Grep nebo Global Regular Expression Print se používá k vyhledávání textu nebo vzorů v systému Linux. Dokáže vyhledávat v souborech, adresářích a dokonce i ve výstupech jiných příkazů.
Regulární výrazy jsou vzory, které mohou odpovídat textu podle potřeb uživatele. Jsou to jako pravidla pro párování vzorů.
Grep se často používá spolu s regulárními výrazy k hledání vzorů v textu. Podívejme se na některé praktické příklady regulárního výrazu s grep.
1. Shoda slova bez ohledu na velikost písmen
Někdy v textu může být stejné slovo napsáno různými způsoby. Nejčastěji se tak děje u vlastních podstatných jmen. Místo toho, aby začínaly velkým písmenem, jsou někdy psány malými písmeny.
$ grep "[Jj]ayant"

Obě verze slova, bez ohledu na velikost písmen, byly shodné.
Další zajímavý případ lze pozorovat u slova ‚IoT‘. Takové slovo se může v textu objevit několikrát s různými obměnami. aby odpovídala všem slovům bez ohledu na použití velkých a malých písmen :
$ grep "[iI][oO][tT]"

2. Přiřazení mobilního čísla pomocí regulárního výrazu s grep
Regulární výrazy lze použít k extrahování mobilního čísla z textu.
Formát mobilního čísla musí být znám předem. Například regulární výraz navržený tak, aby odpovídal mobilním číslům, nebude fungovat pro domácí telefonní čísla.
V tomto příkladu se bude shodovat mobilní číslo v následujícím formátu:91-1234567890 (tj. TwoDigit-TenDigit).
$ grep "[[:digit:]]\{2\}[ -]\?[[:digit:]]\{10\}"

Jak je zřejmé, shoduje se pouze číslo mobilního telefonu ve výše uvedeném formátu.
3. Porovnejte e-mailovou adresu
Extrahování e-mailové adresy z textu je velmi užitečné a lze jej dosáhnout pomocí grep.
E-mailová adresa má určitý formát. Část před znakem „@“ je uživatelské jméno, které identifikuje poštovní schránku. Pak je tu doména jako gmail.com nebo yahoo.in.
Regulární výraz lze navrhnout s ohledem na tyto věci.
$ grep -E "[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,6}"


- [A-Za-z0-9._%+-]+ zachytí uživatelské jméno před „@“
- [A-Za-z0-9.-]+ zachycuje název domény bez části „.com“
- .[A-Za-z]{2,6} zachycuje „.com“ nebo „.in“ atd.
4. Kontrola adresy URL
Adresa URL má určitý formát reprezentace. Lze sestavit regulární výraz, který ověří, zda je adresa URL ve správném tvaru nebo ne.
Adresa URL musí začínat http/https/ftp následovaným „://“. Dále je zde název domény, který může končit „.com“, „.in“, „.org“ atd.
$ grep -E "^(http|https|ftp):[\/]{2}([a-zA-Z0-9\-\.]+\.[a-zA-Z]{2,4})"


-E použité v tomto a předchozím příkladu znamená rozšířený grep, který používá sadu rozšířených regulárních výrazů namísto sady základních regulárních výrazů. To znamená, že určité speciální znaky nemusí být uvozeny. Díky tomu je proces psaní složitého regulárního výrazu méně únavný. Přečtěte si o tom více zde.
5. Hledání souborů s konkrétní příponou
Příkaz ls zobrazí všechny soubory v aktuálním adresáři.
spuštění ls -l poskytuje další informace týkající se souborů. Grep lze použít spolu s příkazem ls -l k porovnání vzoru v jeho výstupu.
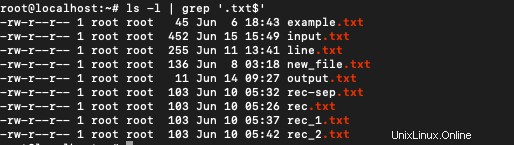
Chcete-li získat soubory, které jsou uloženy s příponou „.txt“, použijte:
$ ls -l | grep '.txt$'
6. Najděte obsah v závorkách
Textové soubory mají často obsah v závorkách. Můžeme je extrahovat pomocí regulárního výrazu pomocí grep.
$ grep "([A-Za-z ]*)"

Regulární výraz vybere text, který je v partéze. Lze také zadat délku obsahu v závorkách.
Chcete-li například přiřadit závorku pouze 10 znakům, použijte :
$ grep "([A-Za-z ]{10})"
7. Porovnejte řádky začínající konkrétním slovem
Můžeme použít regulární výraz k nalezení řádků, které začínají konkrétním slovem.

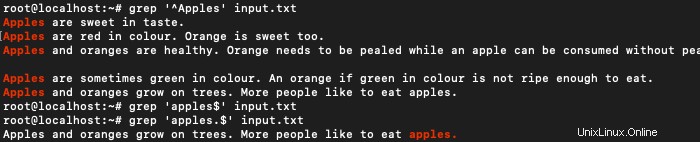
Chcete-li najít řádky začínající slovem Jablka, použijte :
grep '^Apples' input.txt
Podobně lze nalézt i řádky začínající jakýmkoli jiným slovem.
Pomocí níže uvedených regulárních výrazů můžeme porovnat řádky končící konkrétním slovem.
$ grep 'apples.$' input.txt

8. Shoda více slov najednou
Srovnejme více slov s regulárním výrazem, jak je uvedeno níže:
$ grep 'Apples\|Orange' input.txt
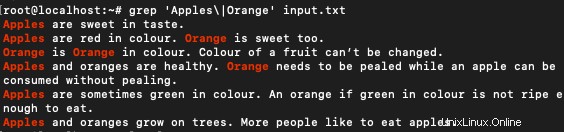
Tento příkaz funguje na řádku NEBO mezi těmito dvěma slovy. Odpovídá řádkům, které obsahují jedno z těchto dvou slov.
K provedení AND mezi těmito dvěma slovy použijte:
$ grep 'Apple' input.txt | grep 'Orange

9. Shoda stejného slova v různých tvarech
Někdy se slovo může vyskytovat v různých podobách. Mohou se lišit v závislosti na čase, ve kterém jsou použity.
Peeling a Peeling jsou toho příkladem. V obou slovech je kořenem slova 'peel'
Můžeme použít regulární výraz ke shodě všech forem slova.
V našem textu jsme hláskovali peeling a peeling jako pealed a pealing.
Podobným způsobem můžeme také překládat z americké angličtiny do anglické angličtiny. Například ze slova barva se stane barva.
$ grep 'peal\([a-z]*\)\(\.*[[:space:]]\)' input.txt

10. Hledání uživatelů v souboru /etc/passwd
grep lze použít k získání uživatelů ze souboru /etc/passwd/. Soubor /etc/passwd udržuje seznam uživatelů v systému spolu s některými dalšími informacemi.
$ grep "Adam" /etc/passwd

Příkaz používá grep na systémový soubor. Když je nalezeno slovo „Adam“, můžeme vidět řádek jako výstup. Můžeme provést stejné vyhledávání pro jakýkoli jiný prvek v souboru.
Závěr
Regex spolu s příkazem grep může být velmi silný. Regex je studován jako samostatný obor v informatice a lze jej použít k porovnání vysoce složitých vzorů. Další informace o regulárním výrazu naleznete zde.