Úvod
Spark DataFrame je integrovaná datová struktura se snadno použitelným API pro zjednodušení distribuovaného zpracování velkých dat. DataFrame je k dispozici pro univerzální programovací jazyky, jako je Java, Python a Scala.
Jedná se o rozšíření rozhraní Spark RDD API optimalizované pro efektivnější psaní kódu při zachování výkonu.
Tento článek vysvětluje, co je Spark DataFrame, funkce a jak používat Spark DataFrame při shromažďování dat.

Předpoklady
- Spark nainstalován a nakonfigurován (postupujte podle našeho průvodce:Jak nainstalovat Spark na Ubuntu, Jak nainstalovat Spark na Windows 10).
- Prostředí nakonfigurované pro použití Spark v Javě, Pythonu nebo Scale (tato příručka používá Python).
Co je to DataFrame?
DataFrame je programová abstrakce v modulu Spark SQL. DataFrames se podobají relačním databázovým tabulkám nebo excelovým tabulkám se záhlavími:data jsou umístěna v řádcích a sloupcích různých datových typů.
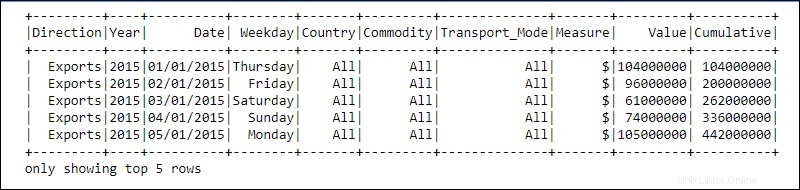
Zpracování je dosaženo pomocí složitých uživatelsky definovaných funkcí a známých funkcí pro manipulaci s daty, jako je řazení, spojení, seskupení atd.
Informace pro distribuovaná data jsou strukturována do schémat . Každý sloupec v DataFrame obsahuje sloupec name , datový typ, a možnost null vlastnosti. Když možnost hodnoty null je nastaveno na pravda , sloupec přijímá null vlastnosti také.

Jak funguje datový rámec?
DataFrame API je součástí modulu Spark SQL. Rozhraní API poskytuje snadný způsob práce s daty v rámci Spark SQL při integraci s univerzálními jazyky jako Java, Python a Scala.
I když existují podobnosti s Python Pandas a datovými rámci R, Spark dělá něco jiného. Toto API je šité na míru pro integraci s rozsáhlými daty pro datovou vědu a strojové učení a přináší četné optimalizace.
Spark DataFrames jsou distribuovatelné napříč několika clustery a optimalizovány pomocí Catalyst. Optimalizátor Catalyst přijímá dotazy (včetně příkazů SQL aplikovaných na DataFrames) a vytváří optimální plán paralelních výpočtů.
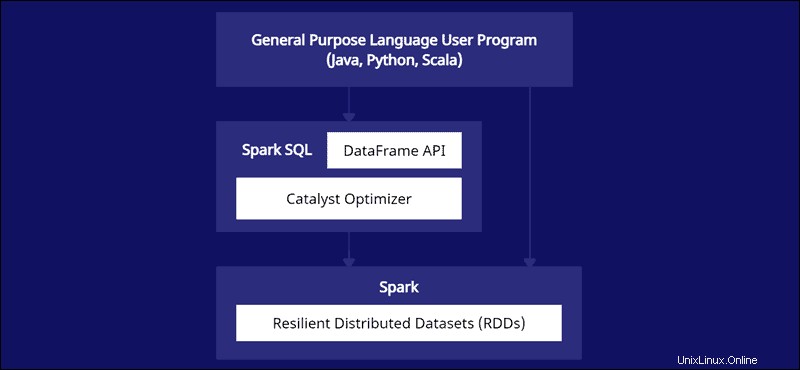
Pokud máte zkušenosti s datovým rámcem Python a R, kód Spark DataFrame vypadá povědomě. Na druhou stranu, pokud používáte Spark RDD (Resilient Distributed Dataset), informace o struktuře dat poskytuje příležitosti k optimalizaci.
Tvůrci Sparku navrhli DataFrames tak, aby se co nejúčinněji vypořádaly s velkými datovými výzvami. Vývojáři mohou využít sílu distribuovaného počítání se známými, ale více optimalizovanými API.
Funkce datových rámců Spark
Spark DataFrame přichází s mnoha cennými funkcemi:
- Podpora různých datových formátů, jako je Hive, CSV, XML, JSON, RDD, Cassandra, Parquet atd.
- Podpora integrace s různými nástroji Big Data.
- Schopnost zpracovávat kilobajty dat na menších počítačích a petabajty na clusterech.
- Optimalizátor katalyzátorů pro efektivní zpracování dat ve více jazycích.
- Zpracování strukturovaných dat prostřednictvím schematického zobrazení dat.
- Vlastní správa paměti pro snížení přetížení a zlepšení výkonu ve srovnání s RDD.
- Rozhraní API pro Java, R, Python a Spark.
Jak vytvořit Spark DataFrame?
Existuje několik metod, jak vytvořit Spark DataFrame. Zde je příklad, jak jej vytvořit v Pythonu pomocí prostředí notebooku Jupyter:
1. Inicializujte a vytvořte relaci API:
#Add pyspark to sys.path and initialize
import findspark
findspark.init()
#Load the DataFrame API session into Spark and create a session
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()2. Vytvořte data o hračkách jako seznam slovníků:
#Generate toy data using a dictionary list
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
3. Vytvořte DataFrame pomocí createDataFrame a předat data seznam:
#Create a DataFrame from the data list
df = spark.createDataFrame(data)4. Vytiskněte schéma a tabulku pro zobrazení vytvořeného DataFrame:
#Print the schema and view the DataFrame in table format
df.printSchema()
df.show()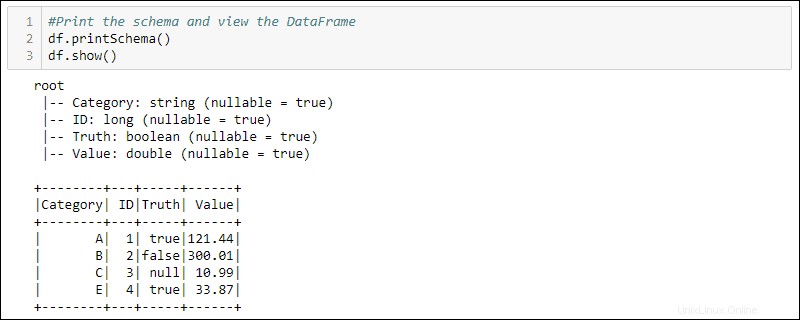
Jak používat DataFrames
Strukturovaná data uložená v DataFrame poskytují dvě manipulační metody
- Použití jazyka specifického pro doménu
- Použití SQL dotazů.
Následující dvě metody používají DataFrame z předchozího příkladu k výběru všech řádků, kde je sloupec Pravda nastaven na hodnotu true, a seřadí data podle sloupce Hodnota.
Metoda 1:Použití dotazů specifických pro doménu
Python poskytuje vestavěné metody pro filtrování a třídění dat. Vyberte konkrétní sloupec pomocí df.<column name> :
df.filter(df.Truth == True).sort(df.Value).show()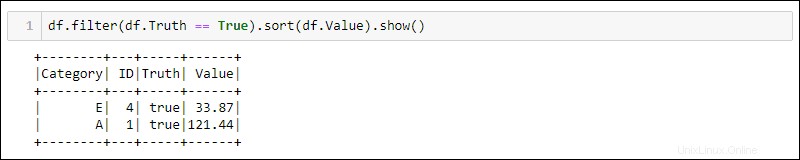
Metoda 2:Použití SQL dotazů
Chcete-li používat dotazy SQL s DataFrame, vytvořte zobrazení pomocí createOrReplaceTempView vestavěnou metodu a spusťte dotaz SQL pomocí spark.sql metoda:
df.createOrReplaceTempView('table')
spark.sql('''SELECT * FROM table WHERE Truth=true ORDER BY Value ASC''')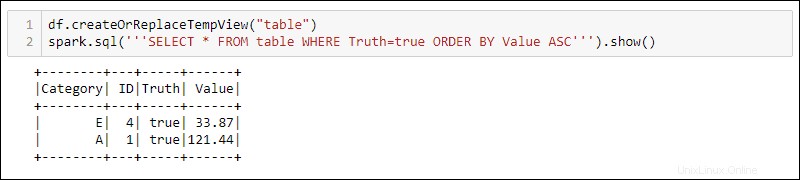
Výstup zobrazuje výsledky dotazu SQL aplikované na dočasné zobrazení DataFrame. To umožňuje vytvářet více pohledů a dotazů na stejná data pro komplexní zpracování dat.