Manipulace s řetězci je jedním ze základních konceptů ve skriptování bash. V programování jsou řetězce jedním z datových typů, které jsou uspořádanou posloupností znaků. Je důležité, abyste věděli, jak vytvářet a manipulovat s řetězci v bash. V této příručce se na jednoduchých příkladech naučíme manipulaci s řetězci ve skriptování shellu Bash. Na konci tohoto článku se vám bude pohodlně pracovat s bash strunami.
Přiřazení proměnných
Řetězce mohou být přiřazeny k proměnné a později použity ve skriptu pro další zpracování. Například vytvářím proměnnou s názvem "GREET_USER" a vytištění řetězce na terminál.
$ GREET_USER="Hello, Thanks for visiting OSTechnix"
$ echo "$GREET_USER"

Bash nemá žádný silný typový systém, takže pokud proměnné přiřadíte hodnotu, bude s ní zacházeno jako s řetězcovým typem. Můžete vytvářet řetězce s jednoduchými, dvojitými nebo žádnými uvozovkami.
V bash je rozdíl mezi jednoduchými a dvojitými uvozovkami. Jednoduché uvozovky zabraňují rozšiřování proměnných a příkazů, zatímco dvojité uvozovky to podporují. Podívejte se na níže uvedený příklad.
Vytvořil jsem další proměnnou s názvem "SITE_NAME" a používá se v "GREET_USER" variabilní. Ve dvojitých uvozovkách bude proměnná rozšířena a v jednoduchých uvozovkách proměnná nebude rozšířena.
$ SITE_NAME="OSTechnix"
## DOUBLE QUOTES
$ GREET_USER="Hello, Thanks for visiting ${SITE_NAME}"
$ echo "$GREET_USER" 
# SINGLE QUOTES
$ GREET_USER='Hello, Thanks for visiting ${SITE_NAME}'
$ echo "$GREET_USER"

Délka řetězce
Chcete-li zjistit délku řetězce, můžete použít # symbol. Zjištění délky řetězce bude užitečné v některých případech, kdy musíte napsat nějakou logiku založenou na počtu řetězců.
$ echo "${#SITE_NAME}" 
Převod řetězců na pole
Existuje mnoho způsobů, jak převést datový typ řetězce na typ pole. Nejjednodušším způsobem by bylo uzavřít řetězec do složených závorek.
$ ARR_TYPE=($GREET_USER)
$ echo ${ARR_TYPE[@]}
$ for element in ${ARR_TYPE[@]}; do
echo $element
done 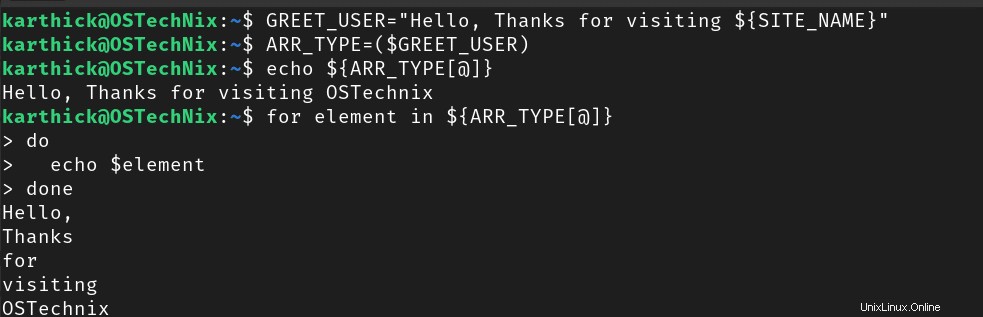
Druhou metodou by bylo rozdělit řetězec a uložit jej jako pole na základě oddělovače použitého v řetězci. V předchozím příkladu se jako oddělovač polí (IFS) používá mezera, což je výchozí IFS v bash. Pokud máte například řetězec oddělený čárkami, můžete nastavit IFS na čárku a vytvořit pole. Další podrobnosti o IFS naleznete v následující příručce:
- Bash Scripting – smyčka Zatímco a dokud není vysvětlena příklady
$ STR_TO_ARR="column1,column2,column3"
$ IFS=","
$ ARR=(${STR_TO_ARR})
$ for element in ${ARR[@]}; do echo $element; done
$ echo "${ARR[@]}" 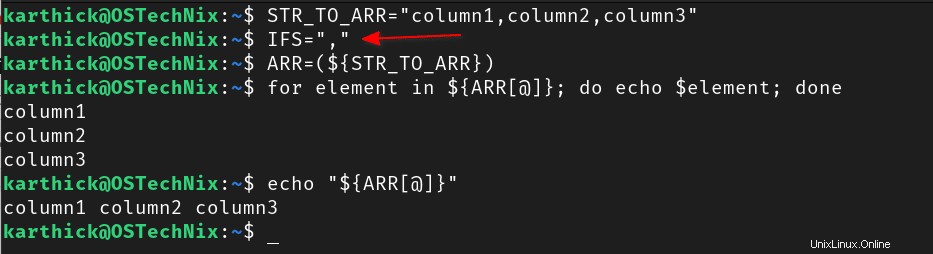
Konverze případu
Bash má vestavěnou podporu pro konverzi případu řetězce. Pro převod velkých a malých písmen, jak je znázorněno níže, musíte na konci řetězce použít některé speciální znaky.
# SPECIAL CHARACTERS ,, ==> Converts an entire string to lowercase ^^ ==> Converts an entire string to Uppercase ~~ ==> Transpose Case , ==> Converts first letter alone to lowercase ^ ==> Converts first letter alone to uppercase
# ---- LOWER TO UPPER CASE ----
$ L_TO_U="welcome to ostechnix"
$ echo ${L_TO_U^^}
# ---- UPPER TO LOWER CASE ----
$ U_TO_L="WELCOME TO OSTECHNIX"
$ echo ${L_TO_U,,}
# ---- TRANSPOSE CASE ----
$ TRS_CASE="Welcome To OsTechnix"
$ echo ${TRS_CASE~~}
# ---- FIRST LETTER TO LOWERCASE ----
$ F_TO_L="OSTECHNIX"
$ echo ${F_TO_L,}
# ---- FIRST LETTER TO UPPERCASE ----
$ F_TO_U="ostechnix"
$ echo ${F_TO_U^} 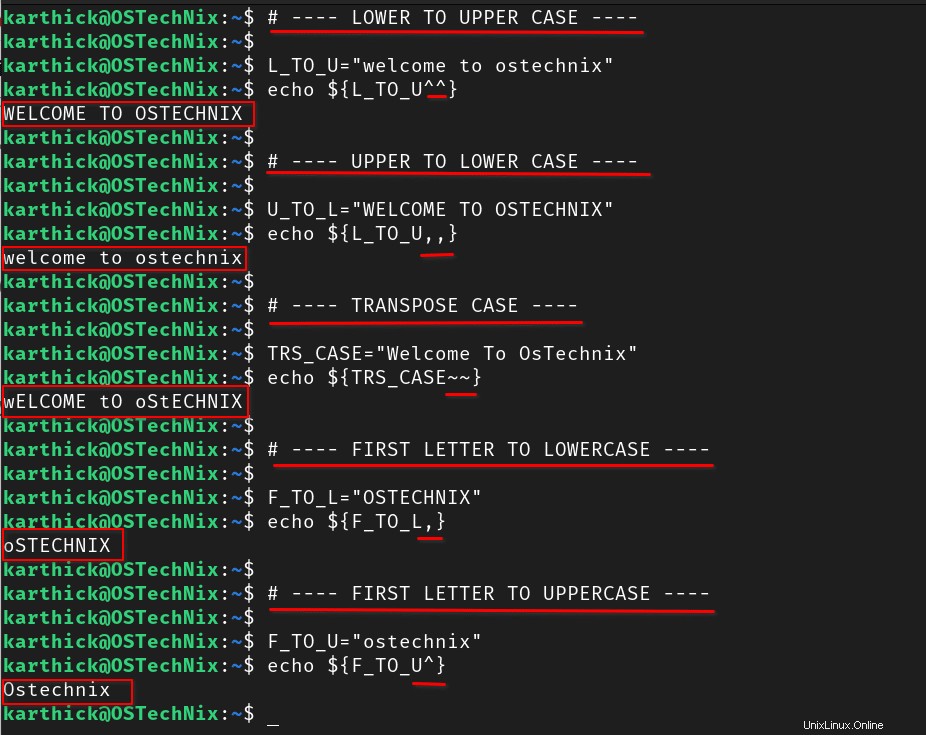
Můžete také použít porovnávání vzorů regulárních výrazů a převést velká a malá písmena u shod.
$ L_TO_U="welcome to ostechnix"
$ echo ${L_TO_U^^[toe]}

Zřetězení řetězců
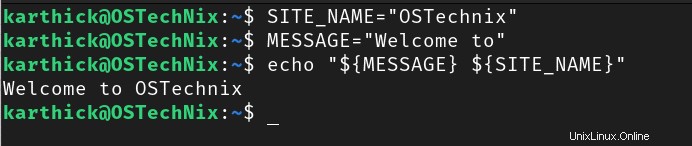
Můžete zřetězit více řetězců umístěním řetězců jeden za druhým. V závislosti na tom, jak jsou vaše řetězce zřetězeny, můžete přidat i další znaky.
$ SITE_NAME="OSTechnix"
$ MESSAGE="Welcome to"
$ echo "${MESSAGE} {SITE_NAME}"
Řezání řetězce
Řetězec je způsob, jak extrahovat část řetězce pomocí pozice indexu. Každému znaku v řetězci je přiřazena celočíselná hodnota, kterou lze použít k zachycení části řetězce. Hodnota indexu se pohybuje od 0 do N. Níže je uvedena syntaxe pro dělení.
{STRING:START:LENGTH}
START => Starting Index Position
LENGTH => Length of the String from position START
Pokud LENGTH není zadán, bude řetězec vytištěn až do konce od pozice indexu START .
$ SITE_NAME="OSTechnix"
$ echo ${SITE_NAME:2}

S délkou LENGTH vytiskne podřetězec od pozice START indexu a kolik znaků se má vytisknout.
$ echo ${SITE_NAME:2:2} 
Řetězec můžete také mnoha způsoby obrátit. Nejjednodušší způsob je použít příkaz rev. Pokud to chcete udělat bash způsobem bez použití jakéhokoli externího příkazu, musíte logiku napsat ručně.
$ echo ${SITE_NAME} | rev 
Vyhledat a nahradit
Existuje nativní způsob, jak vyhledávat a nahrazovat znaky v řetězci bez použití jakéhokoli externího příkazu, jako je sed nebo awk .
Chcete-li nahradit první výskyt podřetězce, použijte následující syntaxi.
{STRING/X/Y}
The first occurrence of X will be replaced by Y.
Podívejte se na níže uvedený příklad, kde je první výskyt slova "linux" je nahrazeno LINUX velkými písmeny.
$ MESSAGE="linux is awesome to work with.
Ubuntu is one of the powerful linux distribution"
$ echo $MESSAGE
$ echo ${MESSAGE/linux/LINUX} 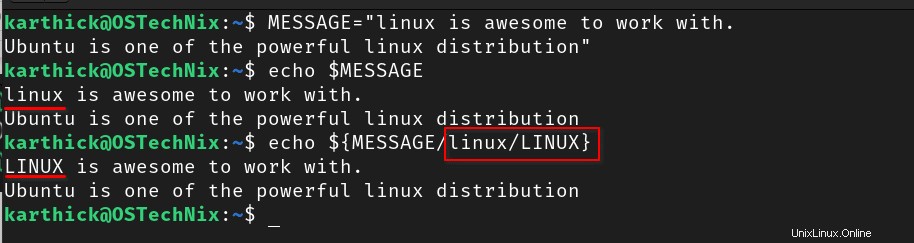
Chcete-li nahradit všechny výskyty slova, použijte následující syntaxi.
$ echo ${MESSAGE//linux/LINUX} 
Odstranit podřetězec
Existují různé způsoby, jak odstranit podřetězec z řetězce. Externí nástroje jako sed , awk nebo tr lze použít nebo existuje způsob, jak to udělat nativním způsobem bash.
Nativním způsobem bash se k odstranění podřetězce používá expanze parametrů. Musíte použít % symbol následovaný vzorem k odstranění. Tím se bude shodovat s posledním nalezeným vzorem a odstraní se.
Například chci odstranit slova, která následují za tečkou (. ) by měla být použita následující syntaxe. Zde vše, co následuje po období (. ) budou odstraněny. V tomto případě poslední odpovídající vzor .com je odstraněn.
$ SITE_NAME="www.ostechnix.com"
$ echo ${SITE_NAME%.*}

Chcete-li odpovídat prvnímu výskytu vzoru, použijte dvojité procento symbol
$ SITE_NAME="www.ostechnix.com"
$ echo ${SITE_NAME%%.*}

Můžete také použít # nebo ## symbol, který provede druh inverzního mazání. S jediným # symbol, první vzor je spárován a vše před vzorem je smazáno.
$ SITE_NAME="www.ostechnix.com"
$ echo ${SITE_NAME#*.}

S dvojitým ## symbol, poslední vzor je spárován a vše před vzorem je smazáno.
$ SITE_NAME="www.ostechnix.com"
$ echo ${SITE_NAME##*.}

Závěr
V tomto článku jsme viděli, jak vytvořit struny v bash a různé způsoby, jak se strunami manipulovat. Chcete-li se seznámit s manipulací s bash řetězci, spusťte terminál a začněte procvičovat příklady uvedené v této příručce. Pokud máte nějakou zpětnou vazbu nebo dotaz, použijte prosím sekci komentářů níže.
Příručky skriptování Bash:
- Skriptování Bash – příkaz Printf s příklady
- Skriptování Bash – indexované pole s příklady
- Bash Scripting – Asociativní pole vysvětleno s příklady
- Bash Scripting – pro smyčku vysvětlenou na příkladech
- Přesměrování Bash vysvětleno na příkladech
- Bash Scripting – proměnné vysvětlené na příkladech
- Bash Scripting – funkce vysvětlené na příkladech
- Příkaz Bash Echo vysvětlený s příklady v Linuxu
- Výukový program Bash Heredoc pro začátečníky