Úvod
Naučit se vytvořit Spark DataFrame je jedním z prvních praktických kroků v prostředí Spark. Spark DataFrames pomáhají poskytovat pohled do datové struktury a dalších funkcí pro manipulaci s daty. Existují různé metody v závislosti na zdroji dat a formátu ukládání dat v souborech.
Tento článek vysvětluje, jak vytvořit Spark DataFrame ručně v Pythonu pomocí PySpark.

Předpoklady
- Python 3 nainstalován a nakonfigurován.
- PySpark nainstalován a nakonfigurován.
- Vývojové prostředí Python připravené pro testování příkladů kódu (používáme Jupyter Notebook).
Metody pro vytváření Spark DataFrame
Existují tři způsoby, jak vytvořit DataFrame ve Sparku ručně:
1. Vytvořte seznam a analyzujte jej jako DataFrame pomocí toDataFrame() metoda z SparkSession .
2. Převeďte RDD na DataFrame pomocí toDF() metoda.
3. Importujte soubor do SparkSession přímo jako DataFrame.
Příklady používají ukázková data a RDD pro demonstraci, ačkoli obecné principy platí pro podobné datové struktury.
Vytvořte DataFrame ze seznamu dat
Chcete-li vytvořit Spark DataFrame ze seznamu dat:
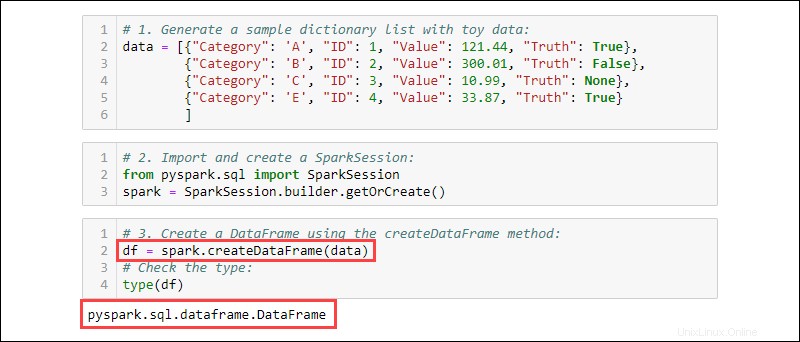
1. Vygenerujte vzorový seznam slovníku s údaji o hračkách:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
2. Importujte a vytvořte SparkSession :
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
3. Vytvořte DataFrame pomocí createDataFrame metoda. Zkontrolujte typ dat, abyste se ujistili, že proměnná je DataFrame:
df = spark.createDataFrame(data)
type(df)
Vytvořit DataFrame z RDD
Typickou událostí při práci ve Sparku je vytvoření DataFrame z existujícího RDD. Vytvořte ukázkový RDD a poté jej převeďte na DataFrame.
1. Vytvořte seznam slovníku obsahující data o hračkách:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
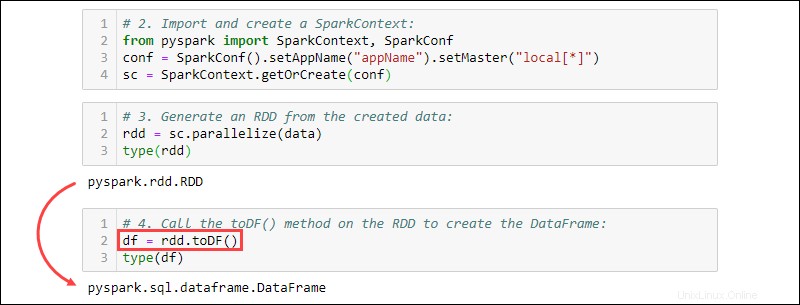
2. Importujte a vytvořte SparkContext :
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("projectName").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
3. Vygenerujte RDD z vytvořených dat. Zkontrolujte typ, abyste se ujistili, že objekt je RDD:
rdd = sc.parallelize(data)
type(rdd)
4. Zavolejte toDF() metoda na RDD k vytvoření DataFrame. Otestujte typ objektu a potvrďte:
df = rdd.toDF()
type(df)
Vytvořit DataFrame ze zdrojů dat
Spark dokáže zpracovat širokou škálu externích datových zdrojů pro konstrukci DataFrames. Obecná syntaxe pro čtení ze souboru je:
spark.read.format('<data source>').load('<file path/file name>')Název zdroje dat a cesta jsou oba typy String. Specifické zdroje dat mají také alternativní syntaxi pro import souborů jako DataFrames.
Vytváření ze souboru CSV
Vytvořte Spark DataFrame přímým čtením ze souboru CSV:
df = spark.read.csv('<file name>.csv')Načtěte více souborů CSV do jednoho DataFrame poskytnutím seznamu cest:
df = spark.read.csv(['<file name 1>.csv', '<file name 2>.csv', '<file name 3>.csv'])
Ve výchozím nastavení Spark přidává záhlaví pro každý sloupec. Pokud má soubor CSV záhlaví, které chcete zahrnout, přidejte option metoda při importu:
df = spark.read.csv('<file name>.csv').option('header', 'true')
Jednotlivé možnosti se hromadí tak, že je voláte jednu po druhé. Případně použijte options metoda, když je během importu potřeba více možností:
df = spark.read.csv('<file name>.csv').options(header = True)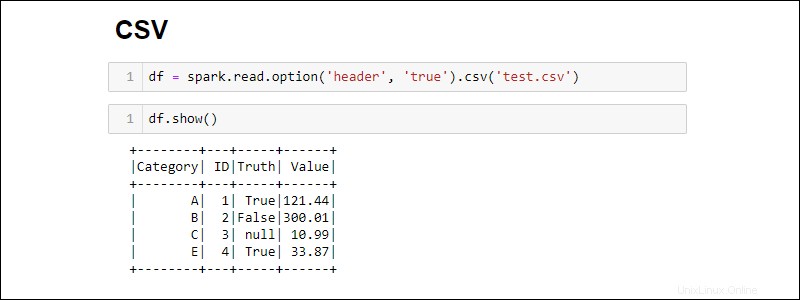
Všimněte si, že syntaxe se při použití liší option vs. options .
Vytváření ze souboru TXT
Vytvořte DataFrame z textového souboru pomocí:
df = spark.read.text('<file name>.txt')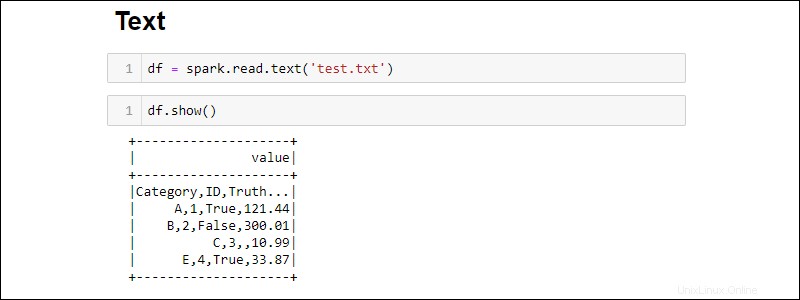
Soubor csv metoda je další způsob, jak číst z txt typ souboru do DataFrame. Například:
df = spark.read.option('header', 'true').csv('<file name>.txt')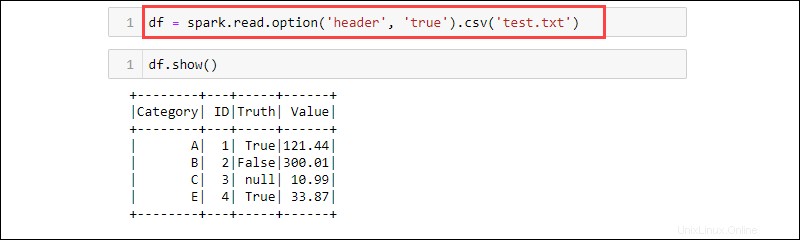
CSV je textový formát, kde oddělovačem je čárka (,) a funkce je tedy schopna číst data z textového souboru.
Vytváření ze souboru JSON
Vytvořte Spark DataFrame ze souboru JSON spuštěním:
df = spark.read.json('<file name>.json')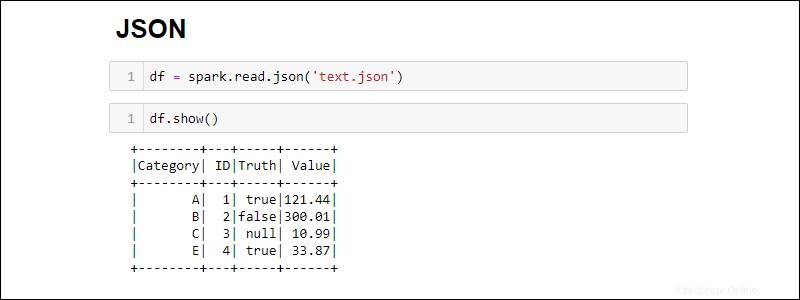
Vytváření ze souboru XML
Kompatibilita souborů XML není ve výchozím nastavení k dispozici. Nainstalujte závislosti a vytvořte DataFrame ze zdroje XML.
1. Stáhněte si závislost Spark XML. Uložte soubor .jar soubor ve složce Spark jar.
2. Načtěte soubor XML do DataFrame spuštěním:
df = spark.read\
.format('com.databricks.spark.xml')\
.option('rowTag', 'row')\
.load('test.xml')
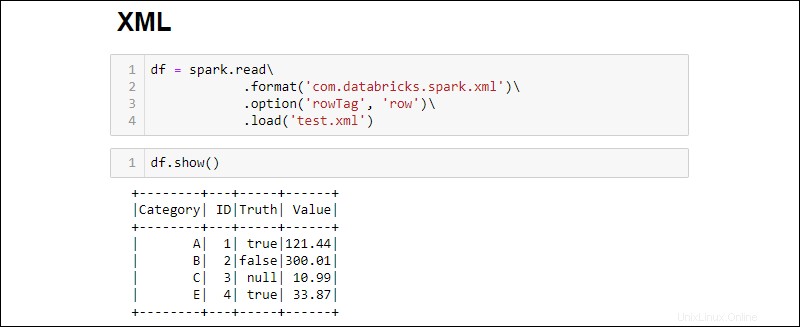
Změňte rowTag možnost, pokud každý řádek ve vašem XML soubor je označen jinak.
Vytvořit DataFrame z databáze RDBMS
Čtení z RDBMS vyžaduje konektor ovladače. Příklad ukazuje, jak se připojit a stáhnout data z databáze MySQL. Podobné kroky fungují pro jiné typy databází.
1. Stáhněte si konektor ovladače MySQL Java Driver. Uložte soubor .jar soubor ve složce Spark jar.
2. Spusťte SQL server a navažte spojení.
3. Navažte spojení a načtěte celou databázovou tabulku MySQL do DataFrame:
df = spark.read\
.format('jdbc')\
.option('url', 'jdbc:mysql://localhost:3306/db')\
.option('driver', 'com.mysql.jdbc.Driver')\
.option('dbtable','new_table')\
.option('user','root')\
.load()
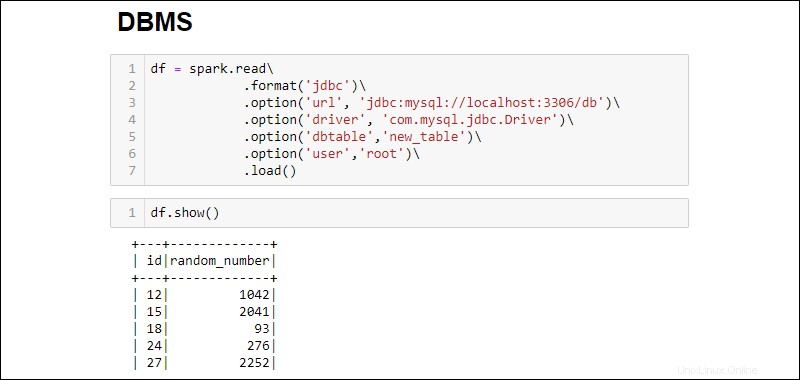
Přidané možnosti jsou následující:
- URL je
localhost:3306pokud server běží lokálně. V opačném případě získejte adresu URL svého databázového serveru. - Název databáze rozšiřuje adresu URL pro přístup ke konkrétní databázi na serveru. Pokud se například databáze jmenuje
dba server běží lokálně, úplná adresa URL pro navázání připojení jejdbc:mysql://localhost:3306/db. - Název tabulky zajišťuje, že celá databázová tabulka je vtažena do DataFrame. Použijte
.option('query', '<query>')místo.option('dbtable', '<table name>')ke spuštění konkrétního dotazu namísto výběru celé tabulky. - Použijte uživatelské jméno a heslo databáze pro navázání spojení. Při spuštění bez hesla vynechejte zadanou možnost.