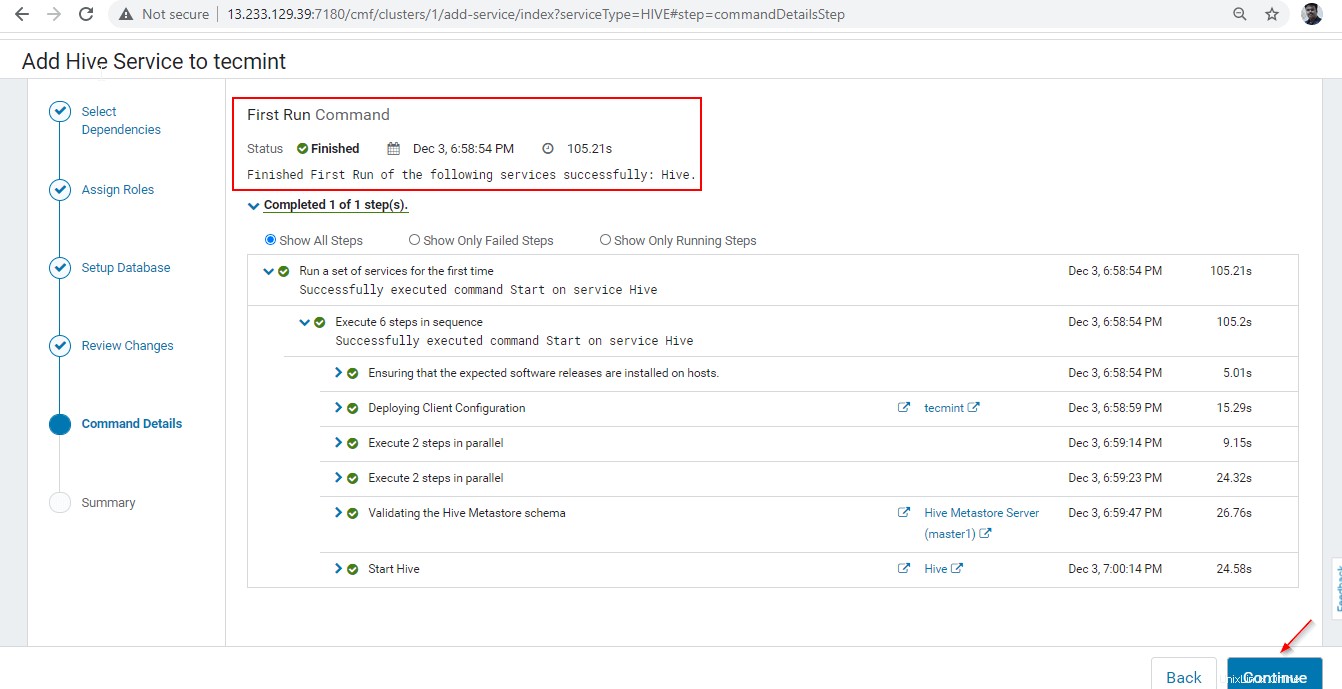
8. Instalace a konfigurace podregistru byly úspěšně dokončeny. Klikněte na tlačítko Dokončit ‘ pro dokončení instalační procedury.
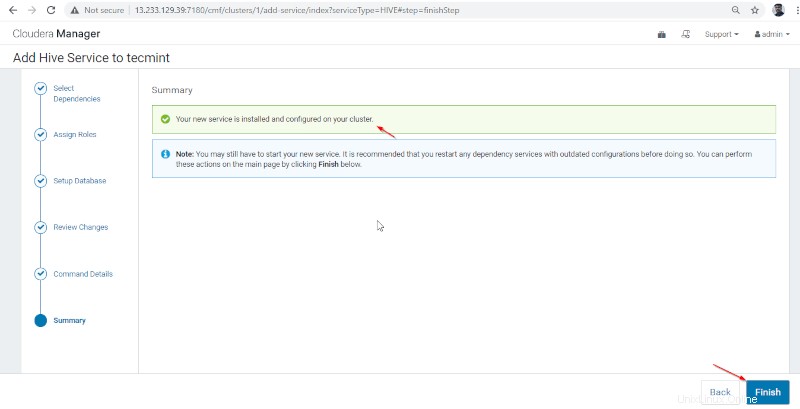
9. Můžete vidět Hive služba přidána do Clusteru prostřednictvím Cloudera Manager Dashboard .
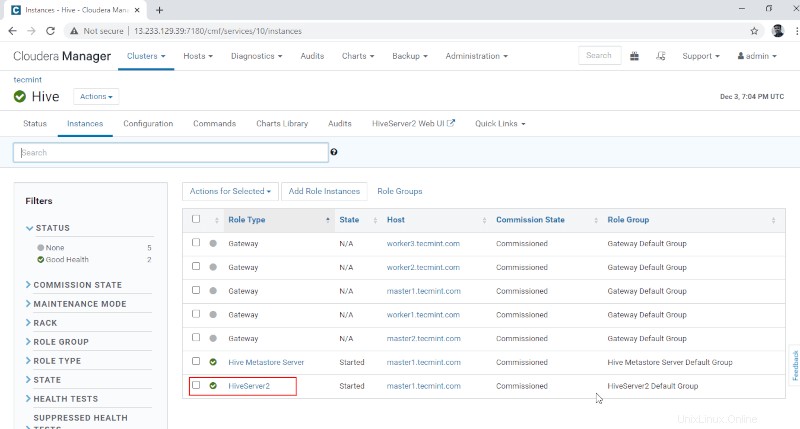
10. Můžete zobrazit Hiveserver2 v Instance z Hive . Přidali jsme Hiveserver2 v master1 .
Správce Cloudera –> Úl –> Instance –> Hiveserver2 .
Povolení vysoké dostupnosti v Hive
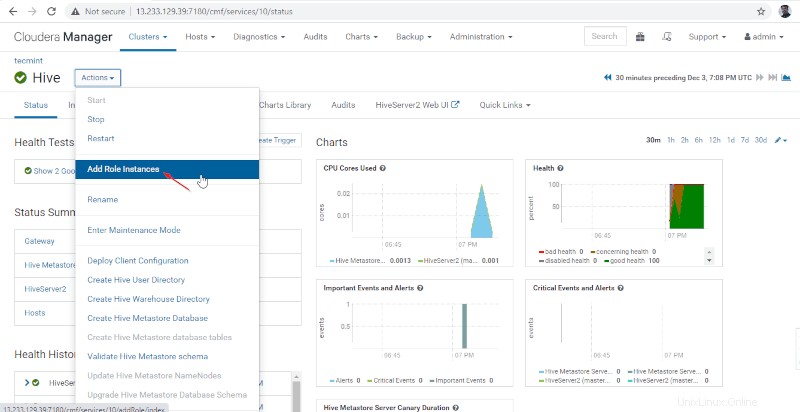
11. Poté přidejte roli Hive tak, že přejdete do Cloudera Manager –> Úl –> Akce –> Přidat roli Instance.
12. Vyberte servery, kam chcete umístit další Hiveserver2 . Můžete přidat více než dva, není limit. Zde přidáváme jeden extra Hiveserver2 v master2 .
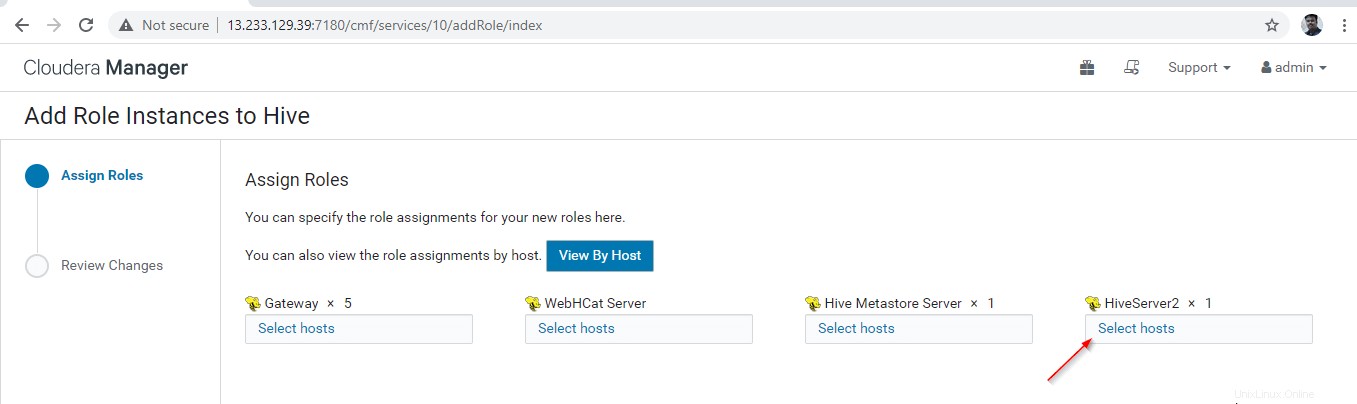
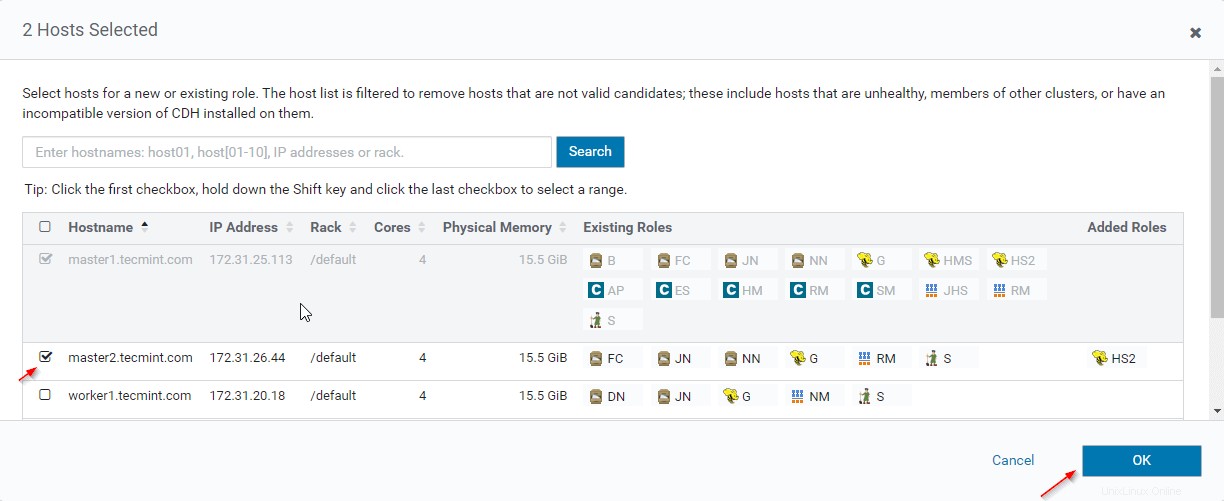
13. Po výběru serveru klikněte na tlačítko Pokračovat '.
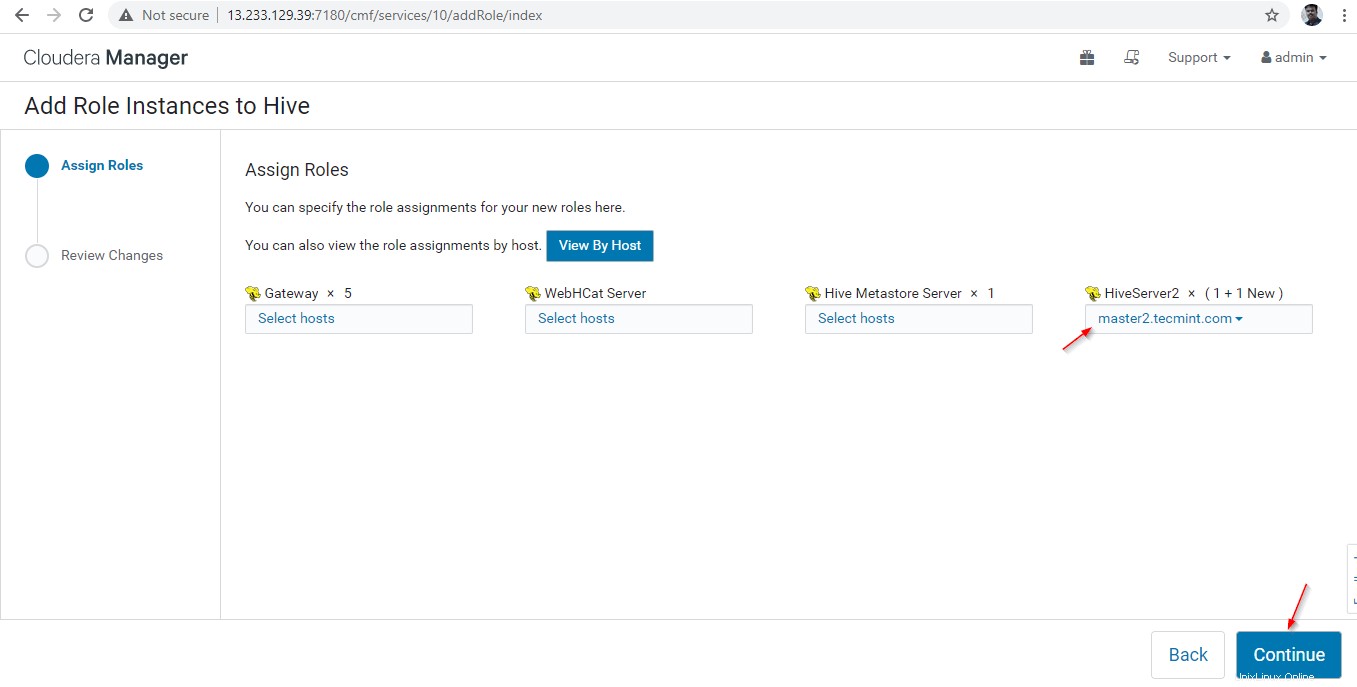
14. Hiverserver2 bude přidáno do Instancí úlu , musíte jej spustit přechodem do Cloudera Manager –> Úl –> Instance –> (Vyberte Hiveserver2 nově přidáno) –> Akce pro vybrané –> Start .
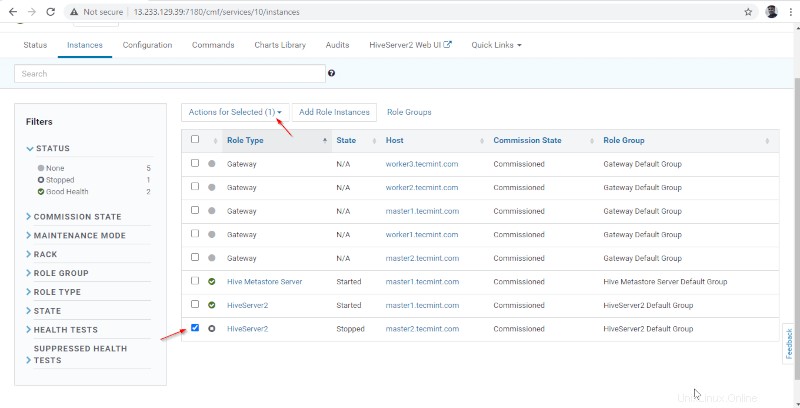
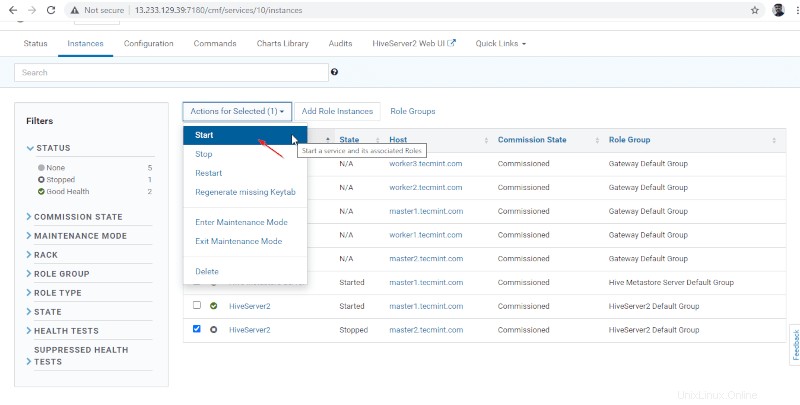
15. Jednou Hiveserver2 začalo na master2 , získáte stav „Dokončeno '. Klikněte na Zavřít .
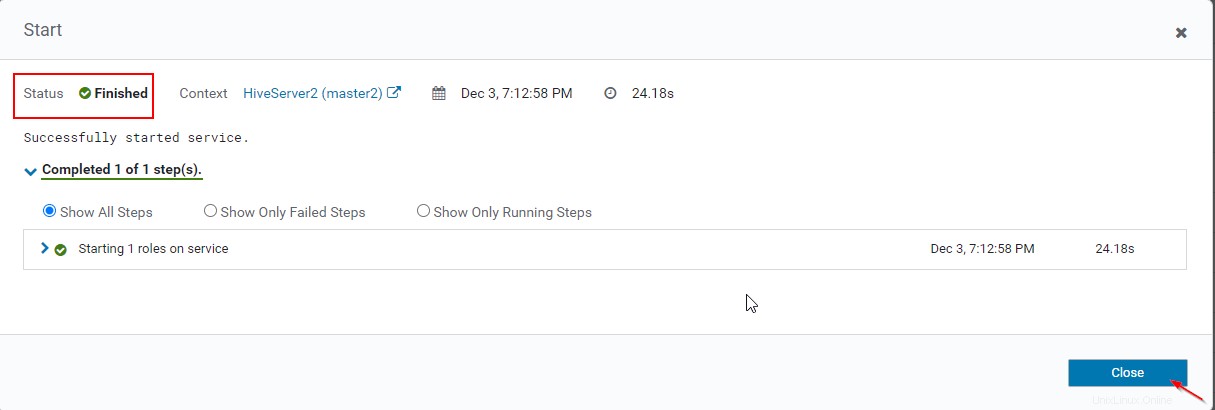
16. Můžete zobrazit oba Hiveserver2 běží.
Ověření dostupnosti úlu
Můžeme připojit Hiveserver2 přes beeline, což je tenký klient a příkazový řádek. K navázání spojení používá ovladač JDBC.
17. Přihlaste se k serveru, kde Hive Gateway běží.
[[email protected] ~]$ beeline

18. Zadejte JDBC připojovací řetězec pro připojení Hiveserver2 . V této souvislosti řetězec zmiňujeme Hiverserver2 (master2 ) s výchozím číslem portu 10000 . Tento připojovací řetězec se připojí pouze k Hiveserver2 který běží na master2 .
beeline> !connect "jdbc:hive2://master1.tecmint.com:10000"
19. Spusťte ukázkový dotaz.
0: jdbc:hive2://master1.tecmint.com:10000> show databases;
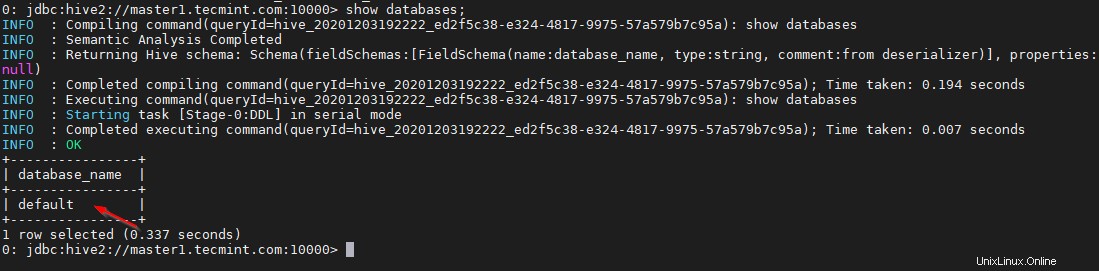
Toto je výchozí databáze, která je integrována.
20. Pomocí níže uvedeného příkazu ukončete relaci Hive.
0: jdbc:hive2://master1.tecmint.com:10000> !quit

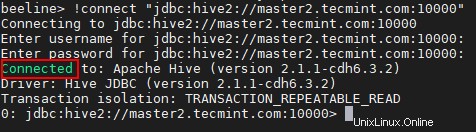
21. Stejným způsobem můžete připojit Hiveserver2 běží na master2 .
beeline> !connect "jdbc:hive2://master2.tecmint.com:10000"
23. Můžeme připojit Hiveserver2 v Zookeeper Discovery režimu. V této metodě nemusíme zmiňovat Hiveserver2 v připojovacím řetězci místo toho používáme Zookeeper a objevíte dostupný Hiveserver2 .
Zde můžeme použít nástroj pro vyrovnávání zátěže třetí strany k vyrovnání zátěže mezi dostupnými Hiverserver2 . Pro aktivaci režimu zjišťování Zookeeper je potřeba níže uvedená konfigurace přejděte do Správce Cloudera –> Úl –> Konfigurace .
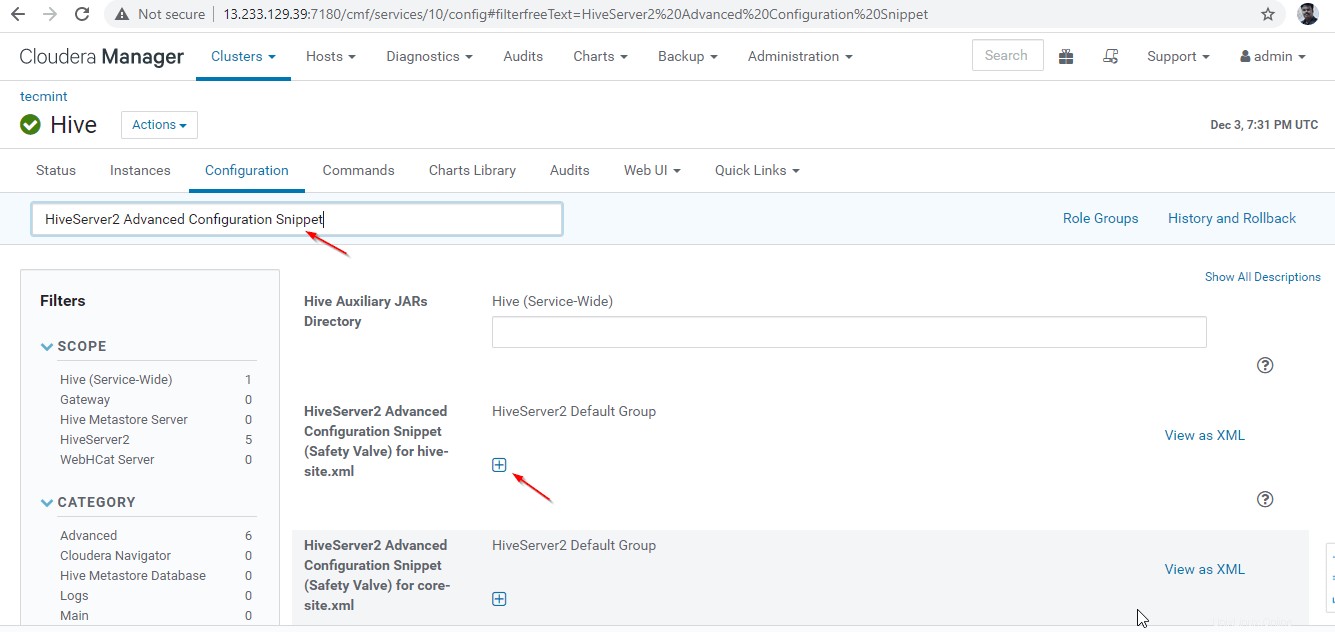
24. Dále vyhledejte vlastnost „Úryvek pokročilé konfigurace HiveServer2 ” a klikněte na + symbol pro přidání níže uvedené vlastnosti.
Name : hive.server2.support.dynamic.service.discovery Value : true Description : <any description>
25. Po zadání vlastnosti klikněte na „Uložit změny '.
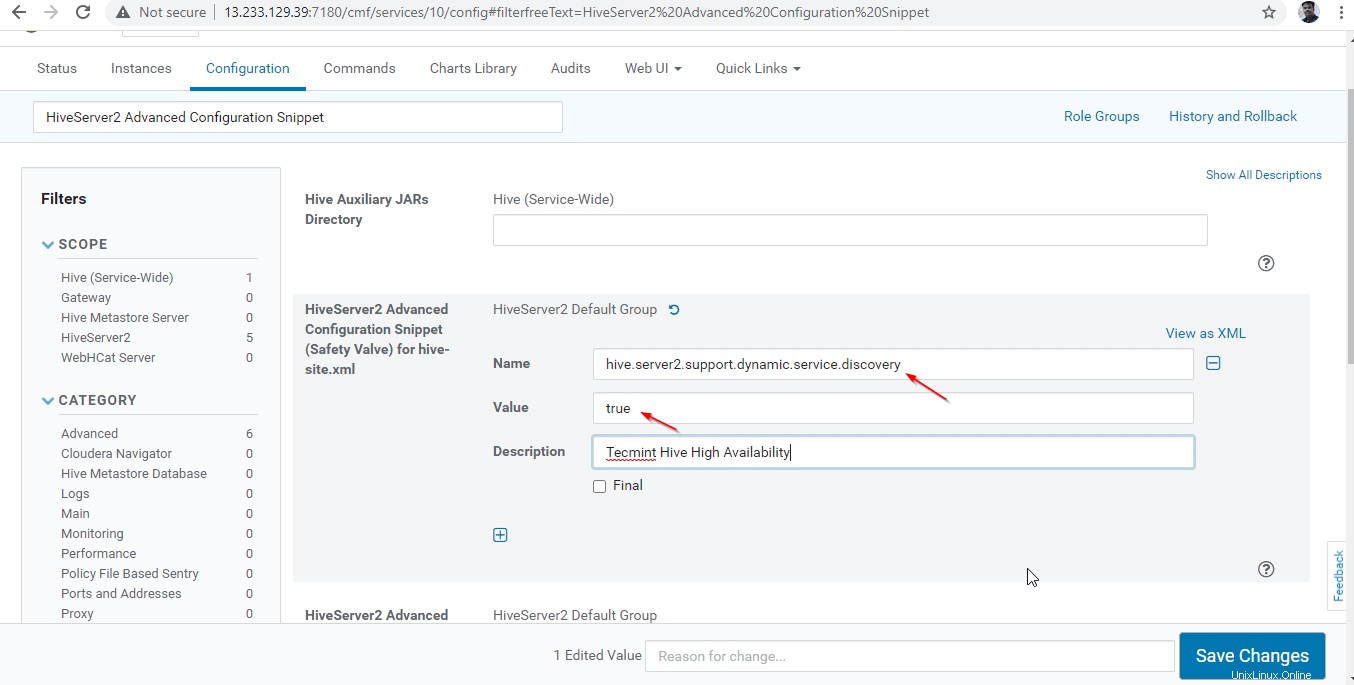
26. Když jsme provedli změny v konfiguraci, je třeba restartovat dotčené služby kliknutím na symbol oranžové barvy.
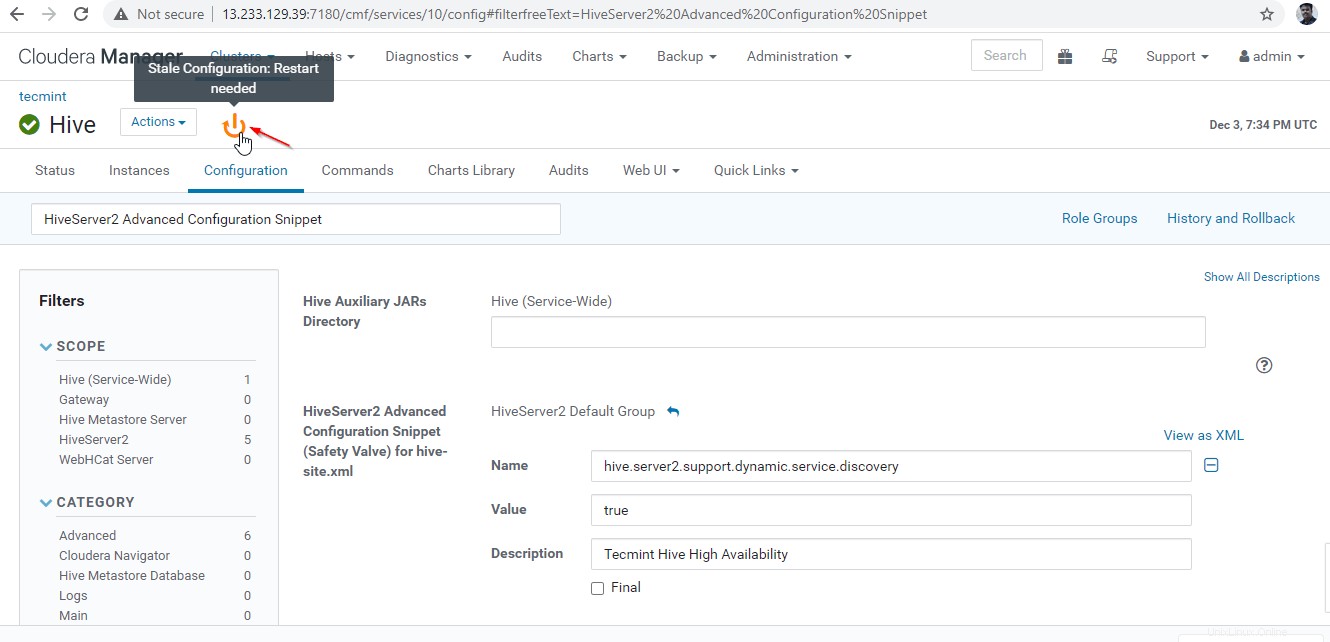
27. Klikněte na „Restartovat zastaralou verzi „služby.
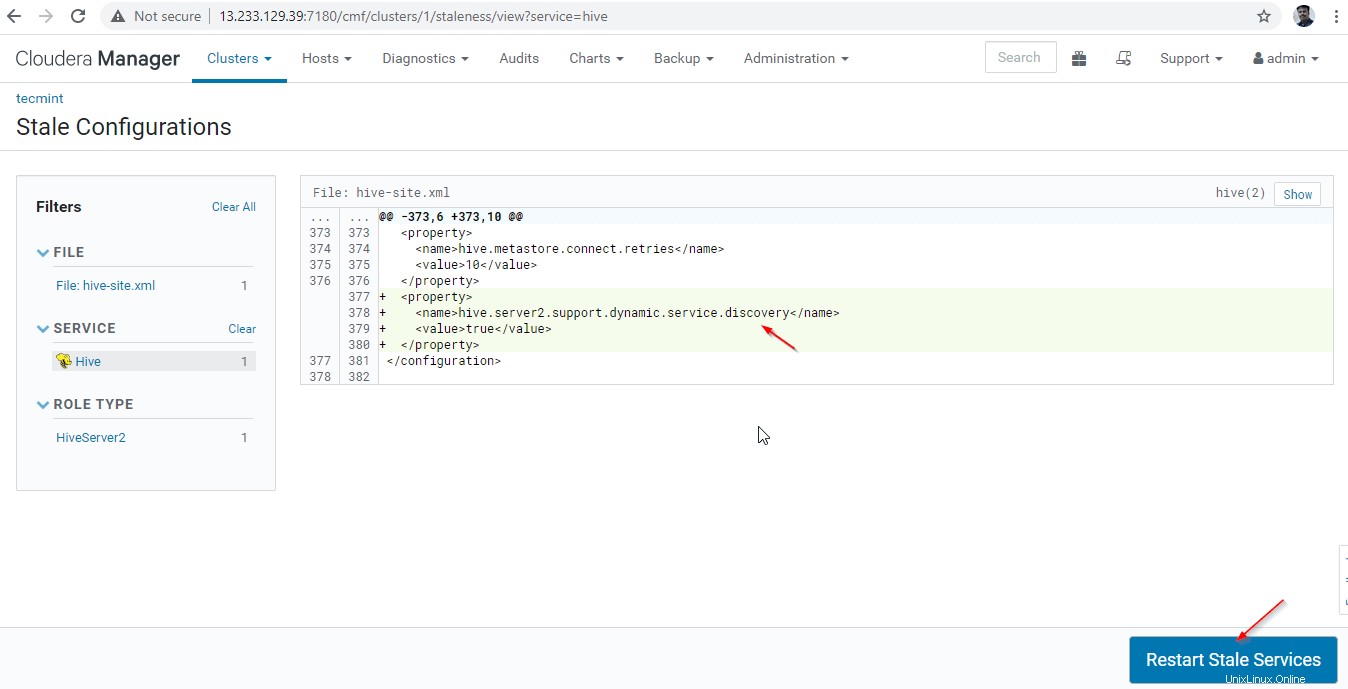
28. K dispozici jsou dvě možnosti. Pokud je cluster v živé produkci, musíme upřednostnit postupný restart, abychom minimalizovali výpadek. Při nové instalaci můžeme zvolit druhou možnost ‘Znovu nasadit konfiguraci klienta “ a klikněte na „Restartovat nyní '.
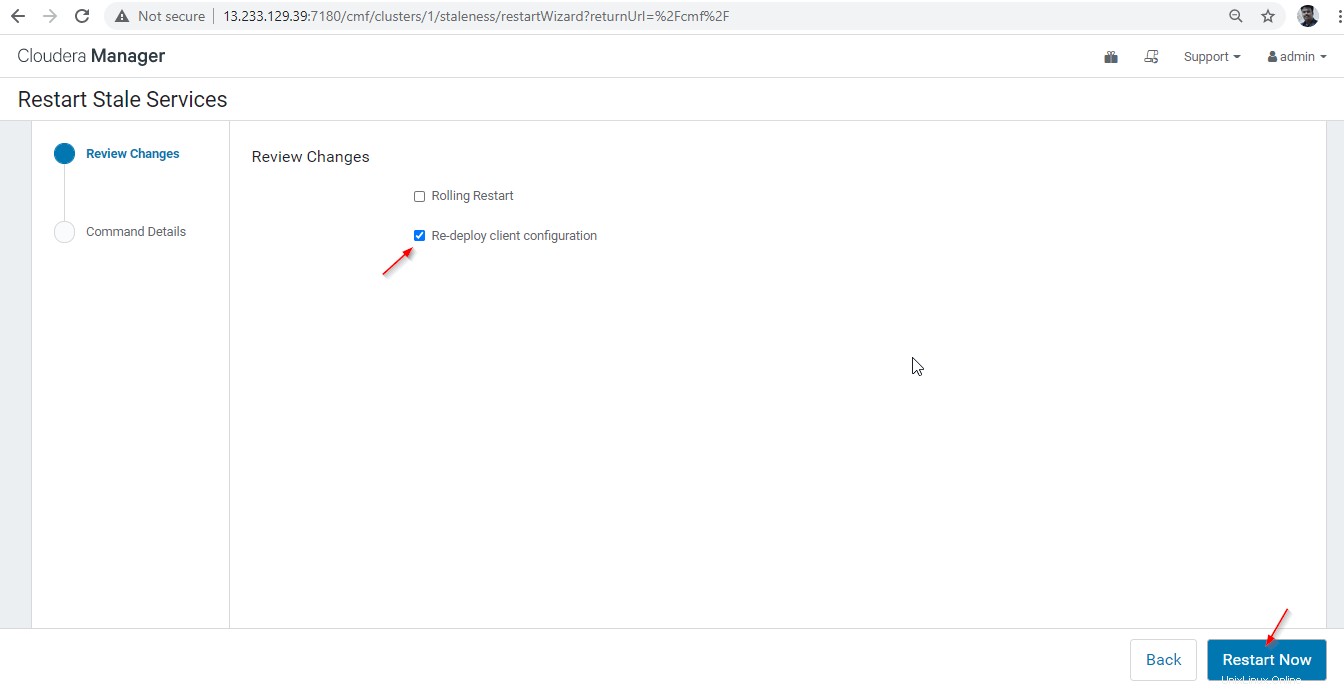
29. Po úspěšném restartování se zobrazí stav „Dokončeno '. Klikněte na tlačítko Dokončit “ k dokončení procesu.
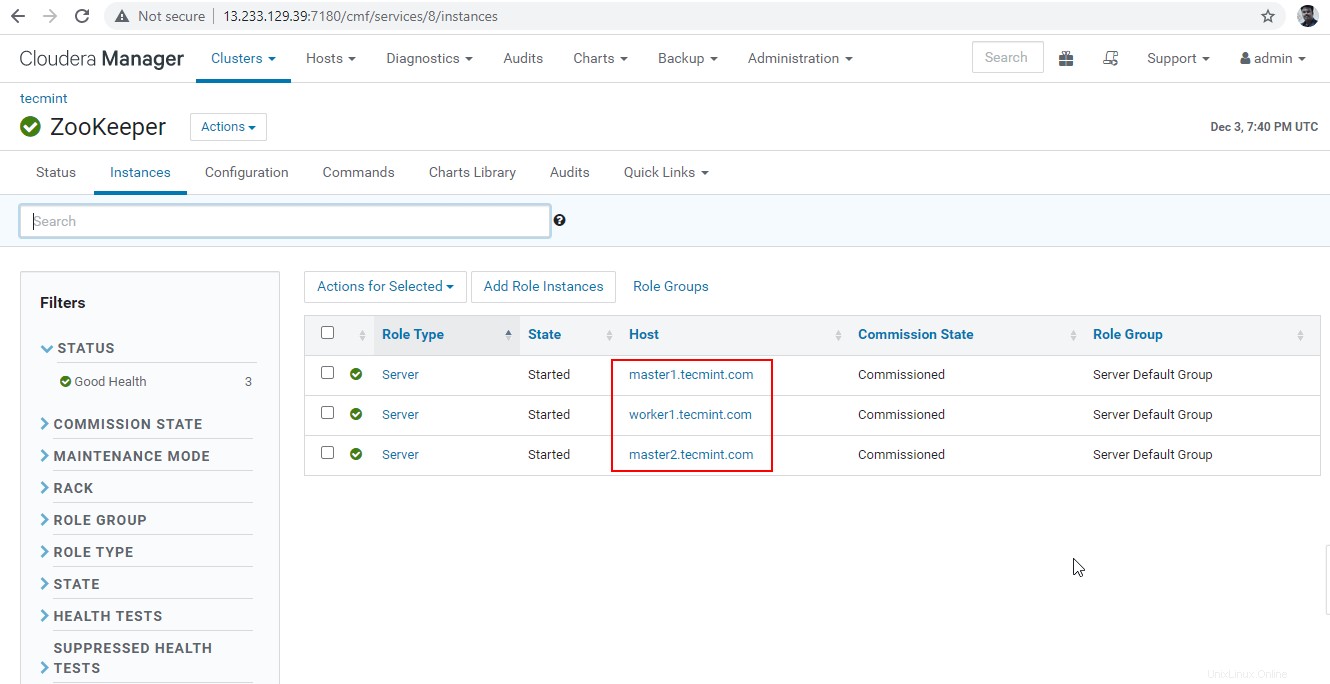
30. Nyní připojíme Hiveserver2 pomocí Zookeeper Discovery režimu. V JDBC připojení, řetězec, který potřebujeme k použití Zookeeper servery s číslem portu 2081 . Shromážděte servery Zookeeper tím, že přejdete do Cloudera Manager –> Správce zoo –> Instance –> (Poznamenejte si názvy serverů).
Toto jsou tři servery, které mají Zookeeper, 2181 je číslo portu.
master1.tecmint.com:2181 master2.tecmint.com:2181 worker1.tecmint.com:2181
31. Nyní přejděte beeline .
[[email protected] ~]$ beeline

32. Zadejte JDBC připojovací řetězec, jak je uvedeno níže. Musíme zmínit Režim zjišťování služby a Jmenný prostor Zookeeper . „hiveserver2 ’ je výchozí jmenný prostor Hiveserver2.
beeline>!connect "jdbc:hive2://master1.tecmint.com:2181,master2.tecmint.com:2181,worker1.tecmint.com:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2"

33. Nyní je relace připojena k Hiveserver2 běží na master1 . Spusťte vzorový dotaz k ověření. Pomocí níže uvedeného příkazu vytvořte databázi.
0: jdbc:hive2://master1.tecmint.com:2181,mast> create database tecmint;

34. Pro výpis databáze použijte níže uvedený příkaz.
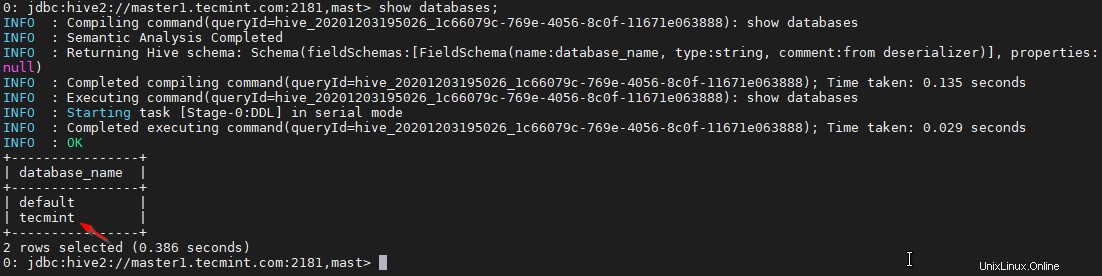
0: jdbc:hive2://master1.tecmint.com:2181,mast> show databases;
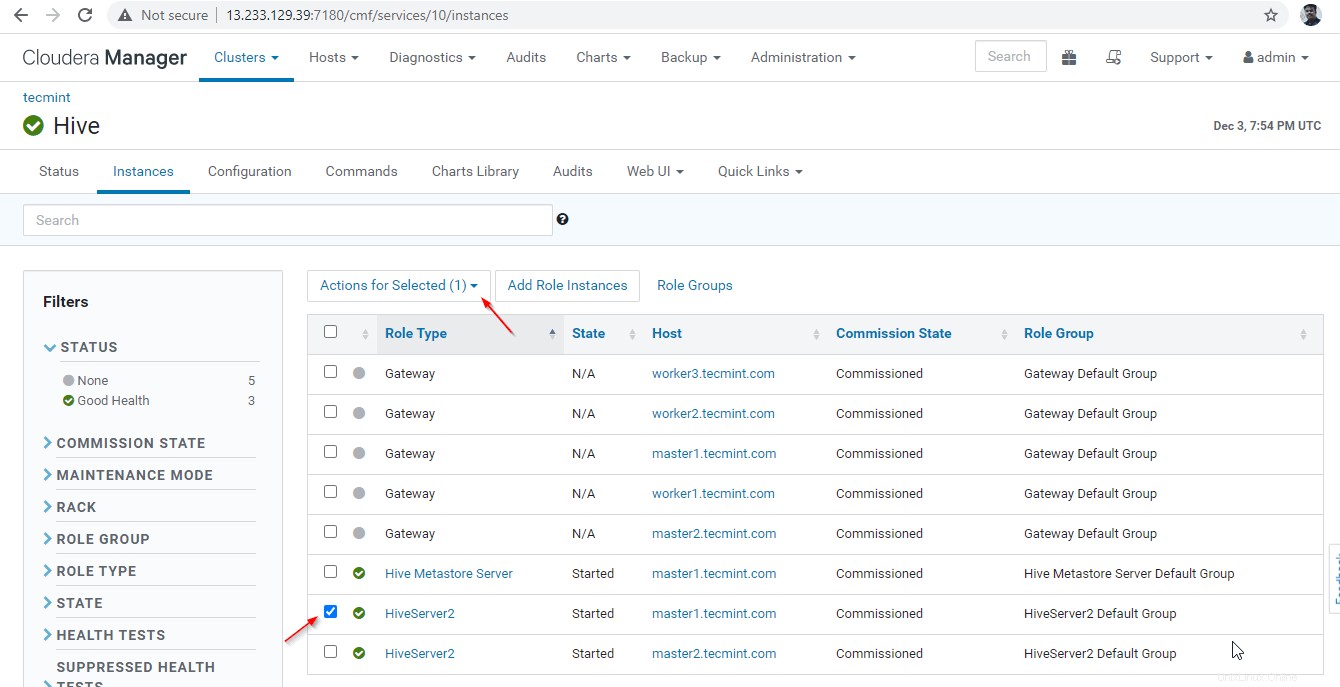
35. Nyní ověříme vysokou dostupnost v režimu zjišťování Zookeeper . Přejděte do Cloudera Manager a zastavte Hiveserver2 na master1 které jsme testovali výše.
Správce Cloudera –> Úl –> Instance –> (vyberte Hiveserver2 na master1 ) –> Akce pro vybrané –> Zastavit .
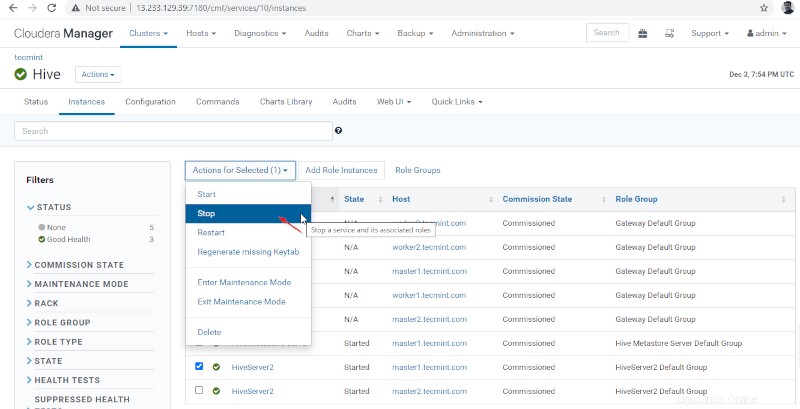
36. Klikněte na tlačítko Stop '. Po zastavení získáte stav „Dokončeno '. Ověřte Hiveserver2 na master1 přechodem do Hive –> Instance .
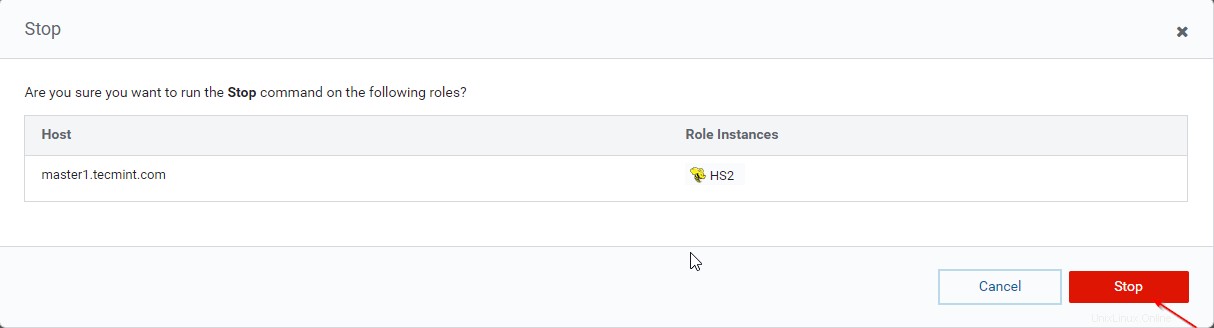
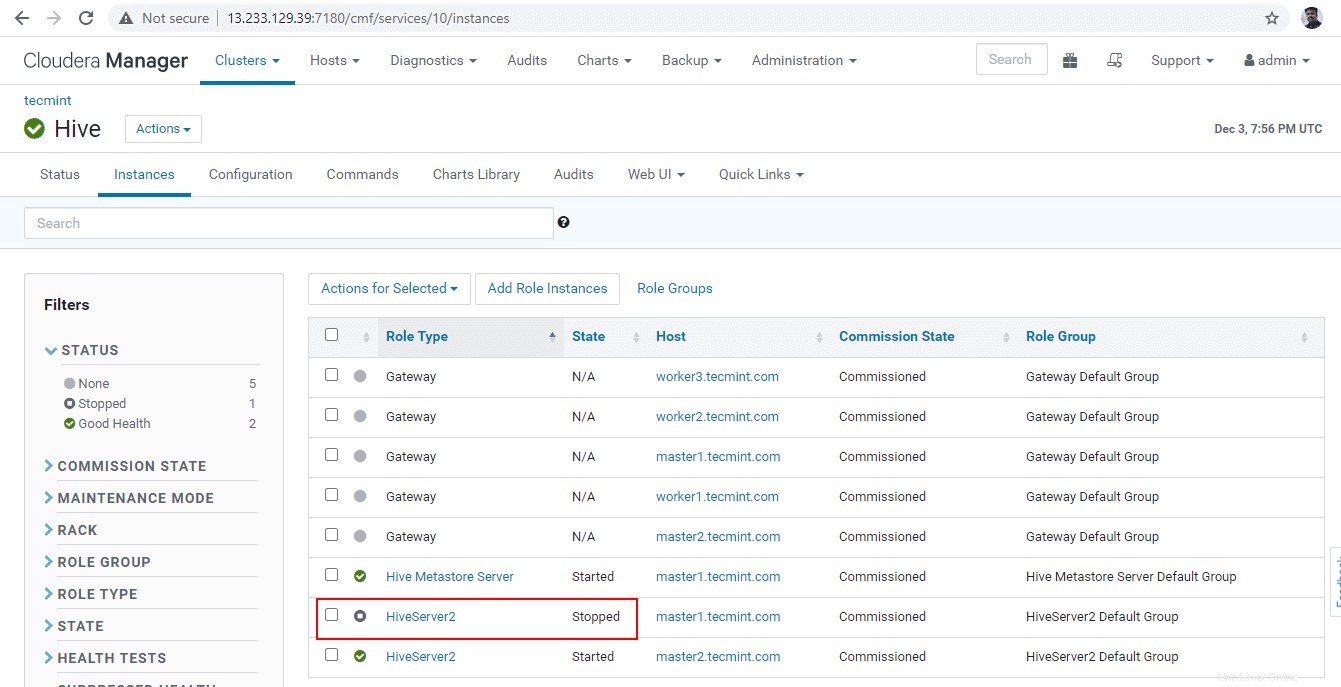
37. Dostaňte se rychlou linkou a připojte Hiveserver2 pomocí stejného JDBC připojovací řetězec s režimem zjišťování Zookeeper jak jsme to udělali ve výše uvedených krocích.
[[email protected] ~]$ beeline beeline>!connect "jdbc:hive2://master1.tecmint.com:2181,master2.tecmint.com:2181,worker1.tecmint.com:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2"

Nyní budete připojeni k Hiveserver2 běží na master2 .
38. Ověřte pomocí vzorového dotazu.
0: jdbc:hive2://master1.tecmint.com:2181,mast> show databases;
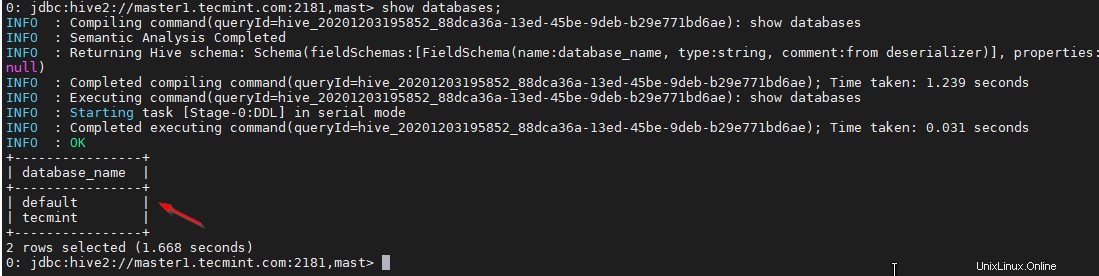
Závěr
V tomto článku jsme prošli podrobnými kroky k vytvoření Hive Data Warehouse model v našem Clusteru s Vysokou dostupností . V produkčním prostředí v reálném čase více než tři Hiveserver2 bude umístěn do režimu zjišťování Zookeeper povoleno.
Zde jsou všechny Hiveserver2 se registrují u Zookeeper pod společným jmenným prostorem . Správce zoo dynamicky zjistí dostupný Hiveserver2 a založí relaci Hive.