Operační systém Linux se rád chlubí svým výpočetním výkonem a obratností. Jeho algoritmický přístup k věcem, jako je zpracování souborů, zejména v rámci správy souborů, přináší uživatelům Linuxu důležité milníky na cestě ke zvládnutí administrativních stop Linuxu.
Jedním z aspektů zpracování souborů v prostředí operačního systému Linux, který musíme velmi zvážit, je identifikace nejdelších řádků v rámci upravitelného souboru podporovaného Linuxem.
Praktická implikace dlouhých řádků v souboru
Zvažte scénář, kdy pracujete ve společnosti nebo se zabýváte projektem, který zpracovává velké soubory protokolu. Tyto soubory mohou být vykresleny jako jednotlivé textové řádky, i když ve skutečnosti mohou zapouzdřit tisíce dokumentů JSON.
Pokud je velikost těchto textových řádků velmi/neobvykle dlouhá, může být pro správné přesměrování souboru (souborů) na cílový server, jako je elastický vyhledávací server, vyžadováno jejich zpracování přes proxy server.
Takové pečlivé kroky ke zpracování souborů však mohou vést k nezamýšleným chybám při zpracování souborů, když ve skutečnosti máte ve svých souborech pouze dlouhé řádky. Diagnostikování takové chyby je nemožné bez znalosti hrozby ve hře.
Tento tutoriál provede kroky potřebné k identifikaci nejdelších řádků v cílovém souboru v prostředí operačního systému Linux.
Prohlášení o problému
Aby byl tento článek zábavnější a poutavější, vytvoříme referenční textový soubor s několika různými řádky a později implementujeme platná řešení pro Linux, abychom zjistili nejdelší řádky.
$ sudo nano sample_file.txt
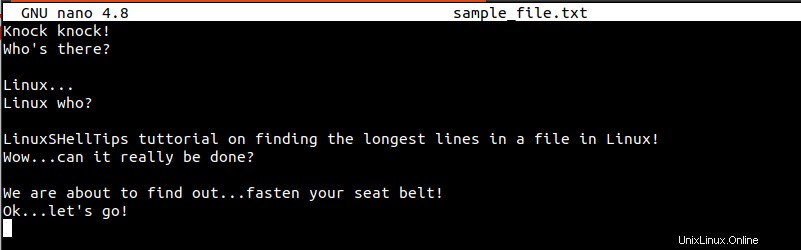
Budeme se snažit identifikovat nejdelší řádky ve výše uvedeném souboru (sample_file.txt ) prostřednictvím užitečných příkazů Linuxu.
1. Najděte nejdelší řádek v souboru pomocí příkazu Awk
V ideálním případě bychom mohli všechny řádky ve výše uvedeném souboru předřadit pomocí jednořádkového awk příkaz k určení jejich přesné délky, jak je ukázáno níže.
$ awk '{printf "%2d| %s\n",length,$0}' sample_file.txt
Podle snímku obrazovky výše 73 je největší délka řádku.
Vytiskněte nejdelší řádek v souboru pomocí příkazů wc a grep
Kombinací těchto dvou příkazů získáte použití regex z příkazu grep a max-line-length z příkazu wc. Wc příkaz přebírá -L příkaz k určení maximální délky-řádku, jak je ukázáno níže.
$ grep -E "^.{$(tr '\t' ' ' Výše uvedený příkaz by měl vytisknout nejdelší řádky v souboru sample_file.txt .

Protože jsme měli dvě stejné čáry s největší délkou čáry 73 , výše uvedený příkaz vytiskl dva linky. Pokud by to byl pouze jeden řádek s největší délkou řádku 73, vytiskl by se pouze tento řádek.
Nyní jsme schopni najít nejdelší řádek(y) v souboru v Linuxu.