Úvod
PhoenixNAP Bare Metal Cloud odhaluje rozhraní RESTful API, které umožňuje vývojářům automatizovat vytváření serverů holých kovů.
Abychom demonstrovali schopnosti systému, tento článek vysvětluje a poskytuje příklady kódu Python, jak využít BMC API k automatizaci zřizování clusteru Spark na Bare Metal Cloud .

Předpoklady
- účet fénixNAP Bare Metal Cloud
- Přístupový token OAuth
Jak automatizovat nasazení Spark Clusters
Níže uvedené pokyny platí pro prostředí Bare Metal Cloud společnosti fénixNAP. Příklady kódu Python uvedené v tomto článku nemusí fungovat v jiných prostředích.
Kroky potřebné k nasazení a přístupu ke clusteru Apache Spark:
1. Vygenerujte přístupový token.
2. Vytvořte servery Bare Metal Cloud se systémem Ubuntu OS.
3. Nasaďte cluster Apache Spark na vytvořené instance serveru.
4. Otevřete řídicí panel Apache Spark pomocí vygenerovaného odkazu.
Článek zdůrazňuje podmnožinu segmentů kódu Python, které využívají Bare Metal Cloud API a příkazy shellu k dokončení výše uvedených kroků.
Krok 1:Získejte přístupový token
Před odesláním požadavků do BMC API musíte získat přístupový token OAuth pomocí client_id a client_secret registrované na portálu BMC.
Chcete-li se dozvědět více o tom, jak se zaregistrovat pro client_id a client_secret, nahlédněte do průvodce Bare Metal Cloud API Quick Start.
Níže je funkce Pythonu, která generuje přístupový token pro API:
def get_access_token(client_id: str, client_secret: str) -> str:
"""Retrieves an access token from BMC auth by using the client ID and the
client Secret."""
credentials = "%s:%s" % (client_id, client_secret)
basic_auth = standard_b64encode(credentials.encode("utf-8"))
response = requests.post(' https://api.phoenixnap.com/bmc/v0/servers',
headers={
'Content-Type': 'application/x-www-form-urlencoded',
'Authorization': 'Basic %s' % basic_auth.decode("utf-8")},
data={'grant_type': 'client_credentials'})
if response.status_code != 200:
raise Exception('Error: {}. {}'.format(response.status_code, response.json()))
return response.json()['access_token']
Krok 2:Vytvořte instance serveru Bare Metal
Použijte volání REST API POST/servers k vytvoření instancí holých kovových serverů. Pro každý požadavek POST/serverů zadejte požadované parametry, jako je umístění datového centra, typ serveru, OS atd.
Níže je uvedena funkce Pythonu, která zavolá BMC API za účelem vytvoření holého kovového serveru.
def __do_create_server(session, server):
response = session.post('https://api.phoenixnap.com/bmc/v0/servers'),
data=json.dumps(server))
if response.status_code != 200:
print("Error creating server: {}".format(json.dumps(response.json())))
else:
print("{}".format(json.dumps(response.json())))
return response.json()
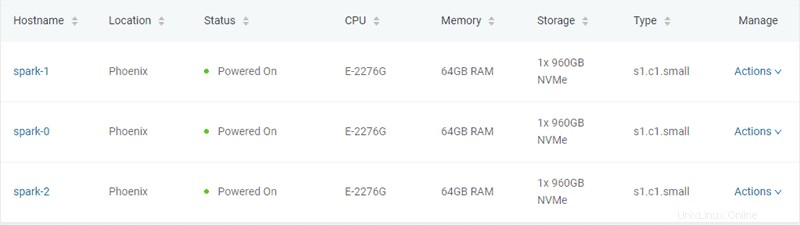
V tomto příkladu jsou vytvořeny tři kovové servery typu „s1.c1.small“, jak je uvedeno v souboru server-settings.conf.
{
"ssh-key" : "ssh-rsa xxxxxx== username",
"servers_quantity" : 3,
"type" : "s1.c1.small",
"hostname" : "spark",
"description" : "spark",
"public" : True,
"location" : "PHX",
"os" : "ubuntu/bionic"
}
Očekávaný výstup ze skriptu Python, který generuje token a zajišťuje servery, je následující:
Retrieving token
Successfully retrieved API token
Creating servers...
{
"id": "5ee9c1b84a9ca71ea6b9b766",
"status": "creating",
"hostname": "spark-1",
"description": "spark-1",
"os": "ubuntu/bionic",
"type": "s1.c1. small ",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.11"
],
"publicIpAddresses": [
"131.153.143.250",
"131.153.143.251",
"131.153.143.252",
"131.153.143.253",
"131.153.143.254"
]
}
Server created, provisioning spark-1...
{
"id": "5ee9c1b84a9ca71ea6b9b767",
"status": "creating",
"hostname": "spark-0",
"description": "spark-0",
"os": "ubuntu/bionic",
"type": "s1.c1.small",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.12"
],
"publicIpAddresses": [
"131.153.143.50",
"131.153.143.51",
"131.153.143.52",
"131.153.143.53",
"131.153.143.54"
]
}
Server created, provisioning spark-0...
{
"id": "5ee9c1b84a9ca71ea6b9b768",
"status": "creating",
"hostname": "spark-2",
"description": "spark-2",
"os": "ubuntu/bionic",
"type": "s1.c1. small ",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.13"
],
"publicIpAddresses": [
"131.153.142.234",
"131.153.142.235",
"131.153.142.236",
"131.153.142.237",
"131.153.142.238"
]
}
Server created, provisioning spark-2...
Waiting for servers to be provisioned... Jakmile skript vytvoří tři holé kovové servery, komunikuje s BMC API, aby zkontroloval stav serveru, dokud není zřízení dokončeno a servery nejsou zapnuty.
Krok 3:Poskytnutí clusteru Apache Spark
Jakmile jsou servery zřízeny, skript Python naváže připojení SSH pomocí veřejné IP adresy serverů. Dále skript nainstaluje Spark na servery Ubuntu. To zahrnuje instalaci JDK , Scala , Git a Spark na všech serverech.
Chcete-li zahájit proces, spusťte soubor all_hosts.sh soubor na všech serverech. Skript poskytuje pokyny ke stažení a instalaci a také konfiguraci prostředí potřebnou k přípravě clusteru k použití.
Apache Spark obsahuje skripty, které konfigurují servery jako hlavní a pracovní uzly. Jediným omezením při konfiguraci pracovního uzlu je již nakonfigurovaný hlavní uzel. První server, který má být zřízen, je přiřazen jako uzel Spark Master.
Tuto úlohu provádí následující funkce Pythonu:
def wait_server_ready(function_scheduler, server_data):
json_server = bmc_api.get_server(REQUEST, server_data['id'])
if json_server['status'] == "creating":
main_scheduler.enter(2, 1, wait_server_ready, (function_scheduler, server_data))
elif json_server['status'] == "powered-on" and not data['has_a_master_server']:
server_data['status'] = json_server['status']
server_data['master'] = True
server_data['joined'] = True
data['has_a_master_server'] = True
data['master_ip'] = json_server['publicIpAddresses'][0]
data['master_hostname'] = json_server['hostname']
print("ASSIGNED MASTER SERVER: {}".format(data['master_hostname']))Spusťte soubor master_host.sh pro konfiguraci prvního serveru jako hlavního uzlu. Níže naleznete obsah master_host.sh soubor:
#!/bin/bash
echo "Setting up master node"
/opt/spark/sbin/start-master.shJakmile je hlavní uzel přiřazen a nakonfigurován, další dva uzly jsou přidány do clusteru Spark.
Níže naleznete obsah worker_host.sh soubor:
#!/bin/bash
echo "Setting up master node on /etc/hosts"
echo "$1 $2 $2" | sudo tee -a /etc/hosts
echo "Starting worker node"
echo "Joining worker node to the cluster"
/opt/spark/sbin/start-slave.sh spark://$2:7077
Zřizování clusteru Apache Spark je dokončeno. Níže je očekávaný výstup skriptu Python:
ASSIGNED MASTER SERVER: spark-2
Running all_host.sh script on spark-2 (Public IP: 131.153.142.234)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running master_host.sh script on spark-2 (Public IP: 131.153.142.234)
Setting up master node
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.master.Master-1-spark-2.out
Master host installed
Running all_host.sh script on spark-0 (Public IP: 131.153.143.170)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running all_host.sh script on spark-1 (Public IP: 131.153.143.50)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running slave_host.sh script on spark-0 (Public IP: 131.153.143.170)
Setting up master node on /etc/hosts
10.0.0.12 spark-2 spark-2
Starting worker node
Joining worker node to the cluster
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.worker.Worker-1-spark-0.out
Running slave_host.sh script on spark-1 (Public IP: 131.153.143.50)
Setting up master node on /etc/hosts
10.0.0.12 spark-2 spark-2
Starting worker node
Joining worker node to the cluster
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.worker.Worker-1-spark-1.out
Setup servers done
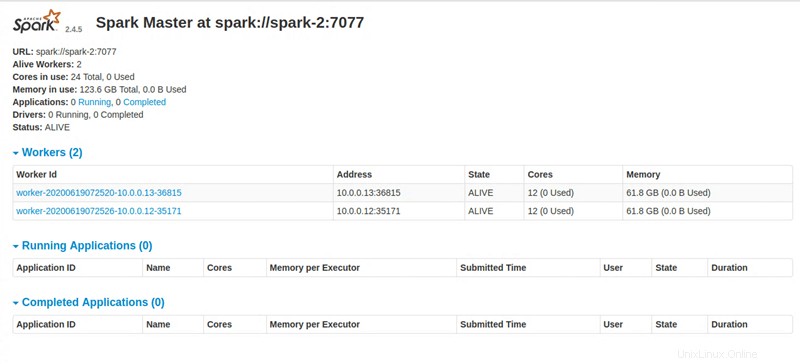
Master node UI: http://131.153.142.234:8080
Krok 4:Přístup k Apache Spark Dashboard
Po provedení všech instrukcí poskytuje skript Python odkaz pro přístup k řídicímu panelu Apache Spark.