Když v Linuxu potřebujete porovnat dva soubory obsahující podobný text, může vám použití příkazu diff značně usnadnit váš úkol. Příkaz porovná dva soubory, aby navrhl změny, díky kterým by byly soubory identické. Skvělé pro nalezení extra složené závorky, která porušila váš nově aktualizovaný kód.
Použití příkazu diff je velmi jednoduché. Zde je syntaxe:
diff [options] file1 file2Ale pochopit jeho výstup je jiná věc. Nebojte se, vysvětlím vám výstup, abyste mohli porovnat dva soubory a pochopit rozdíl mezi nimi.
Porozumění příkazu diff v Linuxu
Pro začátek potřebujete několik souborů. Vytvořil jsem seznam pomocí generátoru náhodných slov.
Přidal jsem seznam do dvou různých souborů a poté jsem seznam upravil podle:
- Změna pořadí seznamu
- Přidávání písmen
- Přepínací pouzdro
Tyto podobné soubory jsem uložil jako 1.txt a 2.txt. Tady je, jak vypadají, než něco uděláte.
Doporučuji, abyste se při čtení řídili výukovým programem, takže prosím vytvořte nové soubory a přidejte k nim následující obsah.
Obsah 1.txt :
pavučina
medailonek
akustika
rozšíření
záznam
Obsah 2.txt:
pavučina
ZÁMEK
akustika
evidence
rozšíření
Příklad 1:Rozdíl bez možností
Podívejme se, co se stane, když spustíte diff příkaz bez jakýchkoli možností.
christopher:~$ diff 1.txt 2.txt
2c2
< locket
---
> LOCKET
3a4
> records
5d5
< recordZmatený? Nejsi sám. Výstup není zrovna přátelský k lidem. Abyste pochopili, co se děje, potřebujete vědět více o tom, jak funguje rozdíl.
Může být užitečné vědět, že když je analýza hotová, file2 [v syntaxi] je považováno za referenční dokument, se kterým se pokoušíte porovnat. Můžete tedy říci, že diff funguje tímto způsobem:
diff <file_to_edit> <file_as_reference>To také znamená, že získáte jiný výstup na základě pořadí, ve kterém umístíte názvy souborů.
Na objednávce záleží
Příklad, jak se výstup liší v závislosti na pořadí souborů:
christopher:~$ diff 1.txt 2.txt
2c2
< locket
---
> LOCKET
3a4
> records
5d5
< record
christopher:~$ diff 2.txt 1.txt
2c2
< LOCKET
---
> locket
4d3
< records
5a5
> recordDůležité symboly ve výstupu příkazu diff
Pomocí níže uvedené tabulky jako reference můžete lépe porozumět tomu, co se děje ve vašem terminálu.
| Symbol | Význam |
|---|---|
| A | Přidat |
| C | Změnit |
| D | Smazat |
| # | Čísla řádků |
| – – – | Odděluje soubory ve výstupu |
| < | Soubor 1 |
| > | Soubor 2 |
Podívejme se znovu na výstup příkazu diff:
christopher:~$ diff 1.txt 2.txt
2c2
< locket
---
> LOCKET
3a4
> records
5d5
< recordVysvětlení výstupu příkazu diff
Podívejme se na první rozdíl ve výstupu:
| Výstupní linka | Vysvětlení |
|---|---|
| 2c2 | Řádek 2 souboru 1, ZMĚNIT s řádkem 2 souboru 2. |
| Změňte „locket“ na „LOCKET“, aby odpovídal souboru 2.txt |
Podívejme se na další část výstupu:
| Výstupní linka | Vysvětlení |
|---|---|
| 3a4 | Za řádek 3 souboru 1 přidejte řádek 4 souboru 2. |
| > záznamy | To znamená přidat „záznamy“, aby se vytvořil 4. řádek v souboru 1. Takže soubor 1.txt bude odpovídat souboru 2.txt |
Podobně:
| Výstupní linka | Vysvětlení |
|---|---|
5d5 | Smažte text „záznam“ z 5. řádku souboru 1. Aby soubor 1.txt odpovídal souboru 2.txt | |
V příkazu není zabudována žádná funkce kontroly pravopisu ani slovníku. Neuznává „záznam“ a „záznamy“ jako související. Jeho jediným cílem je dokonale sladit dva soubory.
Při pohledu na výstup je stále dost těžké ho přeložit. Je nepravděpodobné, že byste ušetřili spoustu času.
Naštěstí existují možnosti, které lze přidat, aby byly věci lépe čitelné pro člověka. Podívejme se na několik různých příkladů pomocí stejného seznamu.
Příklad 2:Rozdíl v kontextu „Copied“ s -c
Kontextová možnost poskytuje vizuálnější reprezentaci oproti programatičtějším informacím zobrazeným ve výchozím nastavení. Pokračujme v našem vzorovém textu.
Důležitější symboly ve výstupu příkazu diff
| Symbol | Význam |
|---|---|
| + | Přidat |
| ! | Změnit |
| – | Smazat |
| *** | Soubor 1 |
| – – – | Soubor 2 |
christopher:~$ diff -c 1.txt 2.txt
*** 1.txt 2019-10-20 12:05:09.244673327 -0400
--- 2.txt 2019-10-20 12:11More:31.382547316 -0400
***************
*** 1,5 ****
cobweb
! locket
acoustics
expansion
- record
--- 1,5 ----
cobweb
! LOCKET
acoustics
+ records
expansionJe mnohem snazší pochopit, když vidíte informace tímto způsobem. Namísto alfanumerického výstupu vám nová sada symbolů pomůže rychle identifikovat rozdíly mezi těmito dvěma soubory.
Výstup nejprve zobrazí první soubor, tj. 1.txt a jeho řádek od 1 do 5. Říká, že došlo k mírné změně v (části) řádku 2 souboru 1.txt a (části) řádku 2 souboru 2 .txt.
Také to znamená, že řádek číslo 5 souboru 1 byl odstraněn (-) ve druhém souboru.
— 1,5 —- označuje začátek druhého souboru a říká, že řádek 2 je mírně změněn oproti řádku 2 souboru 1. Také to znamená, že řádek 4 byl přidán (+) do druhého souboru a neexistuje žádný odpovídající řádek v souboru 1.
Příklad 3:Rozdíl v kontextu „Unified“ s -u
Tato možnost poskytuje výstup podobný formátu zkopírovaného kontextu. Místo zobrazení dvou souborů odděleně je sloučí dohromady.
christopher:~$ diff 1.txt 2.txt -u
--- 1.txt 2019-10-20 12:05:09.244673327 -0400
+++ 2.txt 2019-10-20 12:11:31.382547316 -0400
@@ -1,5 +1,5 @@
cobweb
-locket
+LOCKET
acoustics
+records
expansion
-record
Jak vidíte, používá stejné symboly jako dříve, ale místo symbolu změny navrhuje změny, které je třeba provést pomocí snadno čitelného + nebo - symboly. Zde se doporučuje odstranit řádek 2 z 1.txt a nahraďte jej řádkem 2 z 2.txt .
Do budoucna také navrhuje, abyste přidali záznamy za řádkem obsahujícím akustiku a smazat řádek záznam za řádkem obsahujícím expanzi.
Všechny tyto změny jsou navrženy pro první soubor v příkazu diff. Toto je další scénář, kdy pomáhá zapamatovat si, že program diff používá druhý soubor uvedený jako „originál“ nebo jako základ pro opravy.
Pro srovnání takového seznamu se mi osobně zdá tato metoda nejjednodušší. Poskytuje vám jasnou vizualizaci textu, který je třeba změnit, aby byly soubory identické.
Příklad 4:Porovnání, ale ignorování případů s -i
Vyhledávání rozlišující malá a velká písmena jsou výchozí pro rozdíl, ale můžete to vypnout. Podívejme se, co se stane, když to uděláte.
christopher:~$ diff 1.txt 2.txt -i
3a4
> records
5d5
< recordJak můžete vidět, „medailon“ a „LOCKET“ již nejsou uvedeny jako navrhované změny.
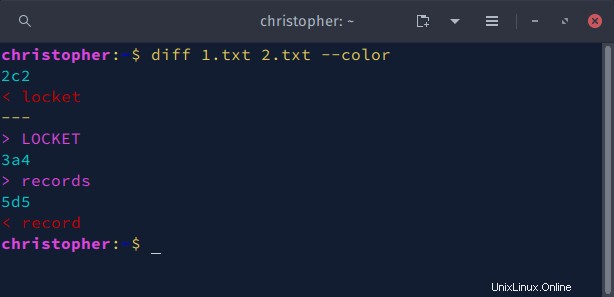
Příklad 5:Rozdíl s –color
Můžete použít --color pro zvýraznění změn ve výstupu příkazu diff. Když je příkaz spuštěn, části výstupu se vytisknou v různých barvách z palety terminálu.
Příklad 6:Rychlá analýza souborů s volbami příkazu diff -s a -q
Existuje několik jednoduchých způsobů, jak zkontrolovat, zda jsou soubory totožné. Pokud použijete -s to vám řekne, že soubory jsou identické, nebo to poběží jinak jako normálně.
Pomocí -q pouze vám řekne, že se soubory „liší“. Pokud tak neučiní, nedostanete žádný výstup.
christopher:~$ diff 1.txt 1.txt -s
Files 1.txt and 1.txt are identical
christopher:~$ diff 1.txt 2.txt -q
Files 1.txt and 2.txt differBonusový tip:Použití příkazu diff v Linuxu s velkými textovými soubory
Možná ne vždy srovnáváte tak jednoduché informace. Můžete mít velké textové soubory, které můžete naskenovat a najít rozdíly. Uvedu několik metod řešení tohoto typu problému.
Pro tento příklad jsem vytvořil dva soubory s velkými kusy textu (lorem ipsum). Každý řádek má stovky sloupců. To zjevně znesnadnilo porovnávání řádků.
Když je diff spuštěn na souboru, jako je tento, výstup generuje obrovské kusy textu a symboly jsou obtížně vidět i s nástroji, jako je kontextový výstup.
Abychom ušetřili místo, udělal jsem snímek obrazovky výstupu, abyste se na něj mohli podívat.
Není to moc užitečné, že?
K analýze těchto typů souborů můžete použít některé ze stejných konceptů. Nebudou dobře fungovat, pokud není soubor správně naformátován. Některé velké bloky textu nemají zalomení řádků. Pravděpodobně jste se setkali s podobným souborem, kde jste potřebovali povolit „Word Wrap“, aby se veškerý text zobrazil v rámci přiděleného prostoru bez použití posuvníku. Důvodem je, že některé textové formáty nevytvářejí zalomení řádků automaticky. Takto skončíte s velkými kusy textu pouze na 2-3 řádcích. Na to existuje docela snadná oprava.
Pomocí přeložení zalomit text do řádků
Toto je příručka pro Linux, takže pro vás samozřejmě máme řešení a můžeme do ní nacpat mini tutoriál. Zde je skvělý popis fold (Unix) a fmt (GNU). Uvedu rychlý příklad, který by však měl být docela samozřejmý, aby nás posunul vpřed.
Příkaz fold se používá k rozdělení čar pomocí počtu sloupců. Lze jej upravit, aby vám poskytl možnosti, jak jsou tyto nové konce řádků implementovány.
V tomto příkladu se chystáte rozdělit soubor na standardizovanou šířku a použít -s volba. To říká programu, aby přerušil POUZE tam, kde je mezera, nikoli uprostřed textu.
Pomocí foldu rychle vložit konce řádků
fold -w 80 -s lorem.txt > lorem.txt
fold -w 80 -s lorem2.txt > lorem2.txtS oběma soubory rozdělenými do 31 řádků místo 3 je můžete mnohem efektivněji porovnávat. Zde je příklad vašeho výstupu s jednotným kontextovým filtrem.
christopher:~$ diff lorem.txt 2lorem.txt -u
--- lorem.txt 2019-10-27 09:39:07.298691695 -0400
+++ 2lorem.txt 2019-10-27 09:39:08.370704501 -0400
@@ -1,10 +1,10 @@
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vivamus in tincidunt
sapien. Maecenas sagittis ex risus, in vehicula turpis imperdiet sed. Phasellus
placerat posuere maximus. In hac habitasse platea dictumst. Ut vel tristique
-eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor porta.
+eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor PORTA.
Suspendisse at mauris vitae sapien euismod tincidunt. Sed placerat finibus
blandit. Duis ornare ante at ipsum accumsan, nec bibendum nibh tincidunt.
-Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu,
+Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu, facilisis
vitae enim. Nam condimentum, purus nec semper efficitur, nisi quam vehicula
sem, eget finibus diam ipsum suscipit velit.
@@ -21,7 +21,7 @@
Maecenas lacinia cursus tristique. Nulla a hendrerit orci. Donec lobortis nisi
sed ante euismod lobortis. Nullam sit amet est nec nunc porttitor sollicitudin
-a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim QUAM, at
+a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim quam, at
interdum mi metus vel tellus. Fusce nec dui a risus posuere mattis at eu orci.
Proin purus sem, finibus eget viverra vel, porta pulvinar ex. In hac habitasse
platea dictumst. Nunc faucibus leo nec tristique porta. Phasellus luctus ipsumPoužít rozdíl s –minimálním výstupem
Můžete si to trochu usnadnit čtení pomocí --minimal štítek. Díky tomu jsou větší textové soubory o něco snáze čitelné. Pojďme se podívat na výstup.
christopher:~$ diff lorem.txt 2lorem.txt --minimal
4c4
< eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor porta.
---
> eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor PORTA.
7c7
< Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu,
---
> Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu, facilisis
24c24
< a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim QUAM, at
---
> a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim quam, at Můžete zkombinovat kterýkoli z těchto tipů nebo použít některé z dalších možností uvedených v manuálových stránkách rozdílů. Jedná se o výkonný a snadno použitelný softwarový nástroj.
Doufám, že vám tento článek byl užitečný. Pokud máte tip, nezapomeňte nám zanechat komentář a řekněte nám o něm.