Úvod
Apache Hadoop je výjimečně úspěšný framework, který zvládá řešit řadu problémů, které představují velká data. Toto efektivní řešení distribuuje úložný a výpočetní výkon mezi tisíce uzlů v rámci clusteru. Plně vyvinutá platforma Hadoop zahrnuje kolekci nástrojů, které vylepšují základní rámec Hadoop a umožňují mu překonat jakoukoli překážku.
Základní architektura a role mnoha dostupných nástrojů v ekosystému Hadoop se může ukázat jako komplikovaná pro nováčky.
Tento článek používá spoustu diagramů a přímých popisů, které vám pomohou prozkoumat vzrušující ekosystém Apache Hadoop.

Přehled architektury Hadoop
Velká data se svým obrovským objemem a proměnlivými datovými strukturami zaplavila tradiční síťové rámce a nástroje. Použití vysoce výkonného hardwaru a specializovaných serverů může pomoci, ale jsou neflexibilní a mají značnou cenu.
Hadoop zvládá zpracovávat a ukládat obrovské množství dat pomocí vzájemně propojeného cenově dostupného komoditního hardwaru. Stovky nebo dokonce tisíce nízkonákladových dedikovaných serverů spolupracujících na ukládání a zpracování dat v rámci jediného ekosystému.
The Hadoop Distributed File System (HDFS), YARN a MapReduce jsou srdcem tohoto ekosystému. HDFS je sada protokolů používaných k ukládání velkých souborů dat, zatímco MapReduce efektivně zpracovává příchozí data.
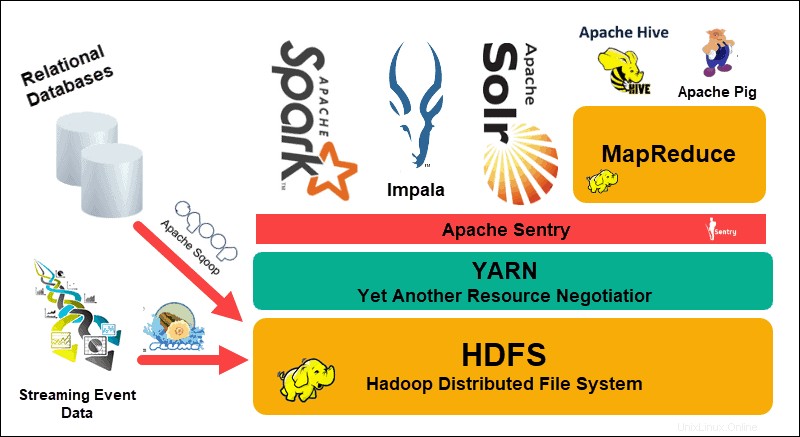
Hadoop cluster se skládá z jednoho nebo několika hlavních uzlů a mnoha dalších takzvaných Slave uzlů. HDFS a MapReduce tvoří flexibilní základ, který lze lineárně škálovat přidáním dalších uzlů. Složitost velkých dat však znamená, že vždy existuje prostor pro zlepšení.
Ještě další vyjednavač zdrojů (YARN) byl vytvořen pro zlepšení správy zdrojů a plánování procesů v clusteru Hadoop. Představení YARN s jeho obecným rozhraním otevřelo dveře dalším nástrojům pro zpracování dat, které mají být začleněny do ekosystému Hadoop.
Živá vývojářská komunita od té doby vytvořila řadu open-source projektů Apache, které doplňují Hadoop. Mnoho z těchto řešení má chytlavé a kreativní názvy jako Apache Hive, Impala, Pig, Sqoop, Spark a Flume. Tyto nástroje kompilují a zpracovávají různé typy dat. Poskytují také uživatelsky přívětivá rozhraní, služby zasílání zpráv a zlepšují rychlost zpracování clusteru.
Rozšířený softwarový balík s HDFS, YARN a MapReduce ve svém jádru dělá z Hadoopu řešení pro zpracování velkých dat.
Porozumění vrstvám architektury Hadoop
Oddělení prvků distribuovaných systémů do funkčních vrstev pomáhá zefektivnit správu a vývoj dat. Vývojáři mohou pracovat na rámcích, aniž by to negativně ovlivnilo jiné procesy v širším ekosystému.
Hadoop lze rozdělit do čtyř (4) odlišných vrstev.
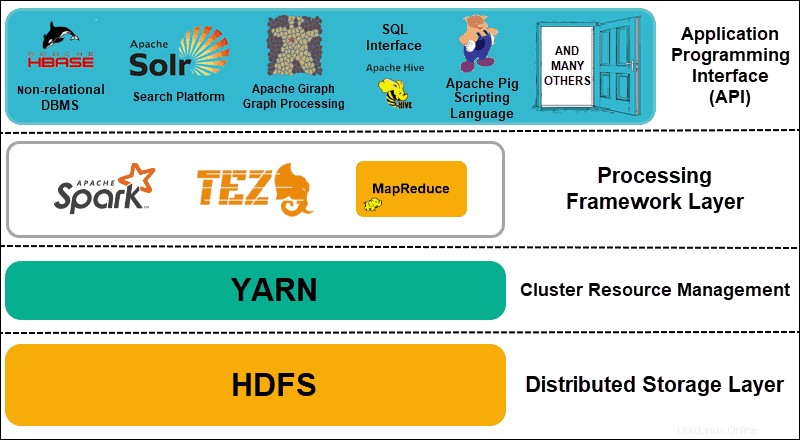
1. Distribuovaná vrstva úložiště
Každý uzel v clusteru Hadoop má svůj vlastní diskový prostor, paměť, šířku pásma a zpracování. Příchozí data jsou rozdělena do jednotlivých datových bloků, které jsou následně uloženy v rámci vrstvy distribuovaného úložiště HDFS. HDFS předpokládá, že každá disková jednotka a podřízený uzel v clusteru jsou nespolehlivé. HDFS jako preventivní opatření ukládá tři kopie každé datové sady v celém clusteru. Hlavní uzel HDFS (NameNode ) uchovává metadata pro jednotlivý datový blok a všechny jeho repliky.
2. Správa zdrojů clusteru
Hadoop potřebuje dokonale koordinovat uzly, aby bezpočet aplikací a uživatelů efektivně sdílelo své zdroje. Zpočátku se MapReduce staral o správu zdrojů i zpracování dat. PŘÍZE tyto dvě funkce odděluje. Jako de facto nástroj pro správu zdrojů pro Hadoop je nyní YARN schopen přidělovat zdroje různým frameworkům napsaným pro Hadoop. Patří mezi ně projekty jako Apache Pig, Hive, Giraph, Zookeeper a také samotný MapReduce.
3. Processing Framework Layer
Zpracovací vrstva se skládá z rámců, které analyzují a zpracovávají datové sady přicházející do clusteru. Strukturované a nestrukturované datové sady jsou mapovány, promíchávány, tříděny, slučovány a redukovány na menší spravovatelné datové bloky. Tyto operace jsou rozmístěny mezi více uzly co nejblíže k serverům, kde jsou data umístěna. Výpočetní rámce jako Spark, Storm, Tez nyní umožňují zpracování v reálném čase, interaktivní zpracování dotazů a další možnosti programování, které pomáhají enginu MapReduce a využívají HDFS mnohem efektivněji.
4. Aplikační programovací rozhraní
Zavedení YARN v Hadoop 2 vedlo k vytvoření nových zpracovatelských rámců a API. Velká data se neustále rozšiřují a tento růst musí sledovat celá řada nástrojů. Projekty, které se zaměřují na vyhledávací platformy, streamování dat, uživatelsky přívětivá rozhraní, programovací jazyky, zasílání zpráv, přepnutí při selhání a zabezpečení, to vše jsou složitou součástí komplexního ekosystému Hadoop.
Vysvětlení HDFS
Hadoop Distributed File System (HDFS) je designově odolný proti chybám. Data jsou uložena v jednotlivých datových blocích ve třech samostatných kopiích napříč více uzly a serverovými racky. Pokud selže uzel nebo dokonce celý rack, dopad na širší systém je zanedbatelný.
Datové uzly zpracovávat a ukládat datové bloky, zatímco NameNodes spravovat mnoho DataNodes, udržovat metadata bloků dat a řídit přístup klientů.
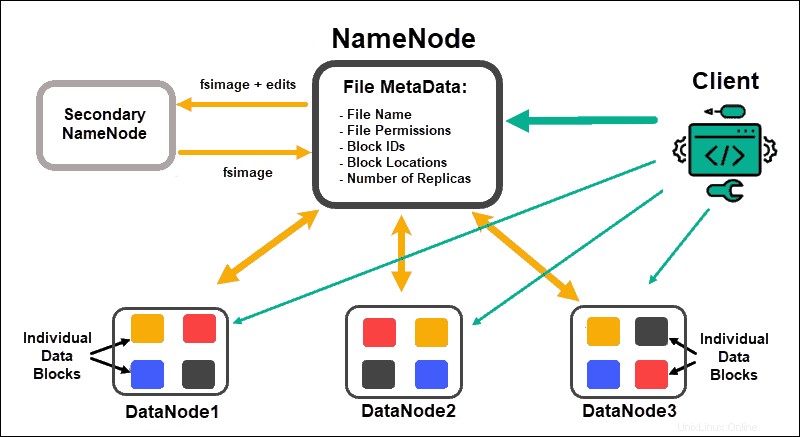
NameNode
Zpočátku jsou data rozdělena do abstraktních datových bloků. Metadata souboru pro tyto bloky, která zahrnují název souboru, oprávnění k souboru, ID, umístění a počet replik, jsou uložena v souboru fsimage v místní paměti NameNode.
Pokud by NameNode selhal, HDFS by nebyl schopen najít žádnou z datových sad distribuovaných v DataNode. Díky tomu je NameNode jediným bodem selhání celého clusteru. Tato chyba zabezpečení je vyřešena implementací sekundárního NameNode nebo Standby NameNode.
Uzel sekundárního názvu
Sekundární NameNode sloužil jako primární řešení zálohování v raných verzích Hadoop. Sekundární NameNode často stahuje aktuální instanci fsimage a upravuje protokoly z NameNode a spojuje je. Upravený fsimage lze poté načíst a obnovit v primárním NameNode.
Přepnutí při selhání není automatický proces, protože správce by musel data ze sekundárního NameNode obnovit ručně.
Pohotovostní NameNode
Vysoká dostupnost funkce byla představena v Hadoop 2.0 a následujících verzích, aby se zabránilo výpadkům v případě selhání NameNode. Tato funkce vám umožňuje udržovat dva NameNody spuštěné na samostatných vyhrazených hlavních uzlech.
Pohotovostní NameNode je automatické převzetí služeb při selhání v případě, že se aktivní NameNode stane nedostupným. Pohotovostní NameNode navíc provádí proces kontroly. Kvůli této vlastnosti nejsou sekundární a pohotovostní NameNode kompatibilní. Cluster Hadoop může udržovat jeden nebo druhý.
Správce zoo
Zookeeper je lehký nástroj, který podporuje vysokou dostupnost a redundanci. Standby NameNode udržuje aktivní relaci s démonem Zookeeper.
Pokud aktivní NameNode zakolísá, démon Zookeeper detekuje selhání a provede proces převzetí služeb při selhání na nový NameNode. Použijte Zookeeper k automatizaci převzetí služeb při selhání a minimalizaci dopadu, který může mít selhání NameNode na cluster.
Datový uzel
Každý DataNode v clusteru používá proces na pozadí k ukládání jednotlivých bloků dat na podřízených serverech.
Ve výchozím nastavení HDFS ukládá tři kopie každého datového bloku na samostatných DataNodes. NameNode používá zásadu umístění s ohledem na rack. To znamená, že DataNodes, které obsahují repliky datových bloků, nemohou být všechny umístěny na stejném serverovém racku.
DataNode komunikuje a přijímá pokyny od NameNode zhruba dvacetkrát za minutu. Jednou za hodinu také hlásí stav a stav datových bloků umístěných v tomto uzlu. Na základě poskytnutých informací může NameNode požádat DataNode o vytvoření dalších replik, jejich odstranění nebo snížení počtu datových bloků přítomných v uzlu.
Zásady pro umístění do stojanu
Jedním z hlavních cílů distribuovaného úložného systému, jako je HDFS, je udržovat vysokou dostupnost a replikaci. Datové bloky proto musí být distribuovány nejen na různých DataNode, ale na uzlech umístěných na různých serverových stojanech.
To zajišťuje, že selhání celého stojanu neukončí všechny repliky dat. HDFS NameNode udržuje výchozí zásadu umístění replik s podporou racku:
- První replika datového bloku je umístěna na stejném uzlu jako klient.
- Druhá replika je automaticky umístěna na náhodný DataNode v jiném stojanu.
- Třetí replika je umístěna v samostatném DataNode ve stejném stojanu jako druhá replika.
- Jakékoli další repliky jsou uloženy na náhodných DataNodes v celém clusteru.
Tato zásada umístění do racku zachovává pouze jednu repliku na uzel a nastavuje limit dvou replik na serverový rack.
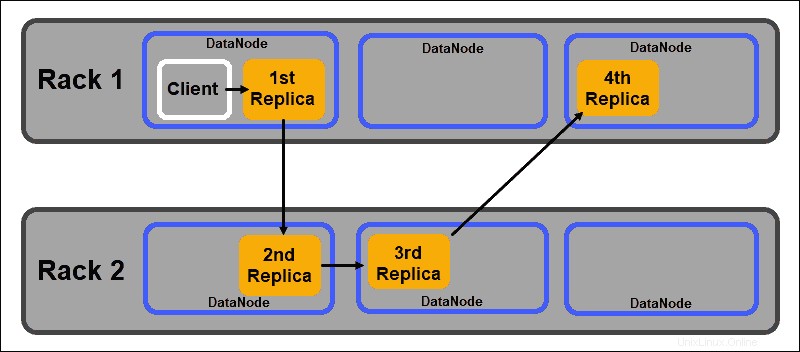
Selhání stojanu je mnohem méně časté než selhání uzlů. HDFS zajišťuje vysokou spolehlivost tím, že vždy ukládá alespoň jednu repliku datového bloku v DataNode v jiném racku.
Příze vysvětlena
YARN (Yet Another Resource Negotiator) je výchozím prostředkem správy clusteru pro Hadoop 2 a Hadoop 3. V předchozích verzích Hadoop se MapReduce používal ke zpracování dat i alokaci zdrojů. Postupem času nutnost rozdělit zpracování a správu zdrojů vedla k vývoji YARN.
Role přidělování zdrojů YARN ji umisťuje mezi vrstvu úložiště, kterou představuje HDFS, a procesor pro zpracování MapReduce. YARN také poskytuje obecné rozhraní, které vám umožňuje implementovat nové procesory pro různé typy dat.
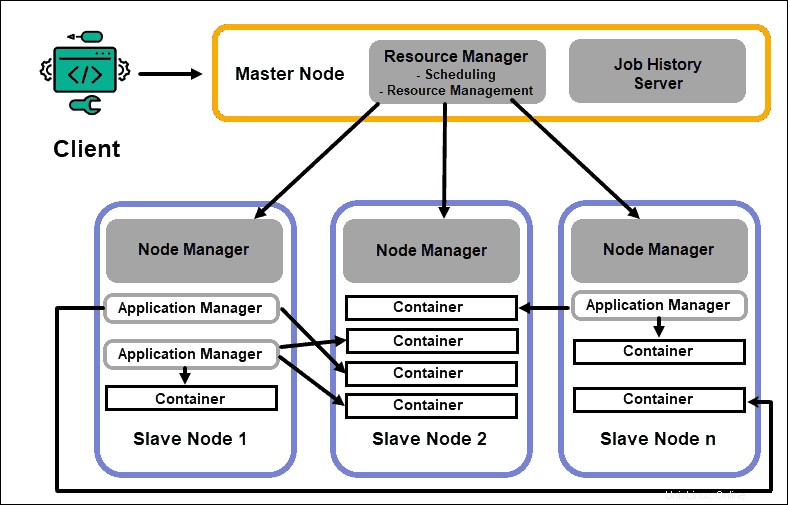
ResourceManager
Démon ResourceManager (RM) řídí všechny prostředky zpracování v clusteru Hadoop. Jeho primárním účelem je určit zdroje pro jednotlivé aplikace umístěné na podřízených uzlech. Udržuje globální přehled o probíhajících a plánovaných procesech, zpracovává požadavky na zdroje a podle toho plánuje a přiřazuje zdroje. ResourceManager je zásadní pro framework Hadoop a měl by běžet na vyhrazeném hlavním uzlu.
Jediným zaměřením RM je plánování úloh. Na rozdíl od MapReduce se nezajímá o výpadky nebo jednotlivé úlohy zpracování. Toto oddělení úkolů v YARN je to, co dělá Hadoop neodmyslitelně škálovatelným a přeměňuje jej v plně vyvinutou výpočetní platformu.
NodeManager
Každý podřízený uzel má službu zpracování NodeManager a službu úložiště DataNode. Společně tvoří páteř distribuovaného systému Hadoop.
DataNode, jak již bylo zmíněno dříve, je prvkem HDFS a je řízen NameNode. NodeManager podobným způsobem funguje jako slave správce ResourceManager. Primární funkcí démona NodeManager je sledovat data o zdrojích zpracování na svém podřízeném uzlu a odesílat pravidelné zprávy do ResourceManager.
Kontejnery
Prostředky zpracování v clusteru Hadoop jsou vždy nasazeny v kontejnerech. Kontejner má paměť, systémové soubory a prostor pro zpracování.
Nasazení kontejneru je obecné a může spouštět jakýkoli požadovaný vlastní prostředek na jakémkoli systému. Pokud je požadované množství klastrových prostředků v mezích toho, co je přijatelné, RM schválí a naplánuje nasazení tohoto kontejneru.
Procesy kontejneru na podřízeném uzlu jsou zpočátku zajišťovány, monitorovány a sledovány NodeManager na tomto konkrétním podřízeném uzlu.
Aplikační hlavní
Každý kontejner na podřízeném uzlu má svůj vyhrazený aplikační master. Aplikační mastery jsou také nasazeny v kontejneru. Dokonce i MapReduce má Application Master, který provádí mapování a redukování úkolů.
Dokud je aplikační master aktivní, posílá zprávy do Správce prostředků o svém aktuálním stavu a stavu aplikace, kterou monitoruje. Na základě poskytnutých informací naplánuje Správce zdrojů další zdroje nebo je přiřadí jinam v clusteru, pokud již nejsou potřeba.
Application Master dohlíží na celý životní cyklus aplikace, od vyžádání potřebných kontejnerů z RM až po odeslání požadavků na pronájem kontejneru NodeManager.
Server historie úloh
JobHistory Server umožňuje uživatelům získávat informace o aplikacích, které dokončily svou činnost. REST API poskytuje interoperabilitu a může dynamicky informovat uživatele o aktuálních a dokončených úlohách obsluhovaných daným serverem.
Jak PŘÍZE funguje?
Základní pracovní postup pro nasazení v YARN začíná, když klientská aplikace odešle požadavek do ResourceManager.
- ResourceManager dává pokyn pro NodeManager spustíte Aplikační hlavní pro tento požadavek, který se poté spustí v kontejneru.
- Nově vytvořený Hlavní soubor aplikací se zaregistruje u RM . Hlavní aplikační server kontaktuje HDFS NameNode a určí umístění potřebných datových bloků a vypočítá množství mapy a sníží počet úkolů potřebných ke zpracování dat.
- Hlavní stránka aplikace poté požádá o potřebné zdroje od RM a nadále sděluje požadavky na zdroje během životního cyklu kontejneru.
- RM naplánuje zdroje spolu s požadavky od všech ostatních Application Masters a řadí jejich požadavky do fronty. Jakmile budou zdroje dostupné, RM je zpřístupní aplikačnímu masteru na konkrétním podřízeném uzlu.
- Správce aplikací kontaktuje NodeManager pro tento podřízený uzel a požádá jej o vytvoření kontejneru poskytnutím proměnných, ověřovacích tokenů a příkazového řetězce pro proces. Na základě tohoto požadavku NodeManager vytvoří a spustí kontejner .
- Správce aplikací poté proces monitoruje a v případě selhání reaguje restartováním procesu na dalším dostupném slotu. Pokud selže po čtyřech různých pokusech, selže celá úloha. Během tohoto procesu Správce aplikací odpovídá na požadavky stavu klienta.
Jakmile jsou všechny úkoly dokončeny, Application Master odešle výsledek klientské aplikaci, informuje RM, že aplikace dokončila svůj úkol, odhlásí se ze Správce prostředků a vypne se.
RM může také nařídit NameNode, aby během procesu ukončil konkrétní kontejner v případě změny priority zpracování.
Vysvětlení MapReduce
MapReduce je programovací algoritmus, který zpracovává data rozptýlená v clusteru Hadoop. Stejně jako u jakéhokoli jiného procesu v Hadoopu, jakmile se úloha MapReduce spustí, ResourceManager si vyžádá hlavní aplikaci pro správu a monitorování životního cyklu úlohy MapReduce.
Application Master vyhledá požadované datové bloky na základě informací uložených v NameNode. AM také informuje ResourceManager, aby spustil úlohu MapReduce na stejném uzlu, na kterém jsou umístěny datové bloky. Kdykoli je to možné, data se zpracovávají lokálně na podřízených uzlech, aby se snížilo využití šířky pásma a zlepšila se účinnost clusteru.
Vstupní data jsou mapována, promíchána a poté redukována na agregovaný výsledek. Výstup úlohy MapReduce je uložen a replikován v HDFS.
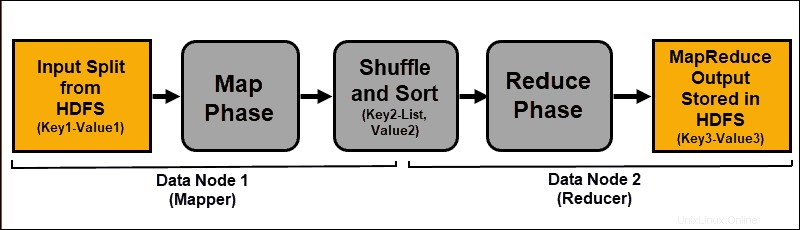
Servery Hadoop, které provádějí úlohy mapování a redukce, se často označují jako Mappery a Reduktory .
ResourceManager rozhodne, kolik mapovačů použít. Toto rozhodnutí závisí na velikosti zpracovávaných dat a paměťovém bloku dostupném na každém mapovacím serveru.
Fáze mapy
Proces mapování přijímá jednotlivé logické výrazy dat uložených v datových blocích HDFS. Tyto výrazy mohou zahrnovat několik datových bloků a nazývají se rozdělení vstupu . Vstupní rozdělení se zavádí do procesu mapování jako páry klíč–hodnota .
Úloha mapovače prochází každý pár klíč–hodnota a vytváří novou sadu párů klíč–hodnota, která se liší od původních vstupních dat. Kompletní sortiment všech párů klíč–hodnota představuje výstup úlohy mapovače.
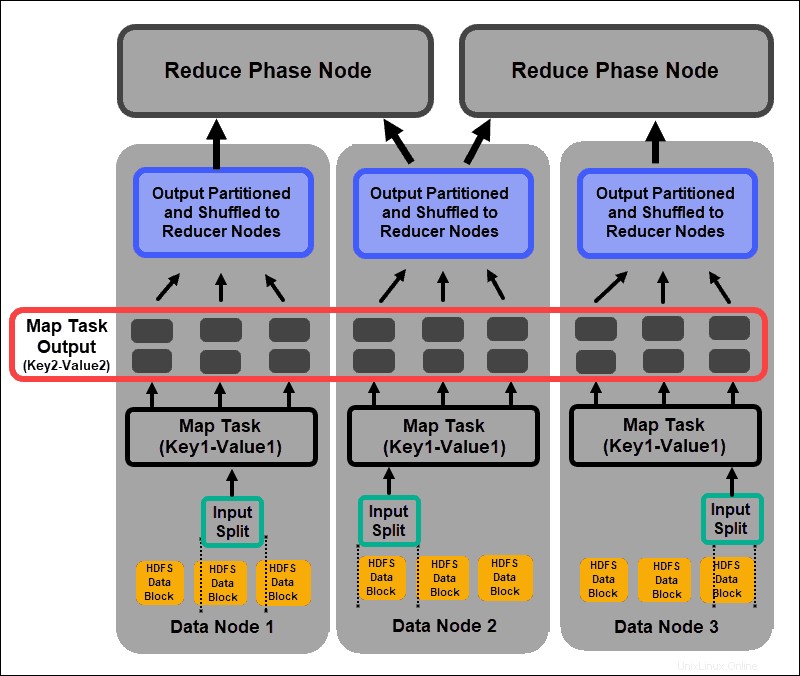
Na základě klíče z každého páru jsou data seskupena, rozdělena a zamíchána do uzlů redukce.
Fáze náhodného řazení a řazení
Náhodně je proces, ve kterém jsou výsledky ze všech mapových úloh zkopírovány do uzlů redukce. Kopírování výstupu mapové úlohy je jedinou výměnou dat mezi uzly během celé úlohy MapReduce.
Výstup mapové úlohy musí být uspořádán tak, aby se zlepšila účinnost fáze snižování. Mapované páry klíč–hodnota, které jsou zamíchány z uzlů mapovače, jsou uspořádány podle klíče s odpovídajícími hodnotami. Po roztřídění vstupu se spustí fáze snížení pomocí klíče v jediném vstupním souboru.
Fáze míchání a třídění probíhají paralelně. I když jsou mapové výstupy získávány z uzlů mapovače, jsou seskupeny a tříděny na redukčních uzlech.
Snížit fázi
Mapové výstupy jsou zamíchány a roztříděny do jediného vstupního souboru redukce umístěného v uzlu redukce. Funkce snížení používá vstupní soubor k agregaci hodnot na základě odpovídajících mapovaných klíčů. Výstupem z procesu snížení je nový pár klíč–hodnota. Tento výsledek představuje výstup celé úlohy MapReduce a je standardně uložen v HDFS.
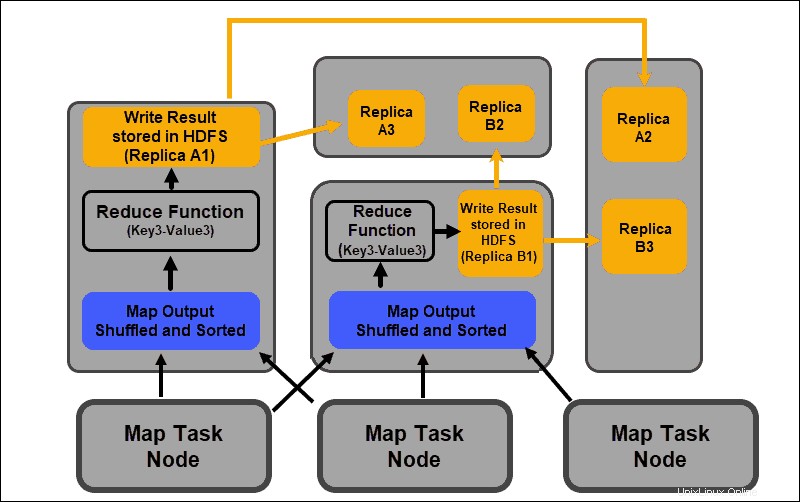
Všechny redukční úkoly probíhají současně a fungují nezávisle na sobě. Úloha snížení je také volitelná.
Mohou nastat případy, kdy je výsledkem mapové úlohy požadovaný výsledek a není potřeba vytvářet jedinou výstupní hodnotu.
Osvědčené postupy pro nasazení Hadoop
Následující část vysvětluje, jak vám základní hardware, uživatelská oprávnění a udržování vyváženého a spolehlivého clusteru mohou pomoci získat z vašeho ekosystému Hadoop více.
Upravte uživatelská oprávnění Hadoop
Síťový protokol Kerberos je hlavním autorizačním systémem v Hadoopu. Zajišťuje, že pouze ověřené uzly a uživatelé mají přístup a pracují v rámci clusteru.
Jakmile nainstalujete a nakonfigurujete centrum distribuce klíčů Kerberos, musíte provést několik změn v konfiguračních souborech Hadoop. Hadoop core-site.xml definuje parametry pro celý cluster Hadoop. Nastavte hadoop.security.authentication parametr v rámci core-site.xml na kerberos . Stejná vlastnost musí být nastavena na true pro povolení autorizace služby.
Seznamy řízení přístupu v hadoop-policy-xml soubor lze také upravit a udělit tak různé úrovně přístupu konkrétním uživatelům. Nalézt rovnováhu mezi nezbytnými uživatelskými právy a poskytnutím příliš mnoha oprávnění může být se základními nástroji příkazového řádku obtížné.
Je dobré použít další bezpečnostní rámce, jako je Apache Ranger nebo Apache Sentry . Tyto nástroje vám pomohou spravovat všechny úkoly související se zabezpečením z centrálního, uživatelsky přívětivého prostředí. Použijte je k poskytnutí specifické autorizace pro úkoly a uživatele při zachování úplné kontroly nad procesem.
Vyvážený hadoopový cluster
Distribuovaný systém jako Hadoop je dynamické prostředí. Přidání nových uzlů nebo odstranění starých může způsobit dočasnou nerovnováhu v rámci clusteru. Datové bloky mohou být nedostatečně replikovány.
Vaším cílem je šířit data co nejkonzistentněji napříč podřízenými uzly v clusteru. Ke změně předdefinovaných nastavení použijte nástroj pro vyvažování clusterů Hadoop. Definujte své zásady vyvažování pomocí hdfs balancer příkaz. Tento příkaz a jeho možnosti vám umožňují upravit prahové hodnoty kapacity disku uzlu.
Výchozí velikost bloku počínaje Hadoopem 2.x je 128 MB. Hadoop umožňuje uživateli toto nastavení změnit. Zvažte změnu výchozí velikosti bloku dat, pokud zpracováváte značné množství dat; jinak by počet spuštěných úloh mohl zahltit váš cluster.
Pokud zvětšíte velikost datového bloku, vstup do mapové úlohy bude větší a bude spuštěno méně mapových úloh. To zase znamená, že fáze shuffle má mnohem lepší propustnost při přenosu dat do redukčního uzlu. Tato jednoduchá úprava může zkrátit dobu potřebnou k dokončení úlohy MapReduce.
Škálování Hadoop (hardware)
NameNode je zásadním prvkem vašeho clusteru Hadoop. Zapojte pro tento uzel co nejvíce procesorových jader. Velikost RAM definuje, kolik dat se načte z paměti uzlu. Pokud přetížíte zdroje dostupné pro váš hlavní uzel, omezíte schopnost vašeho clusteru růst.
Redundantní napájecí zdroje by měly být vždy rezervovány pro hlavní uzel. Snažte se nepoužívat redundantní napájecí zdroje a cenné hardwarové zdroje pro datové uzly. Jsou důležitou součástí ekosystému Hadoop, jsou však postradatelné. Cenově dostupné dedikované servery se středními možnostmi zpracování jsou ideální pro datové uzly, protože spotřebovávají méně energie a produkují méně tepla.
Škálovací schopnosti Hadoopu jsou hlavní hnací silou jeho široké implementace. Vždy je nutné mít dostatek místa, aby se váš cluster mohl rozšířit. Rychlé přidávání nových uzlů nebo místa na disku vyžaduje další napájení, síť a chlazení. To vše se může ukázat jako velmi obtížné bez pečlivého plánování pravděpodobného budoucího růstu.
Škálování Hadoop (software)
Nové projekty Hadoop jsou pravidelně vyvíjeny a stávající jsou vylepšovány pomocí pokročilejších funkcí.
Dokonce i starší nástroje jsou upgradovány, aby jim umožnily těžit z ekosystému Hadoop. Vždy sledujte nový vývoj v této oblasti. Rozmanitost a objem příchozích datových souborů vyžadují zavedení dalších rámců.
Implementace nového uživatelsky přívětivého nástroje může vyřešit technické dilema rychleji než pokus o vytvoření vlastního řešení. Nevyhýbejte se již vyvinutým komerčním rychlým opravám. Trh je přesycený prodejci nabízejícími Hadoop-as-a-service nebo přizpůsobenými samostatnými nástroji.
Spolehlivost dat a odolnost proti chybám
Htlukot srdce je opakující se signál TCP handshake. DataNodes, umístěné na každém podřízeném serveru, nepřetržitě odesílají prezenční signál do NameNode umístěného na hlavním serveru. Výchozí časový rámec srdečního tepu jsou tři sekundy. Pokud NameNode neobdrží signál déle než deset minut, zapíše DataNode a jeho datové bloky se automaticky naplánují na různé uzly.
Nesnižujte srdeční frekvenci, abyste se pokusili snížit zátěž NameNode. Udržování „informací“ NameNodes je klíčové, a to i v extrémně velkých clusterech. Bez pravidelného a častého přílivu srdečních tepů je NameNode vážně omezován a nemůže ovládat cluster tak efektivně.
Abyste se vyhnuli vážným následkům chyb, ponechte výchozí nastavení povědomí o stojanech a ukládejte repliky datových bloků napříč serverovými stojany. Pokud ztratíte serverový stojan, ostatní repliky přežijí a dopad na zpracování dat je minimální.