Zkušení správci systému obvykle přizpůsobí své systémy Linux tak, aby vyhovovaly jejich potřebám a vytvořily konzistentní prostředí. Ale co když pracujete v prostředí, kde neděláte máte oprávnění provádět trvalé změny? Nebo jen pomáháte někomu z jiného oddělení? Někdy může druhý server provozovat jinou "příchuť" Linuxu nebo dokonce jiný typ Unixu.
Zde je několik rychlých a špinavých triků, které mohou být užitečné v některých praktických situacích.
[ Čtenářům se také líbilo: Další hloupé Bashovy triky:Proměnné, hledání, deskriptory souborů a vzdálené operace ]
Znáte pravidla a víte, kdy pravidla porušit
Proměnné by měly mít jasné názvy, aby byly snadno srozumitelné, aby se daly samostatně dokumentovat a aby bylo zachováno naše duševní zdraví. Předpokládám, že s tím všichni souhlasí.
Někdy jste však uprostřed noci nuceni vyřešit produkční problém a chcete postupovat rychle .
Jindy si také musíte ušetřit nějaké psaní, protože víte, že budete muset některé dlouhé příkazy spouštět vícekrát. V normální situaci byste vytvořili aliasy a vložili je do svých přihlašovacích profilů. Zde však mluvíme o neznámém prostředí, když se soustředíte na vyřešení incidentu.
Klasický případ „příliš mnoho síťových připojení, které se zbláznilo“
Jste odvoláni ve 2:00, protože „něco“ nefunguje. Všechno fungovalo normálně až do dnešní noci.
Počínaje nějakou variantou ss příkazu (nebo netstat, pokud jste trochu starší, jako já), si všimnete stovek připojení za TIME-WAIT a ZAVŘÍT-ČEKAT na vašem hlavním serveru.
Poznámka :V animaci níže používáme ss -4a příkaz k zobrazení seznamu všech připojení IPv4. Nás ale zajímají spíše ty, které jsou v WAIT stav:
Můžete vidět, že všechna tato připojení směřují na port 50505 alespoň na dvou serverech. Cílová IP a port jsou v poli #6. Viz obrázek níže.
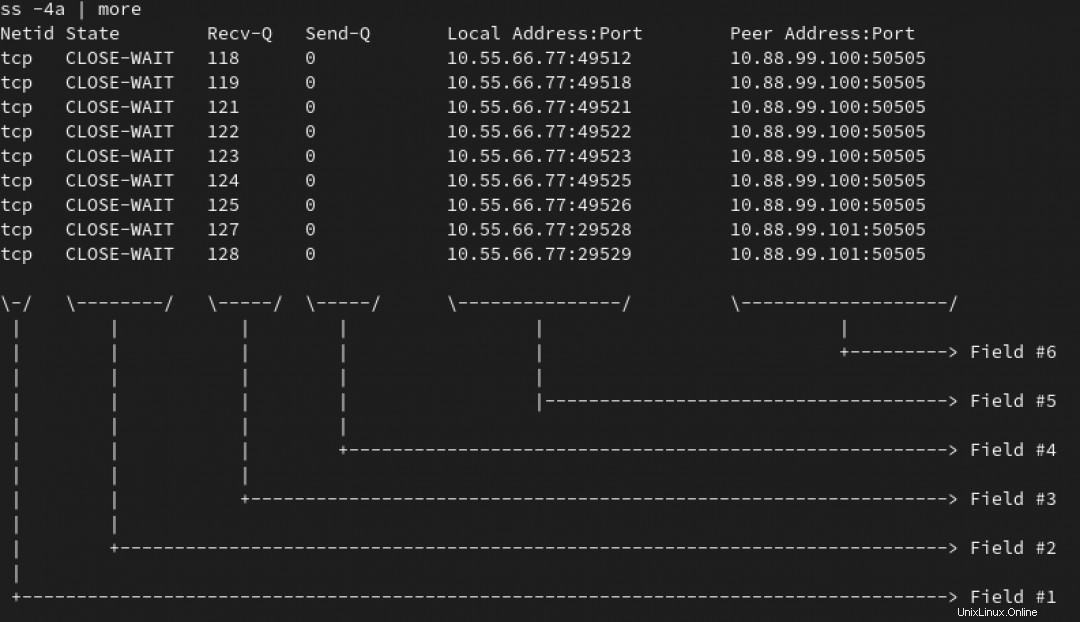
Nyní chcete zjistit, kolik připojení čekají na každou cílovou IP.
Můžeme toho dosáhnout vyladěním ss příkaz, který jsme použili dříve:
Posloupnost kroků je následující:
- Začneme kontrolovat záhlaví a prvních 10 řádků pomocí příkazu
ss -4a | grep WAIT | head - Potom
pipetoawk, který se v tomto případě používá k tisku pole #6 (předpokládáme, že výchozím oddělovačem jsou mezery). - Poté
sortpředchozí výstup, protože dále chceme mít počet zapojených různých cílových serverů. - Nakonec používáme
uniq -cprezentovat počet jedinečných linek. Protože jsme v posledním kroku tohoto úkolu, musíme odstranitheadpříkaz, který jsme používali, když jsme sestavovali výstup.
V tomto bodě vyšetřování můžete začít vytvářet nějaké korelace, jako například:"Ovlivněny jsou další dva cíle, takže hlavní příčina je buď na úrovni clusteru, nebo souvisí se sítí/firewallem."
Určitě existují způsoby, jak přizpůsobit výstup ss zobrazit pouze sloupec, který vás zajímá. Může se však stát, že ve 2 hodiny ráno nebudete chtít hledat. Toto byl jen jeden příklad a v mnoha dalších situacích budete mít další příkazy s více možnostmi.
Cílem je zde ukázat rychlý způsob práce s výstupem, který pravděpodobně znáte z některých příkazů, které jste již použili (ale nepotřebujete nebo nechcete si pamatovat VŠECHNY možné způsoby konfigurace jejich výstupu).
Klasický případ "nízkého volného místa na disku"
Další příklad ze skutečného života:Řešíte problém a zjistíte, že jeden souborový systém je na 100 procentech své kapacity.
Ve výrobě může být mnoho podadresářů a souborů, takže možná budete muset přijít na nějaký způsob, jak klasifikovat "nejhorší adresáře", protože problém (nebo řešení) může být v jednom nebo více.
V dalším příkladu ukážu velmi jednoduchý scénář pro ilustraci tohoto bodu.
Posloupnost kroků je:
- Přejdeme do systému souborů, kde je málo místa na disku (jako příklad jsem použil svůj domovský adresář).
- Potom použijeme příkaz
df -k *pro zobrazení velikosti adresářů v kilobajtech. - To vyžaduje určitou klasifikaci, abychom našli ty velké, ale stačí
sortnestačí, protože ve výchozím nastavení tento příkaz nebude považovat čísla za hodnoty, ale pouze za znaky. - Přidáváme
-ndosortpříkaz, který nám nyní ukazuje největší adresáře. - Pro případ, že bychom museli přejít do mnoha dalších adresářů, vytvoříme
aliasmůže být užitečné.
[ Naučte se základy používání Kubernetes v tomto bezplatném cheatu. ]
Sbalit
Existují příkazy, které jsou užitečné v různých situacích, například grep , awk , sort . Znalost některých základních možností a jejich kombinace může být velmi efektivní, když potřebujete manipulovat a zjednodušit výstup z jiných příkazů nebo při zpracování textových souborů.
Tyto příkazy existují téměř ve všech variantách Unixu, starých i nových, a proto je výhodné je mít v tašce triků. Nikdy nevíte, kdy vám tyto nástroje zachrání život (mrknutí).