Potřebujete streamovací platformu pro zpracování velkého množství dat? O Apache Kafka na Linuxu jste nepochybně slyšeli. Apache Kafka je ideální pro zpracování dat v reálném čase a je stále populárnější. Instalace Apache Kafka na Linux může být trochu složitější, ale žádný strach, tento tutoriál vám poradí.
V tomto tutoriálu se naučíte instalovat a konfigurovat Apache Kafka, abyste mohli začít zpracovávat svá data jako profesionál, díky čemuž bude vaše podnikání efektivnější a produktivnější.
Čtěte dál a začněte streamovat data s Apache Kafka ještě dnes!
Předpoklady
Tento tutoriál bude praktickou ukázkou. Pokud je chcete sledovat, ujistěte se, že máte následující.
- Počítač Linux – Tato ukázka používá Debian 10, ale bude fungovat jakákoli distribuce Linuxu.
- Uživatelský účet bez oprávnění root s právy sudo, nezbytnými ke spuštění Kafka, a pojmenovaný
kafkav tomto tutoriálu. - Vyhrazený uživatel sudo pro Kafka – Tento výukový program používá uživatele sudo zvaného kafka.
- Java – Java je nedílnou součástí instalace Apache Kafka.
- Git – Tento tutoriál používá Git ke stažení souborů Apache Kafka Unit.
Instalace Apache Kafka
Před streamováním dat musíte nejprve nainstalovat Apache Kafka do svého počítače. Vzhledem k tomu, že máte vyhrazený účet pro Kafku, můžete si nainstalovat Kafka, aniž byste se museli obávat rozbití vašeho systému.
1. Spusťte mkdir příkaz níže k vytvoření /home/kafka/Downloads adresář. Adresář můžete pojmenovat jak chcete, ale adresář se nazývá Stahování pro toto demo. V tomto adresáři budou uloženy binární soubory Kafka. Tato akce zajistí, že všechny vaše soubory pro Kafku budou k dispozici kafka uživatel.
mkdir Downloads
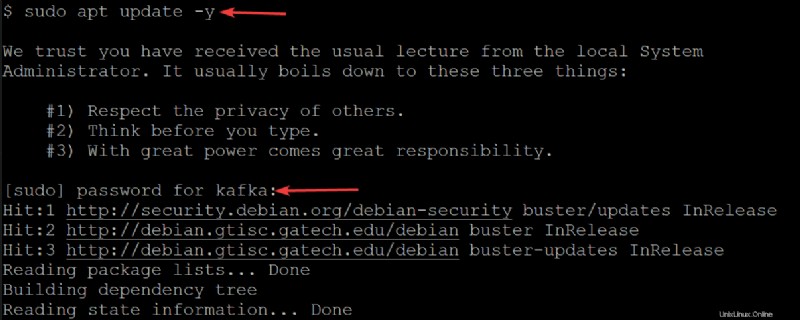
2. Dále spusťte níže uvedený apt update příkaz k aktualizaci indexu balíků vašeho systému.
sudo apt update -yAž budete vyzváni, zadejte heslo pro svého uživatele kafka.
3. Spusťte curl příkaz níže ke stažení binárních souborů Kafka z webu Apache Foundation pro výstup (-o ) do binárního souboru (kafka.tgz ) ve vašem ~/Downloads adresář. Tento binární soubor použijete k instalaci Kafky.
Nezapomeňte nahradit kafka/3.1.0/kafka_2.13-3.1.0.tgz nejnovější verzí binárních souborů Kafka. V době psaní tohoto článku je aktuální verze Kafky 3.1.0.
curl "https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz" -o ~/Downloads/kafka.tgz
4. Nyní spusťte tar příkaz níže k extrahování (-x ) binární soubory Kafka (~/Downloads/kafka.tgz ) do automaticky vytvořené kafky adresář. Možnosti v tar proveďte následující:
Možnosti v tar proveďte následující:
-v– Řeknetarpříkaz k zobrazení seznamu všech souborů, jak jsou extrahovány.
-z– Řeknetarpříkaz gzip archiv při jeho dekomprimaci. Toto chování není v tomto případě vyžadováno, ale je to vynikající volba, zvláště pokud potřebujete rychle komprimovaný/zipovaný soubor, abyste se mohli pohybovat.
-f– Řeknetarpříkaz, který archivní soubor rozbalit.
-strip 1-Pokynetarpříkaz k odstranění první úrovně adresářů ze seznamu názvů souborů. V důsledku toho automaticky vytvořte podadresář s názvem kafka obsahující všechny extrahované soubory z~/Downloads/kafka.tgzsoubor.
tar -xvzf ~/Downloads/kafka.tgz --strip 1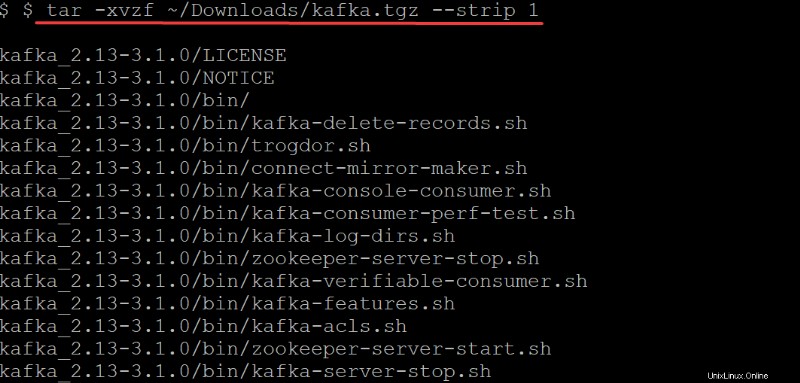
Konfigurace serveru Apache Kafka
V tuto chvíli jste si stáhli a nainstalovali binárky Kafka do svých ~/Stažených souborů adresář. Server Kafka zatím nemůžete používat, protože ve výchozím nastavení vám Kafka neumožňuje mazat ani upravovat žádná témata, což je kategorie nezbytná k uspořádání zpráv protokolu.
Chcete-li nakonfigurovat svůj server Kafka, budete muset upravit konfigurační soubor Kafka (/etc/kafka/server.properties).
1. Otevřete konfigurační soubor Kafka (/etc/kafka/server.properties ) ve vašem preferovaném textovém editoru.
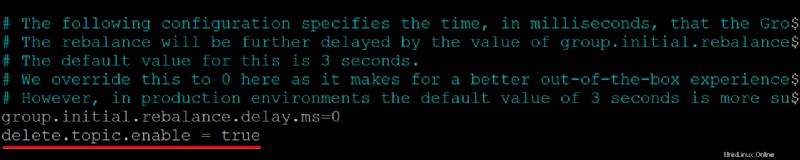
2. Dále přidejte delete.topic.enable =true řádek v dolní části /kafka/config/server.properties obsah souboru, uložte změny a zavřete editor.
Tato konfigurační vlastnost vám dává oprávnění mazat nebo upravovat témata, takže se ujistěte, že víte, co děláte, než témata smažete. Smazáním tématu se odstraní i oddíly pro toto téma. Jakákoli data uložená v těchto oddílech již nejsou přístupná, jakmile budou pryč.
Ujistěte se, že na začátku každého řádku nejsou žádné mezery, jinak nebude soubor rozpoznán a váš server Kafka nebude fungovat.
3. Spusťte git příkaz níže na clone ata-kafka projekt na váš místní počítač, abyste jej mohli upravit pro použití jako soubor jednotky pro vaši službu Kafka.
sudo git clone https://github.com/Adam-the-Automator/apache-kafka.git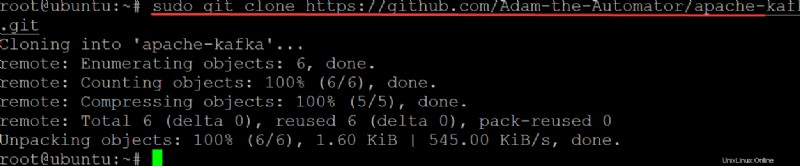
Nyní spusťte níže uvedené příkazy a přejděte do apache-kafka adresář a seznam souborů uvnitř.
cd apache-kafka
lsNyní, když jste v ata-kafka adresář, můžete vidět, že uvnitř máte dva soubory:kafka.service a zookeeper.service, jak je ukázáno níže.

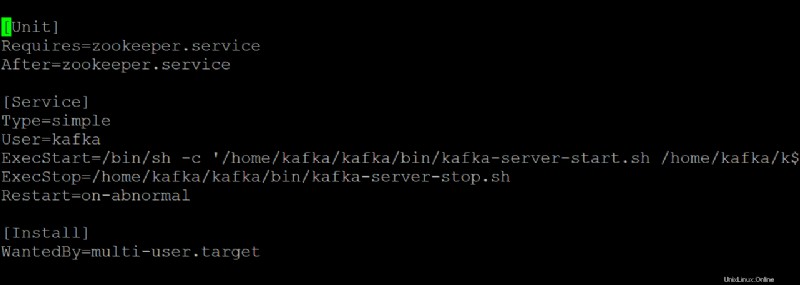
5. Otevřete zookeeper.service soubor ve vašem preferovaném textovém editoru. Tento soubor použijete jako referenci k vytvoření kafka.service soubor.
Přizpůsobte si každou sekci níže v zookeeper.service soubor, podle potřeby. Ale toto demo používá tento soubor tak, jak je, bez úprav.
[Unit]sekce konfiguruje vlastnosti spuštění pro tuto jednotku. Tato část říká systemd, co má použít při spuštění služby zookeeper.
- Sekce [Service] definuje, jak, kdy a kde spustit službu Kafka pomocí kafka-server-start.sh skript. Tato část také definuje základní informace, jako je název, popis a argumenty příkazového řádku (co následuje po ExecStart=).
[Install]sekce nastavuje úroveň běhu pro spuštění služby při vstupu do režimu pro více uživatelů.
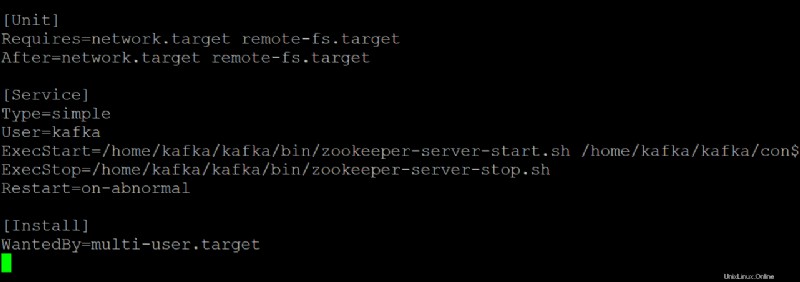
6. Otevřete kafka.service soubor ve vašem preferovaném textovém editoru a nakonfigurujte, jak váš server Kafka vypadá, když běží jako služba systemd.
Tato ukázka používá výchozí hodnoty, které jsou v kafka.service soubor, ale soubor můžete upravit podle potřeby. Upozorňujeme, že tento soubor odkazuje na zookeeper.service soubor, který můžete v určitém okamžiku upravit.
7. Spusťte níže uvedený příkaz na start kafka servis.
sudo systemctl start kafkaNezapomeňte zastavit a spustit svůj server Kafka jako službu. Pokud tak neučiníte, proces zůstane v paměti a proces můžete zastavit pouze tím, že ho zabijete. Toto chování může vést ke ztrátě dat, pokud máte témata, která se zapisují nebo aktualizují při ukončení procesu.
Protože jste vytvořili kafka.service a zookeeper.service soubory, můžete také spustit některý z níže uvedených příkazů a zastavit nebo restartovat svůj server Kafka založený na systému.
sudo systemctl stop kafka
sudo systemctl restart kafka
8. Nyní spusťte journalctl níže, abyste ověřili, že se služba úspěšně spustila.
Tento příkaz zobrazí seznam všech protokolů služby kafka.
sudo journalctl -u kafkaPokud jste vše nakonfigurovali správně, zobrazí se zpráva Started kafka.service, jak je uvedeno níže. Gratulujeme! Nyní máte plně funkční server Kafka, který poběží jako systémové služby.

Omezení uživatele služby Kafka
V tomto okamžiku služba Kafka běží jako uživatel kafka. Uživatel kafka je uživatel na systémové úrovni a neměl by být vystaven uživatelům, kteří se připojují ke službě Kafka.
Každý klient, který se připojí ke Kafce prostřednictvím tohoto zprostředkovatele, bude mít v počítači zprostředkovatele efektivně přístup na úrovni root, což se nedoporučuje. Ke zmírnění rizika odeberete uživatele kafka ze souboru sudoers a deaktivujete heslo pro uživatele kafka.
1. Spusťte exit příkazem níže přepnete zpět na svůj normální uživatelský účet.
exit
2. Dále spusťte sudo deluser kafka sudo a stiskněte Enter potvrďte, že chcete odstranit kafka uživatel ze sudoers.
sudo deluser kafka sudo
3. Spuštěním níže uvedeného příkazu deaktivujte heslo pro uživatele kafka. Tím dále zlepšíte zabezpečení vaší instalace Kafka.
sudo passwd kafka -l
4. Nyní znovu spusťte následující příkaz k odstranění uživatele kafka ze seznamu sudoers.
sudo deluser kafka sudo
5. Spusťte níže uvedený su příkaz k nastavení pouze oprávněným uživatelům, jako jsou uživatelé root, mohou spouštět příkazy jako kafka uživatel.
sudo su - kafka
6. Dále spusťte níže uvedený příkaz a vytvořte nové téma Kafka s názvem ATA abyste ověřili, že váš server Kafka funguje správně.
Kafka témata jsou kanály zpráv na/ze serveru, což pomáhá eliminovat komplikace spojené s chaotickými a neuspořádanými daty na serverech Kafka
cd /usr/local/kafka-server && bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic ATA
7. Spusťte níže uvedený příkaz a vytvořte producenta Kafka pomocí kafka-console-producer.sh skript. Producenti Kafky píší data k tématům.
echo "Hello World, this sample provided by ATA" | bin/kafka-console-producer.sh --broker-list localhost:9092 --topic ATA > /dev/null
8. Nakonec spusťte níže uvedený příkaz a vytvořte spotřebitele kafka pomocí kafka-console-consumer.sh skript. Tento příkaz spotřebovává všechny zprávy v tématu kafka (--topic ATA ) a poté vytiskne hodnotu zprávy.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic ATA --from-beginningZprávu uvidíte ve výstupu níže, protože vaše zprávy vytiskl uživatel konzole Kafka z tématu ATA Kafka, jak je uvedeno níže. Spotřebitelský skript pokračuje v tomto okamžiku a čeká na další zprávy.
Po dokončení testování můžete otevřít jiný terminál a přidat další zprávy do svého tématu a stisknutím Ctrl+C zastavit spotřebitelský skript.

Závěr
V tomto tutoriálu jste se naučili nastavit a nakonfigurovat Apache Kafka na vašem počítači. Dotkli jste se také konzumace zpráv z tématu Kafka vytvořeného producentem Kafka, což vedlo k efektivní správě protokolu událostí.
Proč na těchto nově nabytých znalostech nevyužít instalaci Kafka s Flume, abyste mohli lépe distribuovat a spravovat své zprávy? Můžete také prozkoumat Kafka’s Streams API a vytvářet aplikace, které čtou a zapisují data do Kafky. Tím se data podle potřeby transformují, než je zapíšou do jiného systému, jako je HDFS, HBase nebo Elasticsearch.