Pokud hledáte platformu pro analýzu dat v reálném čase, Jack Wallen si myslí, že Apache Druid je těžké porazit. Zjistěte, jak zprovoznit tento nástroj a jak poté načíst ukázková data.
Apache Druid je analytická databáze v reálném čase, která byla navržena pro rychlé podsvícení analýzy řezů a kostek na masivních sadách dat. Apache Druid můžete snadno spustit z desktopové verze Linuxu – nebo linuxového serveru s GUI – a poté načíst data a začít analyzovat.
Apache Druid obsahuje funkce jako:
- Sloupcově orientované úložiště
- Indexy nativního vyhledávání
- Streamování a dávkové zpracování
- Flexibilní schémata
- Časově optimalizované rozdělení
- Podpora SQL
- Horizontální škálovatelnost
- Snadná obsluha
Apache Druid je skvělá volba pro případy použití, které vyžadují příjem v reálném čase, rychlé dotazy a vysokou dobu provozu.
Provedu vás procesem spuštění Apache Druid na Pop!_OS Linux (ačkoli jej lze spustit na jakékoli distribuci Linuxu) a poté vám ukážu, jak načíst ukázková data.
Co budete potřebovat
Jediné, co budete k tomu potřebovat, je spuštěná instance Linuxu s desktopovým prostředím a uživatelem s právy sudo.
A je to. Pojďme udělat nějaké kouzlo databáze.
Jak nainstalovat Java 8
V tuto chvíli Apache Druid podporuje pouze Java 8, takže se musíme ujistit, že je nainstalován a nastaven jako výchozí. Chcete-li nainstalovat Java 8 na desktopovou distribuci založenou na Ubuntu, přihlaste se do počítače, otevřete okno terminálu a zadejte příkaz:
sudo apt install openjdk-8-jdk -y
Po dokončení instalace je třeba nastavit Java 8 jako výchozí. Proveďte to příkazem:
sudo update-alternatives --config java
Měli byste vidět seznam všech verzí Java, které jsou aktuálně nainstalovány v počítači. Ujistěte se, že jste vybrali číslo, které odpovídá Java 8.
Něco o službách Apache Druid
To, co spustíme, je mikro instance Apache Druid, která vyžaduje 4 CPU a 16 GB RAM. Existuje 6 různých konfigurací služeb pro Apache Druid, které jsou:
- Nano-Quickstart:1 CPU, 4 GB RAM
- Micro-Quickstart:4 CPU, 16 GB RAM
- Malý:8 CPU, 64 GB RAM
- Střední:16 CPU, 128 GB RAM
- Velká:32 CPU, 256 GB RAM
- X-Large:64 CPU, 512 GB RAM
V závislosti na velikosti vašich dat a potřebách. Když se dostanete do velkého množství dat, doporučuje se, aby byl Apache Druid nasazen jako cluster. Protože se však s Apache Druid teprve seznamujeme, mikro instance bude v pořádku.
Pokrytí pro vývojáře, které si musíte přečíst
Jak stáhnout a rozbalit Apache Druid
S nainstalovanou Javou je čas stáhnout a rozbalit Apache Druid. Zpět v okně terminálu stáhněte nejnovější verzi (nezapomeňte se podívat na stránku stahování Apache Druid, abyste si ověřili, že se jedná o nejnovější verzi) pomocí příkazu:
wget https://dlcdn.apache.org/druid/0.22.1/apache-druid-0.22.1-bin.tar.gz
Rozbalte stažený soubor pomocí:
tar xvfz apache-druid-0.22.1-bin.tar.gz
Přejděte do nově vytvořeného adresáře pomocí:
cd apache-druid-0.22.1
Spusťte službu pomocí:
./bin/start-micro-quickstart
Služba Apache Druid by se měla spustit bez problému. Pamatujte, že během běhu služby nedostanete svůj terminál zpět, dokud ji nezrušíte pomocí CTRL + C.
Jak získat přístup ke konzoli Apache Druid
Na stejném počítači, na kterém běží Apache Druid, otevřete webový prohlížeč a přejděte na http://localhost:8888 . Bohužel Apache Druid je nastaven tak, že se k němu ze vzdáleného počítače nedostanete, a proto jej instalujeme na stolní počítač.
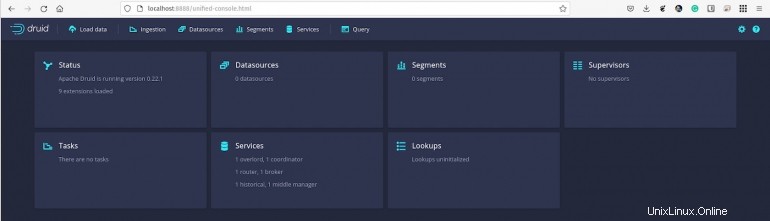
Přivítá vás konzole Apache Druid (Obrázek A ).
Obrázek A
Jak načíst data
Načteme předdefinovaný vzorek dat, který najdete v adresáři quickstart/tutorial/. Ukázka se jmenuje wikiticker-2015-09-12-sampled.json.gz.
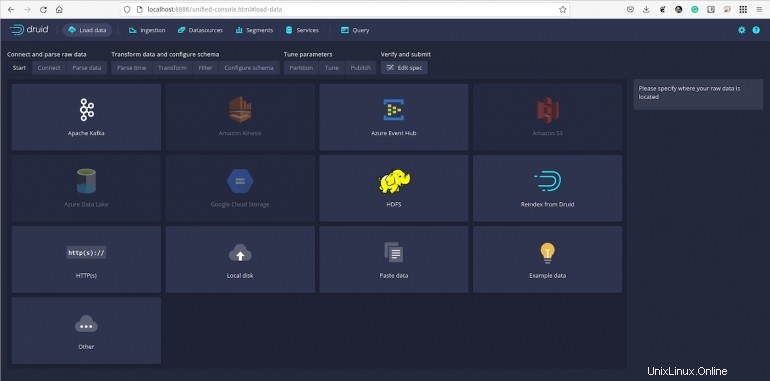
Obrázek B
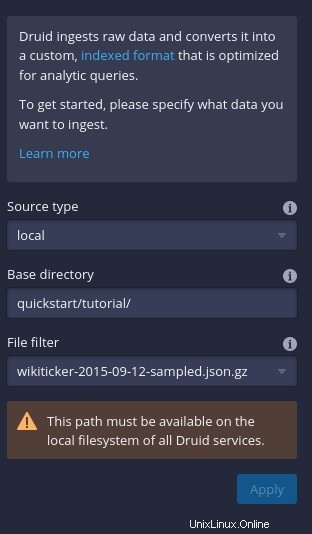
Klikněte na Připojit data (na pravé straně okna) a poté na výsledném postranním panelu (Obrázek C ), zadejte quickstart/tutorial jako základní adresář a wikiticker-2015-09-12-sampled.json.gz v sekci Filtr souborů.
Obrázek C
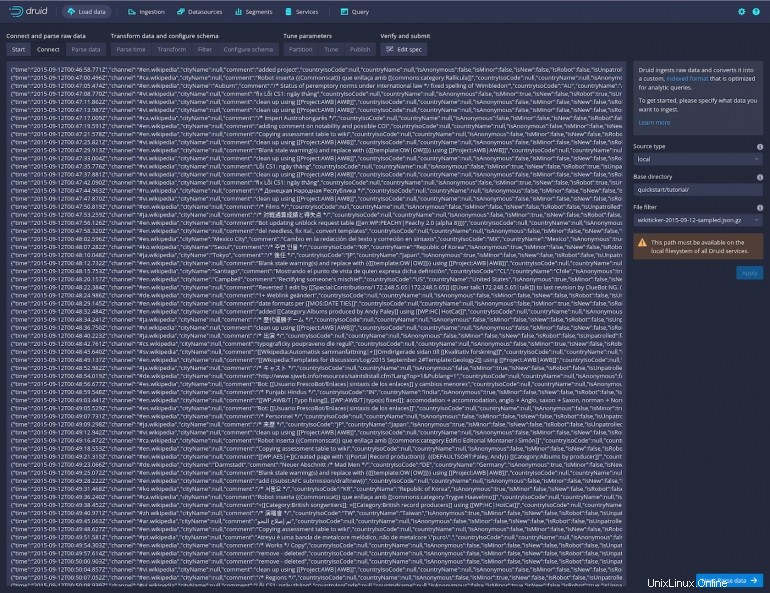
Klikněte na Použít a v hlavním okně byste měli vidět poměrně velké množství dat (Obrázek D ).
Obrázek D
Klikněte na Další:Analýza dat vpravo dole a zobrazí se vám seznam dat ve srozumitelnějším formátu (Obrázek E ).
Obrázek E
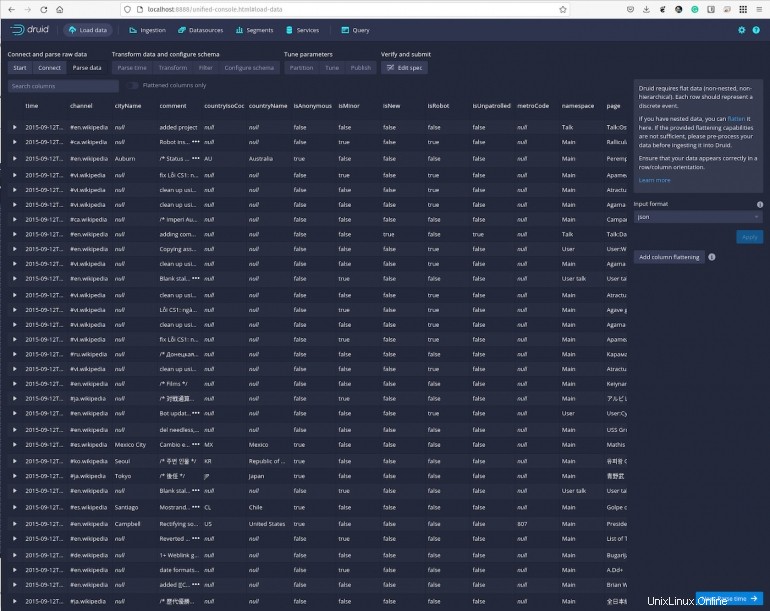
Klikněte na Další:Analyzovat čas a můžete zobrazit data s konkrétními časovými razítky (Obrázek F ).
Obrázek F
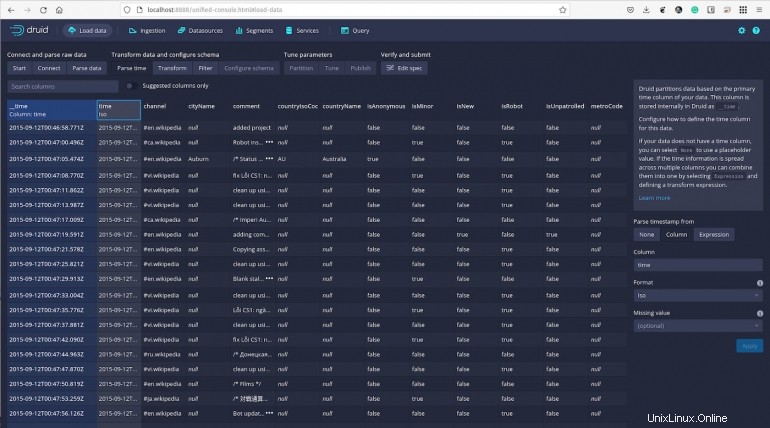
Klikněte na Další:Transformace a poté můžete provádět transformace hodnot sloupců po řádcích a buď vytvořit nové sloupce, nebo upravit ty, které již existují.
Pokračujte v procházení dat a kdykoli můžete spouštět dotazy a filtrovat data podle potřeby. V části Konfigurace schématu (Obrázek G ), můžete dokonce určit podrobnost svých dotazů a přidat dimenze a metriky.
Obrázek G
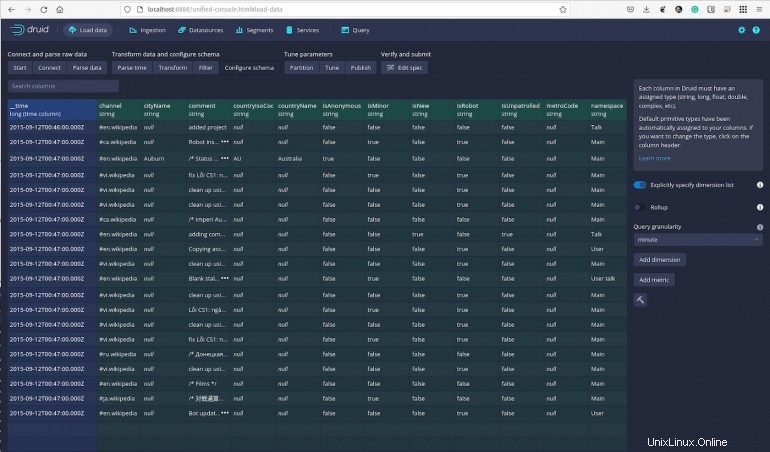
A to jsou skoro základy Apache Druida. I když jsme jen zběžně prozkoumali, co tato výkonná platforma pro analýzu dat dokáže, měli byste být schopni získat docela dobrý přehled o tom, jak funguje, když si pohrajete s ukázkovými daty.
Po dokončení práce se vraťte do okna terminálu a zastavte službu Apache Druid pomocí CTRL + C.