Když spustíme určité příkazy v Unixu/Linuxu pro čtení nebo úpravu textu z řetězce nebo souboru, většinou se snažíme filtrovat výstup do dané sekce zájmu. Zde je použití regulárních výrazů užitečné.
Čtěte také: 10 užitečných linuxových řetězových operátorů s praktickými příklady
Co jsou regulární výrazy?
Regulární výraz lze definovat jako řetězce, které představují několik posloupností znaků. Jednou z nejdůležitějších věcí na regulárních výrazech je to, že umožňují filtrovat výstup příkazu nebo souboru, upravovat část textového nebo konfiguračního souboru a tak dále.
Funkce regulárního výrazu
Regulární výrazy jsou tvořeny:
- Obyčejné znaky například mezera, podtržítko(_), A–Z, a–z, 0–9.
- Meta znaky které jsou rozšířeny na běžné postavy, zahrnují:
(.)odpovídá libovolnému jednotlivému znaku kromě nového řádku.(*)odpovídá nule nebo více existencím bezprostředního znaku, který mu předchází.[ character(s) ]odpovídá kterémukoli ze znaků uvedených ve znaku (znakech), lze také použít pomlčku(-)znamená rozsah znaků, jako je[a-f],[1-5], a tak dále.^odpovídá začátku řádku v souboru.$odpovídá konci řádku v souboru.\je to úniková postava.
Chcete-li text filtrovat, musíte použít nástroj pro filtrování textu, jako je awk . Můžete si představit awk jako vlastní programovací jazyk. Ale pro rozsah tohoto návodu k použití awk , pokryjeme jej jako jednoduchý nástroj pro filtrování příkazového řádku.
Obecná syntaxe awk je:
# awk 'script' filename
Kde 'script' je sada příkazů, kterým rozumí awk a jsou spouštěny v souboru, názvu souboru.
Funguje tak, že načte daný řádek v souboru, vytvoří kopii řádku a poté na řádku provede skript. To se opakuje na všech řádcích v souboru.
'script' je ve tvaru '/pattern/ action' kde vzor je regulární výraz a akce je to, co awk udělá, když najde daný vzor v řádku.
Jak používat Awk Filtering Tool v Linuxu
V následujících příkladech se zaměříme na meta znaky, o kterých jsme hovořili výše v rámci funkcí awk.
Jednoduchý příklad použití awk:
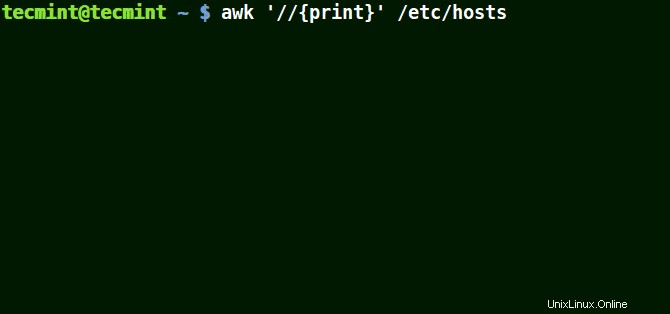
Níže uvedený příklad vytiskne všechny řádky v souboru /etc/hosts protože není dán žádný vzor.
# awk '//{print}'/etc/hosts

Použít Awk se vzorem:
V příkladu níže je vzor localhost bylo zadáno, takže awk bude odpovídat řádku s localhost v /etc/hosts soubor.
# awk '/localhost/{print}' /etc/hosts

Použití Awk se zástupným znakem (.) ve vzoru
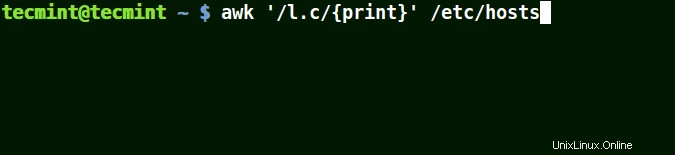
(.) bude odpovídat řetězcům obsahujícím loc , localhost , místní síť v příkladu níže.
To znamená * l some_single_character c * .
# awk '/l.c/{print}' /etc/hosts
Použití Awk se znakem (*) ve vzoru
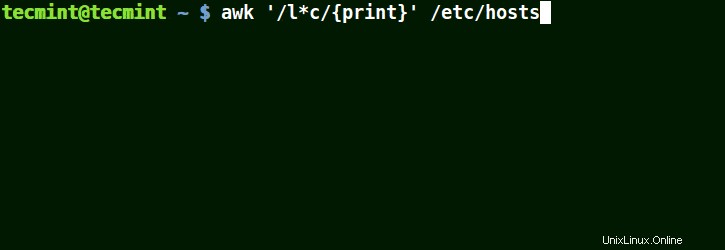
Bude odpovídat řetězcům obsahujícím localhost , místní síť , řádky , schopný , jako v příkladu níže:
# awk '/l*c/{print}' /etc/localhost
Také si uvědomíte, že (*) se pokusí získat co nejdelší shodu, kterou dokáže detekovat.
Podívejme se na případ, který to demonstruje, vezměte regulární výraz t*t což znamená shodu řetězců začínajících písmenem t a končí t v řádku níže:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint.
Při použití vzoru /t*t/ získáte následující možnosti :
this is t this is tecmint this is tecmint, where you get t this is tecmint, where you get the best good t this is tecmint, where you get the best good tutorials, how t this is tecmint, where you get the best good tutorials, how tos, guides, t this is tecmint, where you get the best good tutorials, how tos, guides, tecmint
A (*) v /t*t/ zástupný znak umožňuje awk vybrat poslední možnost:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint
Použití Awk se sadou [ znaků ]
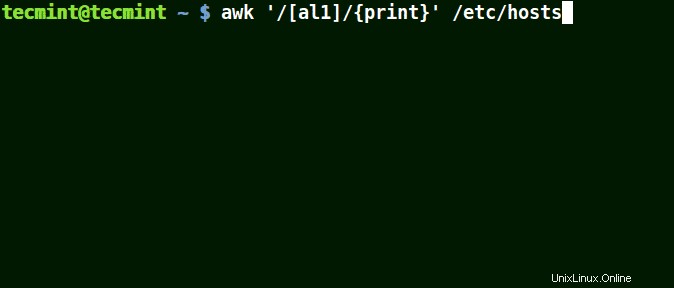
Vezměte si například sadu [al1] , zde awk bude odpovídat všem řetězcům obsahujícím znak a nebo l nebo 1 na řádku v souboru /etc/hosts .
# awk '/[al1]/{print}' /etc/hosts
Následující příklad odpovídá řetězcům začínajícím buď K nebo k následuje T :
# awk '/[Kk]T/{print}' /etc/hosts

Určení znaků v rozsahu
Pochopte znaky pomocí awk:
[0-9]znamená jediné číslo[a-z]znamená shodu s jedním malým písmenem[A-Z]znamená shodu s jedním velkým písmenem[a-zA-Z]znamená shodu s jedním písmenem[a-zA-Z 0-9]znamená shodu s jedním písmenem nebo číslem
Podívejme se na příklad níže:
# awk '/[0-9]/{print}' /etc/hosts
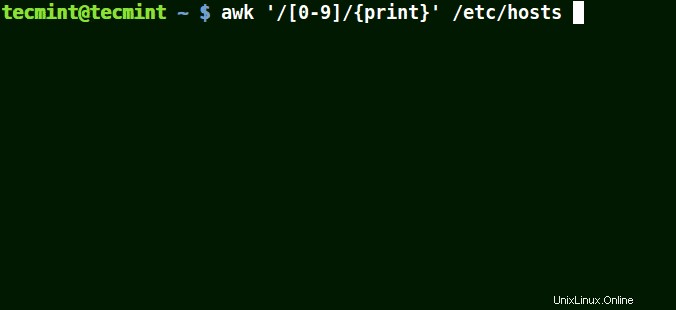
Celý řádek ze souboru /etc/hosts obsahovat alespoň jedno číslo [0-9] ve výše uvedeném příkladu.
Používejte Awk s (^) Meta Character
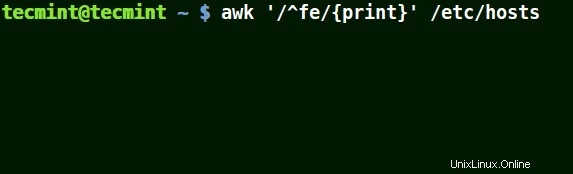
Odpovídá všem řádkům, které začínají vzorem poskytnutým jako v příkladu níže:
# awk '/^fe/{print}' /etc/hosts
# awk '/^ff/{print}' /etc/hosts
Používejte Awk s ($) metaznakem
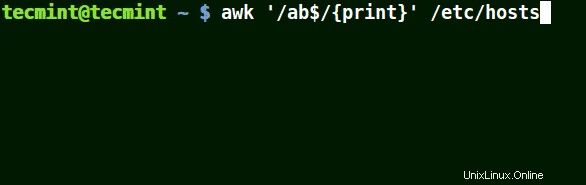
Odpovídá všem řádkům, které končí zadaným vzorem:
# awk '/ab$/{print}' /etc/hosts
# awk '/ost$/{print}' /etc/hosts
# awk '/rs$/{print}' /etc/hosts
Používejte Awk s (\) Escape znak
Umožňuje vám vzít postavu, která ji následuje, doslovně, to znamená považovat ji za takovou, jaká je.
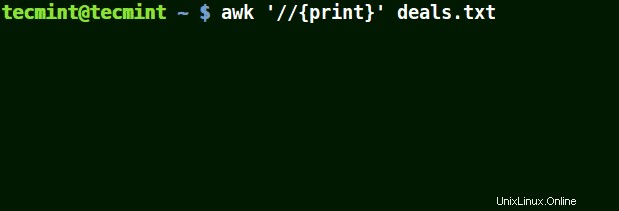
V níže uvedeném příkladu první příkaz vytiskne celý řádek v souboru, druhý příkaz nevytiskne nic, protože chci odpovídat řádku, který má 25,00 $ , ale není použit žádný znak escape.
Třetí příkaz je správný, protože ke čtení $ byl použit znak escape jak to je.
# awk '//{print}' deals.txt
# awk '/$25.00/{print}' deals.txt
# awk '/\$25.00/{print}' deals.txt
Shrnutí
To není vše s awk nástroj pro filtrování příkazového řádku, příklady výše a základní operace awk. V dalších dílech pokročíme v tom, jak používat komplexní funkce awk. Děkujeme za přečtení a za jakékoli doplnění nebo vysvětlení napište komentář do sekce komentářů.