Úvod
MySQL je databázová aplikace, která ukládá data do řádků a sloupců různých tabulek, aby se zabránilo duplicitě. Mohou se vyskytnout duplicitní hodnoty, což může ovlivnit výkon MySQL.
Tento průvodce vám ukáže, jak najít duplicitní hodnoty v databázi MySQL .

Předpoklady
- Stávající instalace MySQL
- Přihlašovací údaje k uživatelskému účtu root pro MySQL
- Příkazový řádek / okno terminálu
Nastavení vzorové tabulky (volitelné)
Tento krok vám pomůže vytvořit vzorovou tabulku, se kterou budete pracovat. Pokud již máte databázi, na které můžete pracovat, přejděte k další části.
Otevřete okno terminálu a přepněte se do prostředí MySQL:
mysql –u root –pSeznam existujících databází:
SHOW databases;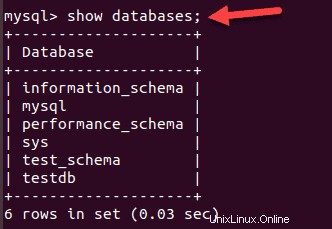
Vytvořte novou databázi, která ještě neexistuje:
CREATE database sampledb;Vyberte tabulku, kterou jste právě vytvořili:
USE sampledb;Vytvořte novou tabulku s následujícími poli:
CREATE TABLE dbtable (
id INT PRIMARY KEY AUTO_INCREMENT,
date_x VARCHAR(10) NOT NULL,
system_x VARCHAR(50) NOT NULL,
test VARCHAR(50) NOT NULL
);Vložení řádků do tabulky:
INSERT INTO dbtable (date_x,system_x,test)
VALUES ('01/03/2020','system1','hard_drive'),
('01/04/2020','system2','memory'),
('01/10/2020','system2','processor'),
('01/14/2020','system3','hard drive'),
('01/10/2020','system2','processor'),
('01/20/2020','system4','hard drive'),
('01/24/2020','system5','memory'),
('01/29/2020','system6','hard drive'),
('02/02/2020','system7','motherboard'),
('02/04/2020','system8','graphics card'),
('02/02/2020','system7','motherboard'),
('02/08/2020','system9','hard drive');Spusťte následující dotaz SQL:
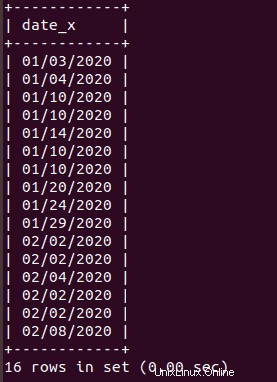
SELECT * FROM dbtable
ORDER BY date_x;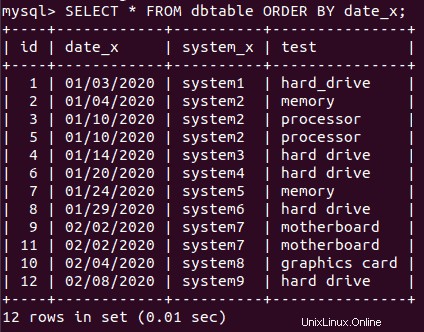
Hledání duplikátů v MySQL
Najděte duplicitní hodnoty v jednom sloupci
Použijte GROUP BY funkce k identifikaci všech identických záznamů v jednom sloupci. Pokračujte pomocí COUNT() HAVING funkce pro zobrazení všech skupin s více než jedním záznamem.
SELECT
test,
COUNT(test)
FROM
dbtable
GROUP BY test
HAVING COUNT(test) > 1;
Najít duplicitní hodnoty ve více sloupcích
Možná budete chtít uvést přesné duplikáty se stejnými informacemi ve všech třech sloupcích.
SELECT
date_x, COUNT(date_x),
system_x, COUNT(system_x),
test, COUNT(test)
FROM
dbtable
GROUP BY
date_x,
system_x,
test
HAVING COUNT(date_x)>1
AND COUNT(system_x)>1
AND COUNT(test)>1;

Tento dotaz funguje tak, že vybere a otestuje >1 stav na všech třech sloupcích. Výsledkem je, že ve výstupu jsou vráceny pouze řádky s duplicitními hodnotami.
Kontrola duplikátů ve více tabulkách pomocí INNER JOIN
Použijte funkci INNER JOIN k nalezení duplikátů, které existují ve více tabulkách.
Ukázka syntaxe pro INNER JOIN funkce vypadá takto:
SELECT column_name
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column name;
K otestování tohoto příkladu potřebujete druhou tabulku, která obsahuje některé informace duplikované z sampledb tabulku, kterou jsme vytvořili výše.
SELECT dbtable.date_x
FROM dbtable
INNER JOIN new_table
ON dbtable.date_x = new_table.date_x;
Zobrazí se všechna duplicitní data, která existují mezi existujícími daty a new_table .