Práce pod distribucí operačního systému Linux vám poskytuje velmi jedinečný pohled na to, jak proměnlivý může být svět počítačů. Například odstranění mezer v textových souborech může znít jako zdlouhavý úkol, pokud jako primární operační systém nepoužíváte Linux.
Bílé mezery nejsou pouze vodorovné, jako jsou mezery mezi slovy v tomto článku nebo jiné tisknutelné znaky. Bílé mezery existují také jako svislé mezery mezi řádky a/nebo odstavci. Proč tedy odstraňovat bílá místa? Primárním důvodem je dezinfekce vzhledu vašeho cíleného textového souboru.
Referenční textový soubor
Zvažte následující ukázkový textový soubor.
$ sudo nano sample_file.txt
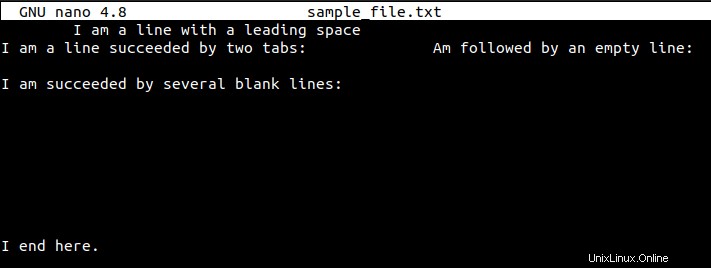
Podle výše uvedeného snímku obrazovky můžeme evidentně poznamenat, že textový soubor vykazuje příznaky jak vertikálních, tak horizontálních prázdných znaků. Můžeme použít příkaz cat plus -n možnost otevřít tento soubor v očíslovaném zobrazení.
$ cat -n sample_file.txt
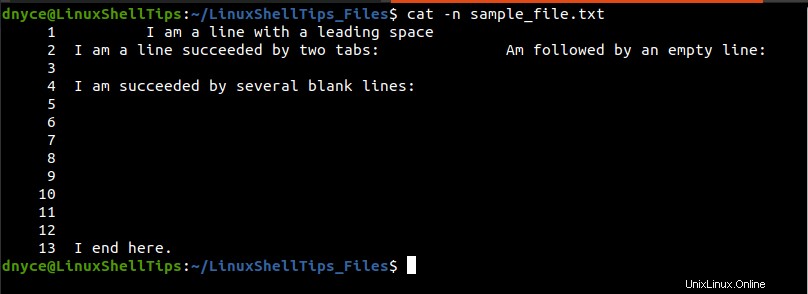
Mezi zjevné prázdné znaky v textovém souboru patří mezery, tabulátory a zalomení řádků. Abychom odstranili všechny tyto prázdné znaky, zvážíme pomoc a použití tří vestavěných linuxových příkazů.
Metoda 1:Použití příkazu tr
příkaz tr použije výše uvedený textový soubor jako svůj vstup, přeloží obsah textového souboru, odstraní prázdné znaky a poté zapíše zpět do souboru výstup znaků bez mezer.
Musíme však poskytnout příkaz tr se specifickými požadavky na provedení, tj. zda odstranit horizontální prázdné znaky, vertikální prázdné znaky nebo obojí.
Odstranění vodorovných mezer v souboru
Použijeme "[:blank:]" znak jako součást příkazu a poté spusťte příkaz cat vytisknout konečné rozložení souboru.
$ tr -d "[:blank:]" < sample_file.txt | cat -n
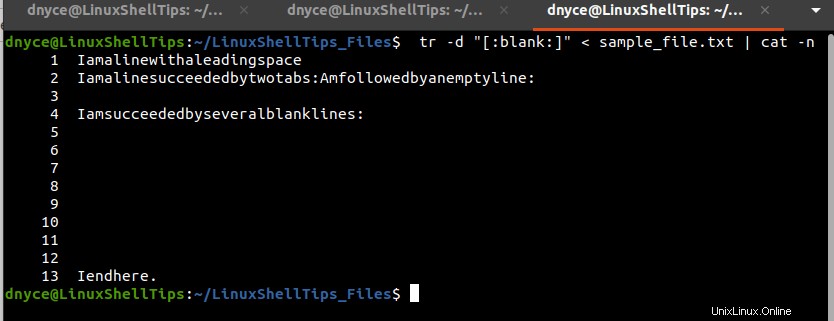
Podle výše uvedeného výstupu jsme v Linuxu úspěšně odstranili vodorovné prázdné znaky z textového souboru.
Odeberte ze souboru všechny prázdné znaky
"[:space:]" Tato volba se používá k odstranění horizontálních i vertikálních prázdných znaků z textového souboru.
$ tr -d "[:space:]" < raw_file.txt | cat -n

Metoda 2:Použití příkazu sed
Protože příkaz sed je běžně implementován pomocí regulárních výrazů, můžeme jej použít následujícím způsobem:
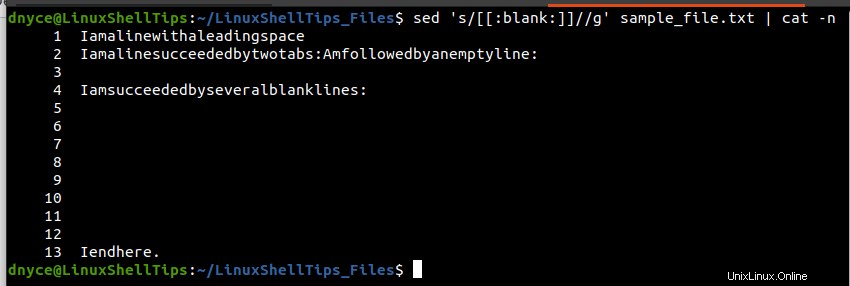
$ sed 's/[[:blank:]]//g' sample_file.txt | cat -n [Remove Horizontal Spaces] $ sed ':a; N; s/[[:space:]]//g; ta' sample_file.txt | cat -n [Remove All Spaces]
Metoda 2:Použití příkazu awk
Tento výkonný nástroj pro zpracování textu využívá svůj skript podobný C a další vestavěné funkce a proměnné k flexibilní manipulaci se zpracováním textu.
Využijeme jeho funkci gsub následujícím způsobem odstraníte horizontální prázdné znaky.
$ awk '{gsub(/[[:blank:]]/,""); print}' sample_file.txt | cat -n
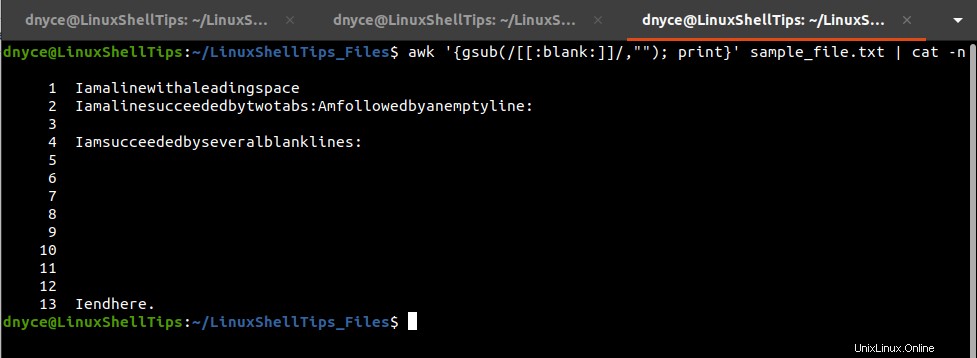
Chcete-li z textového souboru odstranit všechny prázdné znaky, provedeme ve výše uvedeném příkazu následující úpravu:
$ awk -v ORS="" '{gsub(/[[:space:]]/,""); print}' sample_file.txt | cat -n
S výše diskutovanými třemi linuxovými příkazy by odstranění nechtěných prázdných znaků v textových souborech v Linuxu nemělo být problém.