Úvod
Redis je pozoruhodně rychlé, nerelační databázové řešení. Jeho jednoduchý datový model klíč–hodnota umožňuje společnosti Redis pracovat s velkými datovými sadami při zachování působivé rychlosti čtení a zápisu a dostupnosti.
Redis vám umožňuje používat různé typy dat, jako jsou seznamy, hashe, sady a tříděné sady, k ukládání a správě dat.
V tomto kurzu se dozvíte, jak Datové typy Redis pracovat a ovládat základní příkazy pro každý typ dat.
Datové typy Redis
Databáze klíč-hodnota strukturuje data použitím jedinečného klíče na každý datový objekt. Použijte klíč ke správě a načítání hodnot přiřazených tomuto konkrétnímu klíči. Libovolná binární sekvence o velikosti až 512 MB může být použita jako klíč Redis a poté spojena s jednoduchými řetězci nebo jinými abstraktními datovými strukturami.
Klíče Redis jsou mapovány na hodnoty pomocí jednoho ze sedmi různých datových typů:
- Řetězce
- Seznamy
- Hashes
- Sady
- Seřazené sady
- HyperLogLogs
- Bitmapy (BitStrings)
Každý datový typ Redis má vlastní sadu příkazů pro vzory rutinního přístupu, podporu transakcí a hromadné operace, pokud nemáte nainstalovaný Redis, použijte naše podrobné průvodce k instalaci Redis na Ubuntu nebo nasazení Redis na Docker.
Řetězce
Řetězec představuje nejmenší hodnotu, kterou můžete ke klíči připojit. Maximální povolená velikost hodnoty řetězce je 512 MB, která obsahuje libovolnou sekvenci znaků. V Redis je klíčovou částí páru klíč–hodnota také řetězec.
Databáze využívající tento typ datové struktury se často označují jako úložiště klíč-hodnota typu řetězec-řetězec.
Se všemi daty v jediném objektu jsou operace s řetězci v Redis extrémně rychlé. Základní příkazy Redis jako SET , GET a DEL vám umožní provádět základní operace s hodnotou řetězce.
SET key value– Nastaví hodnotu pro zadaný klíč.GET key– Načte hodnotu pro zadaný klíč.DEL key– Odstraní hodnotu pro daný klíč.
Následující příklad ukazuje, jak používat tyto jednoduché příkazy v redis-cli interaktivní shell. SET příkaz přidá hodnotu do klíče, zatímco GET příkaz načte a zobrazí hodnotu. Pokud ke klíči není namapována žádná hodnota, zobrazí se GET výstup příkazu je (nil) .

Pokud hodnota existuje, výstup pro DEL příkaz zobrazuje počet položek, které se mají smazat. Přidání nových klíčů a hodnot neovlivní výkon databáze ani rychlost zpracování.
Seznamy
Redis umožňuje přiřadit klíči uspořádanou sekvenci řetězců. Tento propojený seznam řetězců umožňuje provádět řadu operací, například:
LPUSH– Přesune hodnotu na levý konec seznamu.RPUSH– Přesune hodnotu na konec seznamu.LRANGE– Načte řadu položek.LPOP/RPOP– Používá se k zobrazení a odstranění položek z obou konců.LINDEX– Získejte hodnotu z konkrétní pozice v seznamu.
Při přidávání hodnot do seznamu pomocí LPUSH/RPUSH příkazů, výstup poskytuje aktuální počet položek. Celý seznam pak můžete načíst pomocí LRANGE příkaz s 0 jako začátek a -1 označující poslední položku indexu.
Načtěte konkrétní hodnotu z propojeného seznamu pomocí LINDEX příkaz nebo odstranění položek pomocí LPOP/RPOP příkaz.
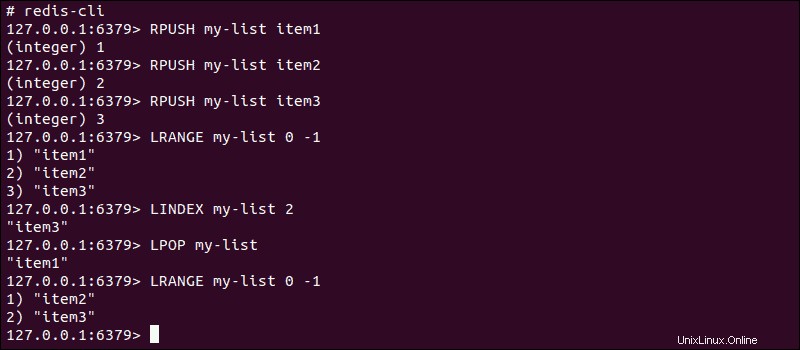
Přidávání hodnot do propojeného seznamu je efektivní operace, která neovlivňuje rychlost zápisu bez ohledu na jeho velikost. Čtení dat z propojeného seznamu však může záviset na počtu řetězců na straně hodnoty páru klíč–hodnota.
Haše
Hash Redis ukládá neuspořádané mapování párů klíč–hodnota. Klíč hash je spojen s hodnotou. Hodnota je řetězec Redis, který obsahuje další páry klíč–hodnota. Jako hodnoty nemůžete použít jiné složité datové struktury, jako jsou sady, seznamy nebo jiné hashe.
Základní hashovací příkazy vám umožňují přistupovat a měnit jednotlivá nebo více polí nezávisle.
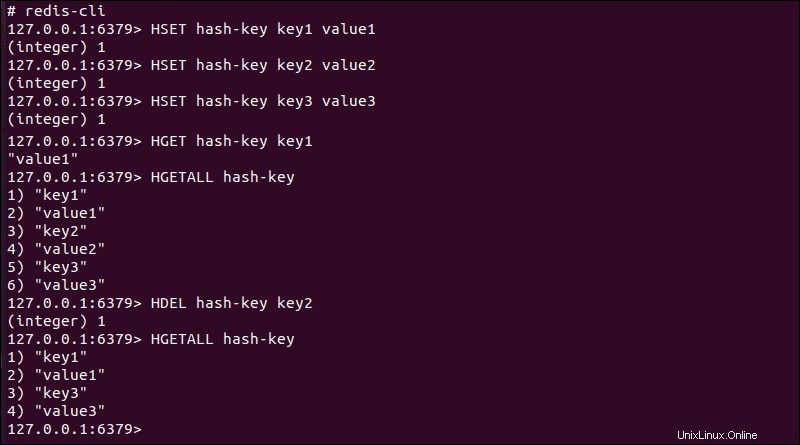
HSET– Mapujte hodnotu na klíč v rámci hash.HGET– Načte jednotlivé hodnoty spojené s klíčem v rámci hash.HGETALL– Zobrazí celý obsah hash.HDEL– Odebere existující pár klíč–hodnota z hash.
Pokaždé, když je položka přidána do hash pomocí HSET příkaz, návratová hodnota (integer) n vás informuje, zda záznam již existuje a počet instancí. Stejné informace jsou poskytovány při použití HDEL příkaz.
Sady
Sada Redis je neuspořádaná kolekce jedinečných strun. Vzhledem k tomu, že sady nejsou seřazeny, nelze položky odstraňovat z popředí nebo z konce rejstříku jako u seznamů. Řetězce jsou však jedinečné a není možné, aby se v sadě objevilo více instancí stejné položky.
Použijte následující příkazy přidat, odebrat, načíst a zkontrolovat jednotlivé položky sady:
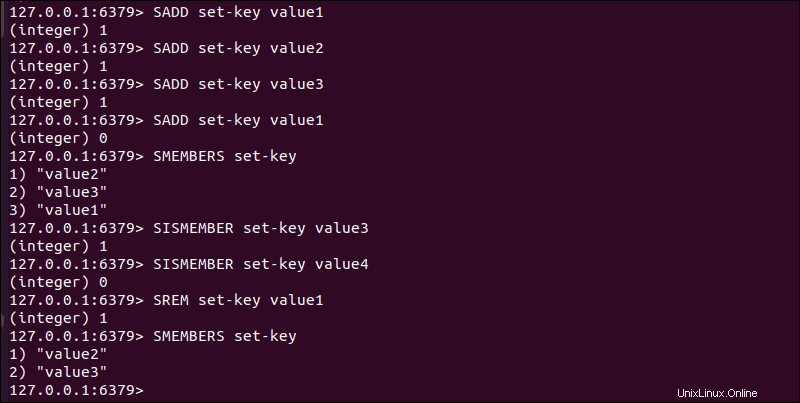
SADD– Přidejte jednu nebo více položek do sady.SISMEMBER– Zjistěte, zda je položka součástí sady.SMEMBERS– Načte všechny položky ze sady.SREM– Odebere existující položku ze sady.
Vícenásobné přidání stejné položky do sady vždy vytvoří jednu kopii. V důsledku toho nemusíte používat SMEMBERS nebo SISMEMBER příkaz k určení, zda je položka již členem sady.
Použijte SADD příkaz, abyste se ujistili, že v sadě nejsou žádné duplicitní položky.
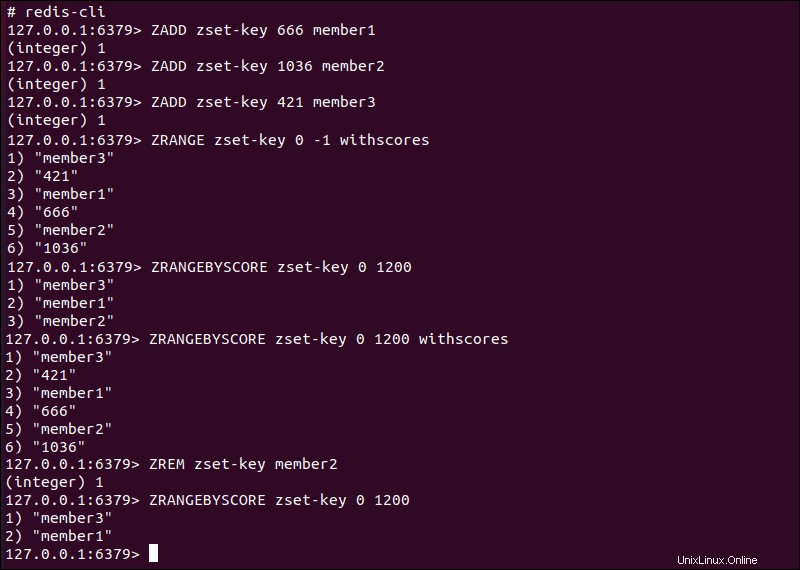
Seřazené sady
Seřazené sady nebo ZSET s jsou jedním z nejpokročilejších datových typů v Redis.
Hodnotová část seřazeného páru klíč–hodnota sady se skládá z jedinečného prvku řetězce (klíče) zvaného člen a položka (hodnota) se nazývá skóre . Seřazené sady mapují každý prvek na hodnotu s plovoucí desetinnou čárkou (skóre ) a použijte tuto hodnotu k řazení prvků v určitém pořadí.
Můžete přistupovat k položkám v seřazených sadách podle člena, seřazeného pořadí a podle hodnot skóre. Základní příkazy vám umožňují načítat, přidávat, odstraňovat jednotlivé hodnoty nebo načítat položky na základě hodnot členů a rozsahů skóre.
ZADD– Přidá člena se skóre do seřazené sady.ZRANGE– Načte položky na základě jejich pozice v seřazeném pořadí.withscoresvolba vytváří skutečné hodnoty skóre.ZRANGEBYSCORE– Načte položky ze setříděné sady na základě definovaného rozsahu skóre.withscoresvolba vytváří skutečné hodnoty skóre.ZREM– Odebere položky ze seřazené sady.
Pouze člen hodnota dvojice člen-skóre je považována za jedinečnou. Pokud spojíte dvě různá skóre stejnému členovi hodnotu, bude v seřazené sadě přítomen pouze nejnovější přírůstek. Pokud dva různí členové mají stejné skóre Redis seřadí hodnoty alfanumericky.
HyperLogLogs
HyperLogLogs poskytují odhadovaný počet jedinečných položek v kolekci. Na rozdíl od jiných řešení se položky v HyperLogLogs nepočítají jednotlivě, protože by to vyžadovalo sledování předchozích položek, aby se stejný prvek nezapočítával dvakrát. Taková operace vyžaduje velikost paměti rovnající se paměti použité k uložení dat.
Struktura HyperLogLog využívá mnohem efektivnější pravděpodobnostní algoritmus která odhaduje velikost sady namísto počítání každé položky. Chybovost odhadu je pod 1 %.
Příkazy HyperLogLog vám umožňují přidávat položky, získávat odhadovaný počet jedinečných položek a vytvářet spojení více HyperLogLogů.
PFADD– Přidejte jeden nebo několik prvků do HyperLogLog.PFCOUNT– Získejte odhadovaný počet jedinečných položek z jednoho HyperLogLog.PFMERGE– Sloučit různé HyperLogLog do jednoho HyperLogLog.
Přesnost výsledků se může lišit v závislosti na velikosti sbírky. Pokud však nepotřebujete přesný počet položek, tato pravděpodobnostní struktura vám umožní využít pouze zlomek paměti, kterou byste jinak potřebovali.
Bitmapy
Řetězec Redis je binární sekvence s maximální velikostí 512 megabajtů. Bitmapy vám umožňují manipulovat s řetězci na bitové úrovni pomocí příslušných příkazů.
SETBIT– Bit je definován nebo vymazán na základě hodnoty 0 nebo 1.GETBIT– Načte bitovou hodnotu pro hodnotu řetězce zadanou klíčem.BITOP– Provádějte bitové operace mezi řetězci.BITPOS– Najděte první bit nastavený na 1 nebo 0 v řetězci.BITCOUNT– Spočítejte počet bitů nastavený na 1 v řetězci.
Možnost manipulovat s kousky řetězce poskytuje výjimečné možnosti úspory místa. Poskytuje také prostředky pro přímý přístup k základním prvkům dat a práci s nimi.