Pokud vás nebaví, že vaše Bash skripty běží věčně, tento tutoriál je pro vás. Často můžete Bash skripty paralelně, což může výrazně urychlit výsledek. Jak? Použití nástroje GNU Parallel, také nazývaného Parallel, s několika praktickými příklady GNU Parallel!
Parallel spouští Bash skripty paralelně prostřednictvím konceptu zvaného multi-threading. Tento nástroj vám umožňuje spouštět různé úlohy na procesor namísto pouze jedné, čímž zkracuje čas potřebný ke spuštění skriptu.
V tomto tutoriálu se naučíte vícevláknové Bash skripty se spoustou skvělých příkladů GNU Parallel!
Předpoklady
Tento tutoriál bude plný praktických ukázek. Pokud máte v úmyslu pokračovat, ujistěte se, že máte následující:
- Počítač se systémem Linux. Jakákoli distribuce bude fungovat. Výukový program používá Ubuntu 20.04 běžící na Windows Subsystem for Linux (WSL).
- Přihlášen s uživatelem s právy sudo.
Instalace GNU Parallel
Chcete-li začít zrychlovat skripty Bash pomocí multithreadingu, musíte nejprve nainstalovat Parallel. Začněme tedy stažením a instalací.
1. Otevřete terminál Bash.
2. Spusťte wget ke stažení balíčku Parallel. Níže uvedený příkaz stáhne nejnovější verzi (parallel-latest ) do aktuálního pracovního adresáře.
wget https://ftp.gnu.org/gnu/parallel/parallel-latest.tar.bz2Pokud byste raději používali starší verzi GNU Parallel, všechny balíčky najdete na oficiálních stránkách ke stažení.
3. Nyní spusťte níže uvedený příkaz tar a zrušte archivaci balíčku, který jste právě stáhli.
Níže uvedený příkaz používá x příznak pro rozbalení archivu, j určit, že cílí na archiv s .bz2 rozšíření a f přijmout soubor jako vstup do příkazu tar. sudo tar -xjf parallel-latest.tar.bz2
sudo tar -xjf parallel-latest.tar.bz2Nyní byste měli mít adresář s názvem paralelní- s měsícem, dnem a rokem posledního vydání.
4. Přejděte do složky archivu balíčku pomocí cd . V tomto kurzu se složka archivu balíčků nazývá paralelní-20210422 , Jak je ukázáno níže.
5. Dále sestavte a nainstalujte binární soubor GNU Parallel spuštěním následujících příkazů:
./configure
make
make installNyní ověřte, zda se Parallel správně nainstaloval kontrolou verze, která je nainstalovaná.
parallel --version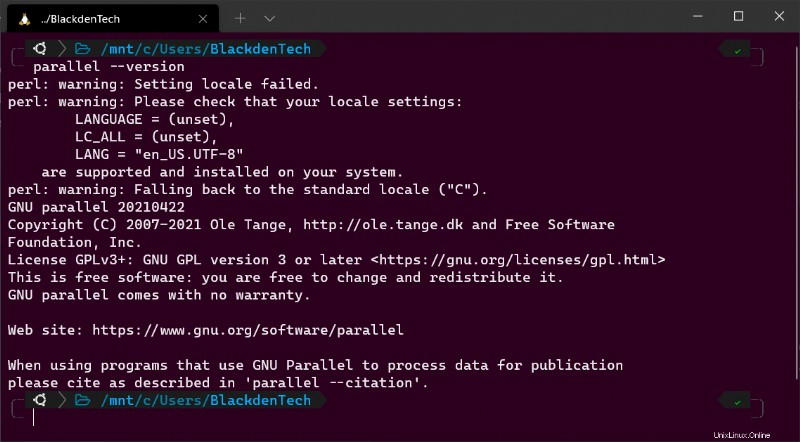
Při prvním spuštění Parallel se také může zobrazit několik děsivých řádků, které zobrazují text jako
perl: warning:. Tyto varovné zprávy znamenají, že Parallel nemůže zjistit vaše aktuální nastavení národního prostředí a jazyka. Ale s těmito varováními se zatím netrapte. Později se dozvíte, jak tato upozornění opravit.
Konfigurace GNU Parallel
Nyní, když je Parallel nainstalován, můžete jej okamžitě používat! Nejprve je však důležité nakonfigurovat několik drobných nastavení, než začnete.
Zatímco jste stále ve svém terminálu Bash, odsouhlaste povolení pro akademický výzkum GNU Parallel a sdělte Parallel, že jej budete citovat v jakémkoli akademickém výzkumu zadáním citation parametr následovaný will cite .
Pokud nechcete podporovat GNU nebo jeho správce, souhlas s citací není pro použití GNU Parallel vyžadován.
parallel --citation
will citeZměňte národní prostředí nastavením následujících proměnných prostředí spuštěním řádků kódu níže. Nastavení proměnných národního prostředí a jazykového prostředí, jako je toto, není podmínkou. Ale GNU Parallel je kontroluje při každém spuštění.
Pokud proměnné prostředí neexistují, Parallel si na ně bude stěžovat pokaždé, jak jste viděli v předchozí části.
Tento výukový program předpokládá, že mluvíte anglicky. Podporovány jsou i další jazyky.
export LC_ALL=C man
export LANGUAGE=en_US
export LANG=en_US.UTF-8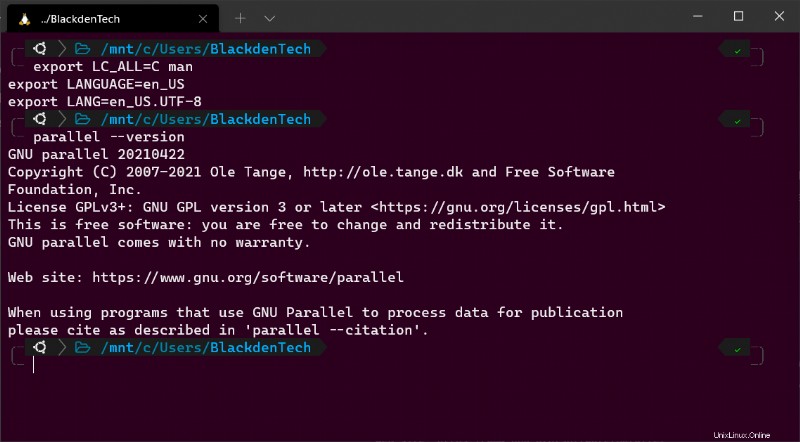
Spouštění ad-hoc příkazů shellu
Pojďme nyní začít používat GNU Parallel! Pro začátek se naučíte základní syntaxi. Jakmile se se syntaxí seznámíte, později se dostanete k několika praktickým příkladům GNU Parallel.
Pro začátek si uveďme super jednoduchý příklad pouhého opakování čísel 1-5.
1. V terminálu Bash spusťte následující příkazy. Vzrušující, že? Bash používá příkaz echo k odeslání čísel 1-5 do terminálu. Pokud byste každý z těchto příkazů vložili do skriptu, Bash by každý z nich provedl postupně a čekal na dokončení předchozího.
V tomto příkladu provádíte pět příkazů, které nezaberou téměř žádný čas. Představte si však, že by tyto příkazy byly skripty Bash skutečně udělaly něco užitečného, ale jejich spuštění trvalo věčnost?
echo 1
echo 2
echo 3
echo 4
echo 5
Nyní spusťte každý z těchto příkazů současně s Parallel, jak je uvedeno níže. V tomto příkladu Parallel spustí příkaz echo a je označen ::: , předá tomuto příkazu argumenty 1 , 2 , 3 , 4 , 5 . Tři dvojtečky sdělují Parallelu, že poskytujete vstup prostřednictvím příkazového řádku, nikoli kanálu (více později).
V níže uvedeném příkladu jste předali jeden příkaz do Parallel bez možností. Zde, stejně jako všechny příklady Parallel, Parallel zahájil nový proces pro každý příkaz pomocí jiného jádra CPU.
# From the command line
parallel echo ::: 1 2 3 4 5Všechny paralelní příkazy mají syntaxi
parallel [Options].
3. Chcete-li předvést paralelní příjem vstupu z kanálu Bash, vytvořte soubor s názvem count_file.txt jako níže. Každé číslo představuje argument, který předáte příkazu echo.
1
2
3
4
5
4. Nyní spusťte cat pro přečtení tohoto souboru a předání výstupu do Parallel, jak je znázorněno níže. V tomto příkladu {} představuje každý argument (1-5), který bude předán Parallel.
# From the pipeline cat count_file.txt | parallel echo {}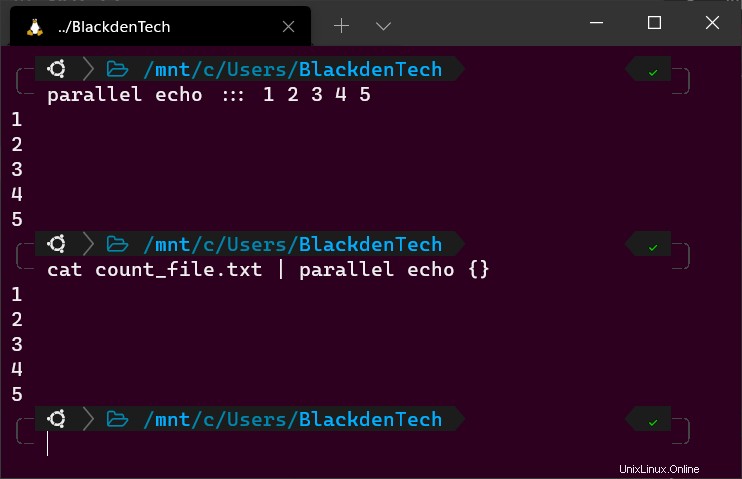
Porovnání Bash a GNU Parallel
Právě teď se může použití Parallel zdát jako komplikovaný způsob spouštění příkazů Bash. Ale skutečným přínosem pro vás je úspora času. Pamatujte, že Bash poběží pouze na jednom jádru CPU, zatímco GNU Parallel poběží na několika najednou.
1. Chcete-li demonstrovat rozdíl mezi sekvenčními příkazy Bash a paralelními, vytvořte skript Bash s názvem test.sh s následujícím kódem. Vytvořte tento skript ve stejném adresáři, ve kterém jste vytvořili count_file.txt dříve.
Bash skript níže čte count_file.txt soubor, uspí na 1, 2, 3, 4 a 5 sekund, odešle délku spánku do terminálu a ukončí se.
#!/bin/bash
nums=$(cat count_file.txt) # Read count_file.txt
for num in $nums # For each line in the file, start a loop
do
sleep $num # Read the line and wait that many seconds
echo $num # Print the line
done
2. Nyní spusťte skript pomocí time příkaz k měření, jak dlouho trvá dokončení skriptu. Bude to trvat 15 sekund.
time ./test.sh
3. Nyní použijte time příkaz znovu k provedení stejného úkolu, ale tentokrát k tomu použijte Parallel.
Níže uvedený příkaz provede stejnou úlohu, ale tentokrát místo čekání na dokončení první smyčky před spuštěním další spustí jednu na každém jádru CPU a spustí jich tolik, kolik může současně.
time cat count_file.txt | parallel "sleep {}; echo {}"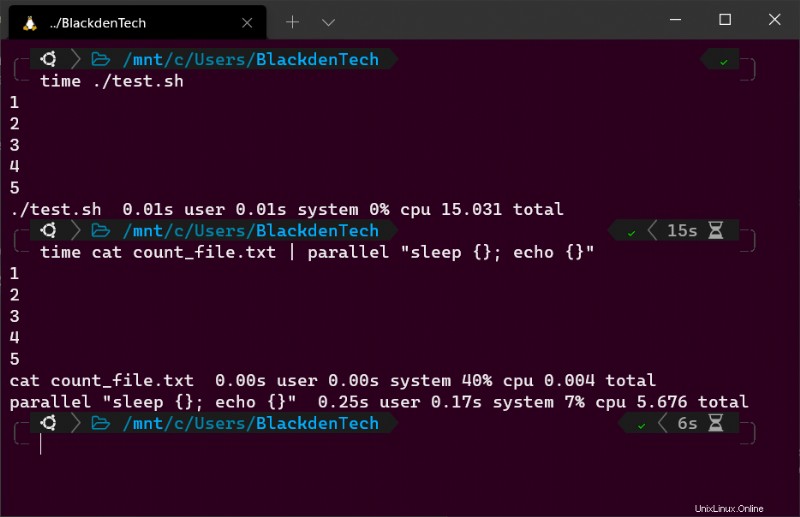
Poznejte běh na sucho!
Nyní je čas dostat se do několika reálných příkladů GNU Parallel. Ale než to uděláte, měli byste nejprve vědět o --dryrun vlajka. Tento příznak se hodí, když chcete vidět, co se stane, aniž by to Parallel skutečně dělal.
--dryrun příznak může být poslední kontrolou zdravého rozumu před spuštěním příkazu, který se nechová tak, jak jste si mysleli. Bohužel, pokud zadáte příkaz, který by poškodil váš systém, jediná věc, kterou vám GNU Parallel pomůže udělat, je poškodit jej rychleji!
parallel --dryrun "rm rf {}"Příklad GNU Parallel #1:Stahování souborů z webu
Pro tento úkol si stáhnete seznam souborů z různých URL na webu. Tyto adresy URL mohou například představovat webové stránky, které chcete uložit, obrázky nebo dokonce seznam souborů z FTP serveru.
V tomto příkladu si stáhnete seznam archivních balíčků (a souborů SIG) z FTP serveru GNU parallel.
1. Vytvořte soubor s názvem download_items.txt uchopte nějaké odkazy ke stažení z oficiální stránky pro stahování a přidejte je do souboru odděleného novým řádkem.
https://ftp.gnu.org/gnu/parallel/parallel-20120122.tar.bz2
https://ftp.gnu.org/gnu/parallel/parallel-20120122.tar.bz2.sig
https://ftp.gnu.org/gnu/parallel/parallel-20120222.tar.bz2
https://ftp.gnu.org/gnu/parallel/parallel-20120222.tar.bz2.sigMůžete ušetřit čas, když použijete knihovnu Python’s Beautiful Soup k odstranění všech odkazů ze stránky stahování.
2. Přečtěte si všechny adresy URL ze souboru download_items.txt soubor a předejte je Parallel, který vyvolá wget a předat každou adresu URL.
cat download_items.txt | parallel wget {}Nezapomeňte, že
{}v paralelním příkazu je zástupný symbol pro vstupní řetězec!
3. Možná potřebujete ovládat počet vláken, která GNU Parallel používá najednou. Pokud ano, přidejte --jobs nebo -j parametr k příkazu. --jobs omezuje počet vláken, která mohou běžet souběžně, na počet, který zadáte.
Chcete-li například omezit Parallel na stahování pěti adres URL najednou, příkaz by vypadal takto:
#!/bin/bash
cat download_items.txt | parallel --jobs 5 wget {}
--jobsParametr ve výše uvedeném příkazu lze upravit tak, aby stahoval libovolný počet souborů, pokud má počítač, na kterém běžíte, tolik procesorů k jejich zpracování.
4. Demonstrovat účinek --jobs Nyní upravte počet úloh a spusťte time příkaz k měření, jak dlouho každý běh trvá.
time cat download_items.txt | parallel --jobs 5 wget {}
time cat download_items.txt | parallel --jobs 10 wget {}Příklad GNU Parallel č. 2:Rozbalení archivních balíčků
Nyní, když máte všechny tyto archivní soubory stažené z předchozího příkladu, musíte je zrušit.
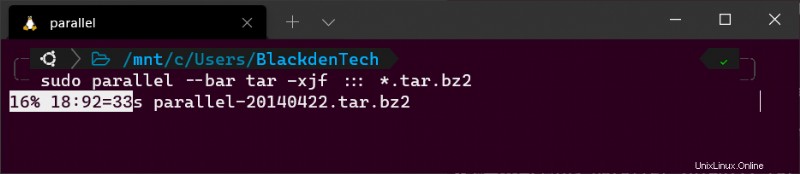
Ve stejném adresáři jako archivní balíčky spusťte následující příkaz Parallel. Všimněte si použití zástupného znaku (* ). Protože tento adresář obsahuje oba archivní balíčky a soubory SIG, musíte Parallel sdělit, aby zpracovával pouze .tar.bz2 soubory.
sudo parallel tar -xjf ::: *.tar.bz2
Bonus! Pokud používáte paralelně GNU interaktivně (ne ve skriptu), přidejte --bar příznak, aby vám Parallel zobrazoval ukazatel průběhu, když je úloha spuštěna.
Příklad GNU Parallel č. 3:Odebírání souborů
Pokud jste postupovali podle příkladů 1 a 2, měli byste nyní mít ve svém pracovním adresáři mnoho složek, které zabírají místo. Odstraňme tedy všechny tyto soubory paralelně!
Chcete-li odstranit všechny složky, které začínají paralelně- pomocí Parallel vypište všechny složky s ls -d a přesměrování každé z těchto cest složek do Parallel, vyvoláním rm -rf v každé složce, jak je uvedeno níže.
Pamatujte na
--dryrunvlajka!
ls -d parallel-*/ | parallel "rm -rf {}"Závěr
Nyní můžete automatizovat úkoly pomocí Bash a ušetřit si spoustu času. Je jen na vás, co s tím časem uděláte. Ať už úspora času znamená odejít z práce o něco dříve, nebo si přečíst další příspěvek na blogu ATA, dnes je čas zpět.
Nyní se zamyslete nad všemi dlouhodobě běžícími skripty ve vašem prostředí. Které z nich můžete urychlit pomocí Parallel?