Úvod
V terminologii Hive jsou externí tabulky tabulky, které nejsou spravovány pomocí Hive. Jejich účelem je usnadnit import dat z externího souboru do metastore.
Data externí tabulky jsou uložena externě, zatímco metaúložiště Hive obsahuje pouze schéma metadat. V důsledku toho zrušení externí tabulky neovlivní data.
V tomto kurzu se naučíte, jak vytvořit, dotazovat a zrušit externí tabulku v Hive.

Předpoklady
- Ubuntu 18.04 LTS nebo novější
- Přístup k příkazovému řádku s právy sudo
- Apache Hadoop nainstalován a spuštěn
- Apache Hive nainstalován a spuštěn
Poznámka: Tento tutoriál používá Ubuntu 20.04. Hive však funguje na všech operačních systémech stejně. To znamená, že proces vytváření, dotazování a rušení externích tabulek lze aplikovat na Hive ve Windows, Mac OS, dalších distribucích Linuxu atd.
Vytvoření externí tabulky v Hive – vysvětlení syntaxe
Při vytváření externí tabulky v Hive musíte zadat následující informace:
- Název tabulky –
create external tablepříkaz vytvoří tabulku. Pokud již v systému existuje tabulka se stejným názvem, dojde k chybě. Chcete-li tomu předejít, přidejteif not existsk prohlášení. V názvech tabulek se nerozlišují malá a velká písmena. - Názvy a typy sloupců – Stejně jako názvy tabulek, názvy sloupců nerozlišují malá a velká písmena. Typy sloupců jsou hodnoty jako
int,char,stringatd. - Formát řádku – Řádky používají nativní nebo vlastní formáty SerDe (Serializer/Deserializer). Nativní SerDe se použije, pokud není definován formát řádku nebo pokud je zadán jako oddělovač.
- Znak ukončení pole – Toto je
charzadejte znak, který odděluje hodnoty tabulky v řádku. - Formát úložiště – Můžete určit formáty úložiště, jako je textový soubor, sekvenční soubor, jsonfile atd.
- Umístění – Toto je umístění adresáře HDFS souboru obsahujícího data tabulky.
Správná syntaxe pro poskytování těchto informací Hive je:
create external table if not exists [external-table-name] (
[column1-name] [column1-type], [column2-name] [column2-type], …)
comment '[comment]'
row format [format-type]
fields terminated by '[termination-character]'
stored as [storage-type]
location '[location]';Vytvoření externí tabulky podregistru – příklad
Pro účely praktického příkladu vám tento tutoriál ukáže, jak importovat data ze souboru CSV do externí tabulky.
Krok 1:Připravte datový soubor
1. Vytvořte soubor CSV s názvem ‘country.csv’:
sudo nano countries.csv2. Pro každou zemi v seznamu napište číslo řádku, název země, její hlavní město a počet obyvatel v milionech:
1,USA,Washington,328
2,France,Paris,67
3,Spain,Madrid,47
4,Russia,Moscow,145
5,Indonesia,Jakarta,267
6,Nigeria,Abuja,196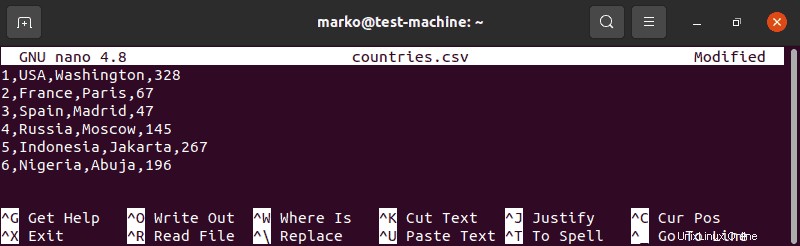
3. Uložte soubor a poznamenejte si jeho umístění.
Krok 2:Importujte soubor do HDFS
1. Vytvořte adresář HDFS. Tento adresář použijete jako umístění HDFS souboru, který jste vytvořili.
hdfs dfs -mkdir [hdfs-directory-name]2. Importujte soubor CSV do HDFS:
hdfs dfs -put [original-file-location] [hdfs-directory-name]
3. Použijte -ls příkaz k ověření, že je soubor ve složce HDFS:
hdfs dfs -ls [hdfs-directory-name]
Výstup zobrazí všechny soubory aktuálně v adresáři.
Poznámka: Další informace o HDFS naleznete v části Co je HDFS? Hadoop Distributed File System Guide.
Krok 3:Vytvořte externí tabulku
1. Po importu datového souboru do HDFS spusťte Hive a pomocí syntaxe vysvětlené výše vytvořte externí tabulku.
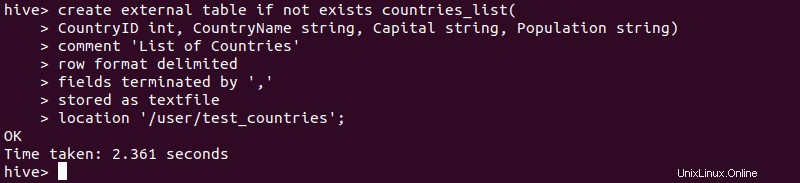
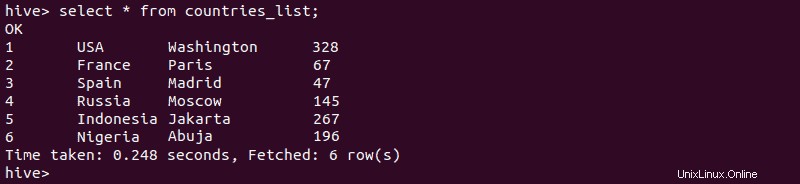
2. Chcete-li ověřit, že vytvoření externí tabulky bylo úspěšné, zadejte:
select * from [external-table-name];Výstup by měl obsahovat data ze souboru CSV, který jste importovali do tabulky:
3. Chcete-li vytvořit spravovanou tabulku pomocí dat z externí tabulky, zadejte:
create table if not exists [managed-table-name](
[column1-name] [column1-type], [column2-name] [var2-name], …)
comment '[comment]';
4. Dále importujte data z externí tabulky:
insert overwrite table [managed-table-name] select * from [external-table-name];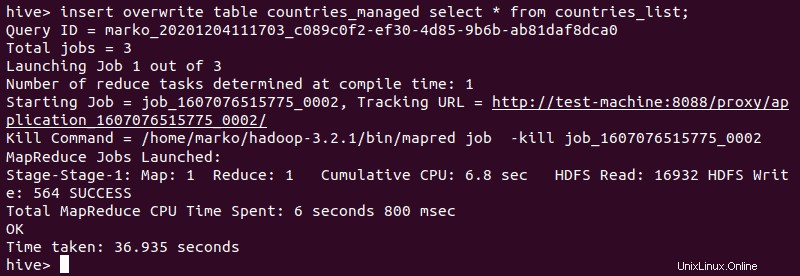
5. Ověřte, že data byla úspěšně vložena do spravované tabulky.
select * from [managed-table-name];
Jak dotazovat externí tabulku podregistru
Chcete-li zobrazit všechna data uložená v tabulce, použijete select * from příkaz následovaný názvem tabulky. Hive nabízí rozsáhlý seznam dotazovacích příkazů, které vám umožní zúžit vyhledávání a seřadit data podle vašich preferencí.
Můžete například použít where příkaz po select * from pro zadání podmínky:
select * from [table_name] where [condition];Hive vypíše pouze řádky, které splňují podmínku uvedenou v dotazu:

Místo hvězdičky znak, který znamená „všechna data“, můžete použít specifičtější determinanty. Nahrazení hvězdičky názvem sloupce (například Název země , z příkladu výše) vám zobrazí pouze data ze zvoleného sloupce.
Zde jsou některé další užitečné funkce dotazů a jejich syntaxe:
| Funkce | Syntaxe |
|---|---|
| Dotaz na tabulku podle více podmínek | select * from [table_name] where [condition1] and [condition2]; |
| Data tabulky objednávek | select [column1_name], [column2_name] from [table_name] order by [column_name]; |
| Seřaďte data tabulky v sestupném pořadí | select [column1_name], [column2_name] from [table_name] order by [column_name] desc; |
| Zobrazit počet řádků | select count(*) from [table_name]; |
Jak zrušit externí tabulku úlu
1. Zrušení externí tabulky v Hive se provádí pomocí stejného příkazu drop, který se používá pro spravované tabulky:
drop table [table_name];Výstup potvrdí úspěšnost operace:

2. Dotaz na zrušenou tabulku vrátí chybu:

Data z externí tabulky však zůstávají v systému a lze je získat vytvořením jiné externí tabulky ve stejném umístění.