Jako správce Linuxu nebo pokročilý uživatel je prvořadé zvládnout správu souborů v jakékoli distribuci operačního systému Linux, kterou používáte. Správa souborů je základním aspektem správy operačního systému Linux a bez ní bychom nebyli schopni přijmout funkce související se soubory, jako je šifrování souborů, správa uživatelů souborů, soulad se soubory, aktualizace a údržba souborů a správa životního cyklu souborů.
V tomto článku se podíváme na důležitý aspekt správy souborů Linux, kterým je rozdělování velkých souborů na části s danými čísly řádků. Pokud by cílem tohoto článku bylo pouze rozdělit velký soubor na zvládnutelné malé soubory bez ohledu na čísla řádků souborů, pak bychom potřebovali pouze pohodlí rozdělení příkaz.
Ukázkový referenční soubor
Aby tento tutoriál dával smysl, představíme vzorový textový soubor, který bude fungovat jako velký soubor, který chceme rozdělit z daných čísel řádků. Vytvořte ukázkový textový soubor a naplňte jej podle ukázky.
$ sudo nano sample_file.txt
Otevřete tento soubor příkazem cat a poznamenejte si čísla souvisejících řádků:
$ cat -n sample_text.txt
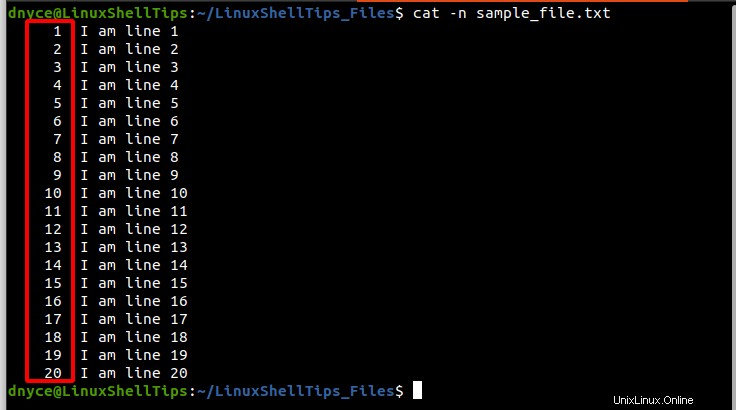
Jak jste si všimli, výše uvedený soubor má 1 do 20 čísla řádků. Nyní řekněme, že chceme tento soubor rozdělit na 4 díly na řádcích 5 , 11 a 17 .
Výsledkem by byly následující soubory:
- soubor_1 obsahující řádky 1 až 5 souboru sample_file.txt.
- soubor_2 obsahující řádky 6 až 11 souboru sample_file.txt.
- soubor_3 obsahující řádky 12 až 17 souboru sample_file.txt.
- soubor_4 obsahující řádky 18 až 20 souboru sample_file.txt.
Nyní, když jsme pochopili naše prohlášení o problému, je čas podívat se na metodiky potřebné pro životaschopné řešení.
1. Použití příkazů hlavy a ocasu
Účinnost kombinace těchto dvou příkazů k rozdělení velkého souboru na části z poskytnutých čísel řádků vyžaduje zahrnutí -n jako součást provádění příkazu.
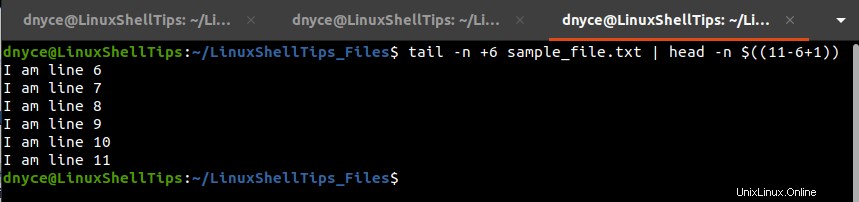
Chcete-li extrahovat čísla řádků 6 do 11 , provedeme následující příkaz.
$ tail -n +3 sample_file.txt | head -n $(( 11-6+1 ))
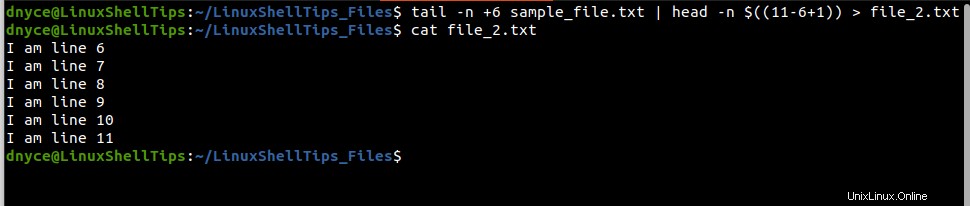
Chcete-li tento výstup uložit do souboru file_2.txt :
$ tail -n +6 sample_file.txt | head -n $((11-6+1)) > file_2.txt $ cat file_2.txt
2. Pomocí příkazu sed
Od sed příkaz podporuje dva dané rozsahy adres, můžeme extrahovat řádky 12 do 17 následujícím způsobem.
$ sed -n '12,17p; 18q' sample_file.txt

Příkaz můžeme upravit tak, aby se výše uvedený výstup uložil do souboru_3.txt .
$ sed -n '12,17p; 18q' sample_file.txt > file_3.txt $ cat file_3.txt

3. Pomocí příkazu awk
The awk příkaz podporuje řadu funkcí, jako je přesměrování, smyčky a pole. Můžeme jej tedy použít k vytvoření všech potřebných částí souborů (soubor_1.txt , soubor_2.txt , soubor_3.txt a file_4.txt ) z velkého souboru (ukázkový_soubor.txt ) s jedinou příkazovou frází, jak je ukázáno níže.
The awk příkaz je opatřen čísly klíčových řádků (5 , 11 a 17 ) potřebné k rozdělení souboru sample_file.txt na čtyři části (soubor_1.txt , soubor_2.txt , soubor_3.txt a file_4.txt ).
$ awk -v nums="5 11 17" '
BEGIN {
c=split(nums,b)
for(i=1; i<=c; i++) a[b[i]] j=1; out = "file_1.txt" } { print > out }
NR in a {
close(out)
out = "file_" ++j ".txt"
}' sample_file.txt
Výsledek provedení výše uvedeného awk příkaz je patrný z následujícího snímku obrazovky.
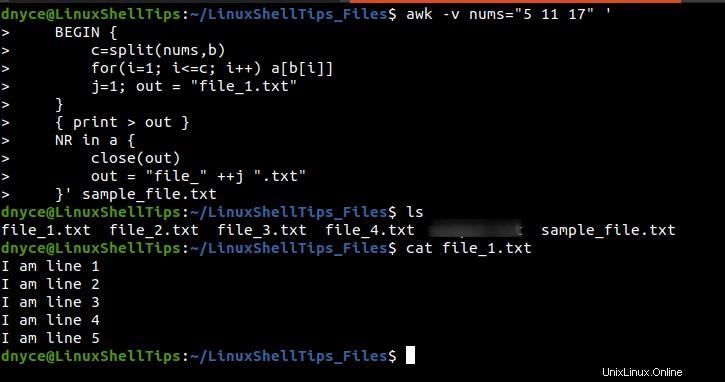
Nyní můžeme pohodlně rozdělit velké soubory na části na základě poskytnutých čísel řádků pomocí různých přístupů, jak je popsáno v tomto výukovém programu.
Můžete si také přečíst následující související články:
- Jak rychleji Gzipovat velké (100 GB+) soubory v Linuxu
- Jak vytvořit velký 1GB nebo 10GB soubor v Linuxu
- Jak zkopírovat velké množství souborů v systému Linux