Úvod
Dnes máme mnoho bezplatných řešení pro zpracování velkých dat. Mnoho společností také nabízí specializované podnikové funkce, které doplňují platformy s otevřeným zdrojovým kódem.
Tento trend začal v roce 1999 s vývojem Apache Lucene. Rámec se brzy stal open-source a vedl k vytvoření Hadoop. Dva z nejpopulárnějších rámců pro zpracování velkých dat, které se dnes používají, jsou open source – Apache Hadoop a Apache Spark.
Vždy existuje otázka, který rámec použít, Hadoop nebo Spark.
V tomto článku se dozvíte Klíčové rozdíly mezi Hadoopem a Sparkem a kdy byste si měli vybrat jedno nebo druhé nebo je použít společně.

Poznámka :Než se vrhneme na přímé srovnání Hadoop vs. Spark, krátce se podíváme na tyto dva rámce.
Co je Hadoop?
Apache Hadoop je platforma, která zpracovává velké datové sady distribuovaným způsobem. Rámec používá MapReduce rozdělit data do bloků a přiřadit části k uzlům v klastru. MapReduce pak zpracovává data paralelně na každém uzlu, aby vytvořil jedinečný výstup.
Každý stroj v clusteru ukládá a zpracovává data. Hadoop ukládá data na disky pomocí HDFS . Software nabízí bezproblémové možnosti škálovatelnosti. Můžete začít s pouhým jedním strojem a poté rozšířit na tisíce a přidat jakýkoli typ podnikového nebo komoditního hardwaru.
Ekosystém Hadoop je vysoce odolný vůči poruchám. Hadoop pro dosažení vysoké dostupnosti nezávisí na hardwaru. Ve svém jádru je Hadoop postaven tak, aby hledal selhání na aplikační vrstvě. Replikováním dat napříč clusterem může framework v případě selhání některého hardwaru vytvořit chybějící části z jiného místa.
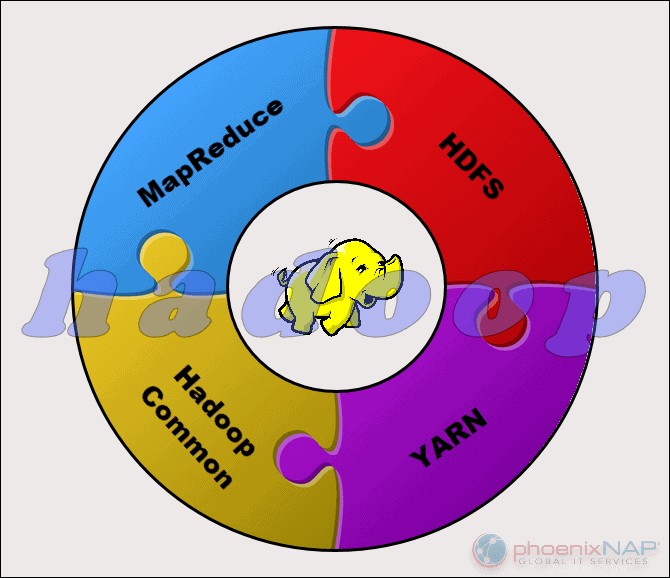
Projekt Apache Hadoop se skládá ze čtyř hlavních modulů:
- HDFS – Distribuovaný souborový systém Hadoop. Toto je souborový systém, který spravuje ukládání velkých sad dat v clusteru Hadoop. HDFS zvládne jak strukturovaná, tak nestrukturovaná data. Úložný hardware může sahat od libovolných pevných disků pro spotřebitele až po podnikové disky.
- MapReduce. Zpracovatelská složka ekosystému Hadoop. Přiřazuje datové fragmenty z HDFS k samostatným mapovým úlohám v clusteru. MapReduce zpracovává kousky paralelně, aby spojil kousky do požadovaného výsledku.
- PŘÍZE. Ještě další vyjednavač zdrojů. Zodpovědný za správu výpočetních zdrojů a plánování úloh.
- Hadoop Common. Sada běžných knihoven a utilit, na kterých závisí ostatní moduly. Jiný název pro tento modul je Hadoop core, protože poskytuje podporu pro všechny ostatní komponenty Hadoop.
Povaha Hadoopu jej zpřístupňuje každému, kdo to potřebuje. Open source komunita je velká a připravila cestu k přístupnému zpracování velkých dat.
Co je Spark?
Apache Spark je open-source nástroj. Tento rámec může běžet v samostatném režimu nebo na cloudu nebo správci clusteru, jako je Apache Mesos, a na dalších platformách. Je navržen pro rychlý výkon a využívá RAM pro ukládání do mezipaměti a zpracování dat.
Spark provádí různé typy velkých objemů dat. To zahrnuje dávkové zpracování podobné MapReduce, stejně jako zpracování streamů v reálném čase, strojové učení, grafové výpočty a interaktivní dotazy. Díky snadno použitelným rozhraním API na vysoké úrovni se Spark může integrovat s mnoha různými knihovnami, včetně PyTorch a TensorFlow. Chcete-li zjistit rozdíl mezi těmito dvěma knihovnami, podívejte se na náš článek o PyTorch vs. TensorFlow.
Spark engine byl vytvořen s cílem zlepšit efektivitu MapReduce a zachovat jeho výhody. I když Spark nemá svůj souborový systém, může přistupovat k datům na mnoha různých úložných řešeních. Datová struktura, kterou Spark používá, se nazývá Resilient Distributed Dataset nebo RDD.
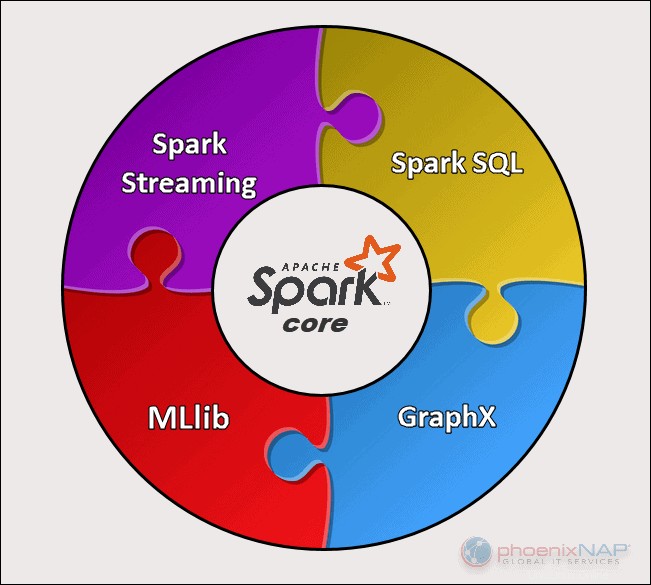
Apache Spark má pět hlavních součástí:
- Apache Spark Core . Základ celého projektu. Spark Core zodpovídá za nezbytné funkce, jako je plánování, odesílání úloh, vstupní a výstupní operace, obnova chyb atd. Nad ním jsou postaveny další funkce.
- Spark Streaming. Tato komponenta umožňuje zpracování živých datových toků. Data mohou pocházet z mnoha různých zdrojů, včetně Kafky, Kinesis, Flume atd.
- Spark SQL . Spark používá tuto komponentu ke shromažďování informací o strukturovaných datech a o tom, jak jsou data zpracovávána.
- Knihovna strojového učení (MLlib) . Tato knihovna se skládá z mnoha algoritmů strojového učení. Cílem MLlib je škálovatelnost a zpřístupnění strojového učení.
- GraphX . Sada rozhraní API používaná k usnadnění úloh analýzy grafů.
Klíčové rozdíly mezi Hadoopem a Sparkem
Následující části nastiňují hlavní rozdíly a podobnosti mezi těmito dvěma rámci. Podíváme se na Hadoop vs. Spark z více úhlů.
Některé z nich jsou náklady , výkon , zabezpečení a snadné použití .
Níže uvedená tabulka poskytuje přehled závěrů učiněných v následujících částech.
Porovnání hadoopů a jisker
| Kategorie pro srovnání | Hadoop | Spark |
| Výkon | Pomalší výkon, používá disky pro ukládání a závisí na rychlosti čtení a zápisu disku. | Rychlý výkon v paměti s omezeným počtem operací čtení a zápisu na disk. |
| Cena | Platforma s otevřeným zdrojovým kódem, jejíž provoz je levnější. Používá cenově dostupný spotřební hardware. Snadněji najdete vyškolené odborníky na Hadoop. | Platforma s otevřeným zdrojovým kódem, ale spoléhá na paměť pro výpočty, což značně zvyšuje provozní náklady. |
| Zpracování dat | Nejlepší pro dávkové zpracování. Používá MapReduce k rozdělení velké datové sady do klastru pro paralelní analýzu. | Vhodné pro iterativní analýzu dat a analýzu dat v přímém přenosu. Pracuje s RDD a DAG pro spouštění operací. |
| Tolerance chyb | Systém vysoce odolný proti chybám. Replikuje data napříč uzly a používá je v případě problému. | Sleduje proces vytváření bloku RDD a poté může znovu sestavit datovou sadu, když oddíl selže. Spark může také použít DAG k opětovnému sestavení dat mezi uzly. |
| Škálovatelnost | Snadno škálovatelné přidáním uzlů a disků pro úložiště. Podporuje desítky tisíc uzlů bez známého limitu. | Trochu náročnější na škálování, protože při výpočtech spoléhá na RAM. Podporuje tisíce uzlů v clusteru. |
| Zabezpečení | Extrémně bezpečné. Podporuje LDAP, ACL, Kerberos, SLA atd. | Nezabezpečeno. Ve výchozím nastavení je zabezpečení vypnuto. Spoléhá na integraci s Hadoop k dosažení potřebné úrovně zabezpečení. |
| Snadné použití a Jazyková podpora | Obtížnější použití s méně podporovanými jazyky. Používá Java nebo Python pro aplikace MapReduce. | Uživatelsky přívětivější. Umožňuje interaktivní režim shellu. API mohou být napsána v jazycích Java, Scala, R, Python, Spark SQL. |
| Strojové učení | Pomalejší než Spark. Datové fragmenty mohou být příliš velké a vytvářet úzká hrdla. Mahout je hlavní knihovna. | Mnohem rychlejší díky zpracování v paměti. Pro výpočty používá MLlib. |
| Plánování a správa zdrojů | Používá externí řešení. PŘÍZE je nejběžnější možností pro správu zdrojů. Oozie je k dispozici pro plánování pracovních postupů. | Má vestavěné nástroje pro alokaci zdrojů, plánování a monitorování. |
Výkon
Když se podíváme na Hadoop vs. Spark z hlediska toho, jak zpracovávají data , nemusí se zdát přirozené porovnávat výkon těchto dvou rámců. Přesto můžeme nakreslit čáru a získat jasnou představu o tom, který nástroj je rychlejší.
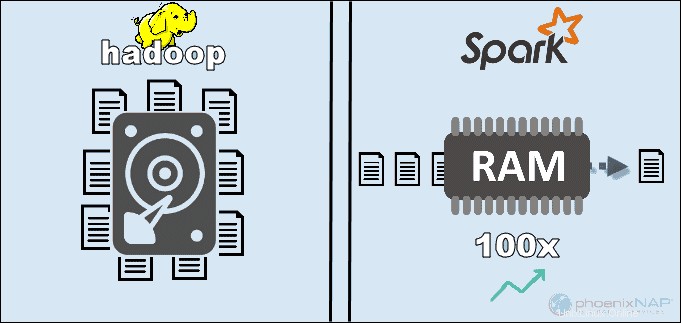
Díky přístupu k datům uloženým lokálně na HDFS, Hadoop zvyšuje celkový výkon. Nehodí se však se zpracováním Spark v paměti. Podle tvrzení Apache se zdá, že Spark je 100x rychlejší při použití RAM pro výpočty než Hadoop s MapReduce.
Dominance zůstala u třídění dat na discích. Spark byl 3x rychlejší a potřeboval 10x méně uzlů ke zpracování 100 TB dat na HDFS. Toto měřítko stačilo k vytvoření světového rekordu v roce 2014.
Hlavním důvodem této nadřazenosti Sparku je to, že nečte a nezapisuje mezilehlá data na disky, ale využívá RAM. Hadoop ukládá data do mnoha různých zdrojů a poté je zpracovává v dávkách pomocí MapReduce.
Všechny výše uvedené mohou umístit Spark jako absolutního vítěze. Pokud je však velikost dat větší než dostupná RAM, je Hadoop logičtější volbou. Dalším bodem, který je třeba vzít v úvahu, jsou náklady na provoz těchto systémů.
Cena
Když porovnáme Hadoop vs. Spark s ohledem na náklady, musíme sáhnout hlouběji, než je cena softwaru. Obě platformy jsouotevřené a zcela zdarma. Nicméně pro získání hrubých celkových nákladů na vlastnictví (TCO) je třeba vzít v úvahu náklady na infrastrukturu, údržbu a vývoj.
Nejvýznamnějším faktorem v kategorii nákladů je základní hardware, který potřebujete ke spuštění těchto nástrojů. Protože Hadoop spoléhá na jakýkoli typ diskového úložiště pro zpracování dat jsou náklady na jeho provoz relativně nízké.
Na druhou stranu Spark závisí na výpočtech v paměti pro zpracování dat v reálném čase. Rozdělení uzlů se spoustou paměti RAM tedy značně zvyšuje náklady na vlastnictví.
Další starostí je vývoj aplikací. Hadoop existuje déle než Spark a je méně náročné najít vývojáře softwaru.
Výše uvedené body naznačují, že infrastruktura Hadoop je nákladově efektivnější . I když je toto tvrzení správné, musíme připomenout, že Spark zpracovává data mnohem rychleji. K dokončení stejného úkolu tedy vyžaduje menší počet strojů.
Zpracování dat
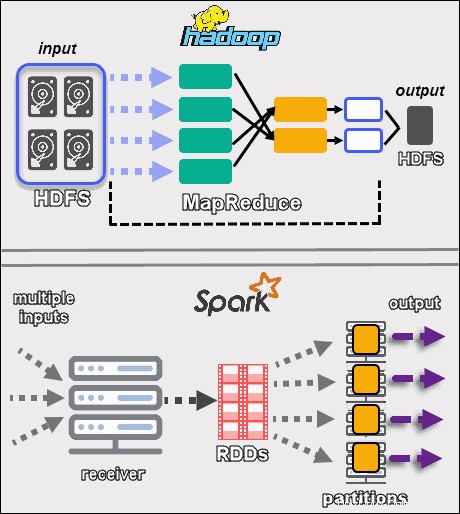
Tyto dva rámce zpracovávají data zcela odlišným způsobem . Přestože Hadoop s MapReduce i Spark s RDD zpracovávají data v distribuovaném prostředí, Hadoop je vhodnější pro dávkové zpracování. Naproti tomu Spark září zpracováním v reálném čase.
Cílem Hadoopu je ukládat data na disky a následně je paralelně analyzovat v dávkách v distribuovaném prostředí. MapReduce nevyžaduje velké množství paměti RAM ke zpracování velkých objemů dat. Hadoop se při ukládání spoléhá na každodenní hardware a nejlépe se hodí pro lineární zpracování dat.
Apache Spark pracuje sodolnými distribuovanými datovými sadami (RDD ). RDD je distribuovaná sada prvků uložených v oddílech na uzlech v clusteru. Velikost RDD je obvykle příliš velká na to, aby ji zvládl jeden uzel. Proto Spark rozděluje RDD k nejbližším uzlům a provádí operace paralelně. Systém sleduje všechny akce provedené na RDD pomocí Směrovaného acyklického grafu (DAG ).
Díky výpočtům v paměti a vysokoúrovňovým rozhraním API Spark efektivně zpracovává živé proudy nestrukturovaných dat. Kromě toho jsou data uložena v předem definovaném počtu oddílů. Jeden uzel může mít tolik oddílů, kolik je potřeba, ale jeden oddíl se nemůže rozšířit na jiný uzel.
Tolerance chyb
Když už mluvíme o Hadoop vs. Spark v kategorii odolnosti proti chybám, můžeme říci, že obě poskytují úctyhodnou úroveň zvládání poruch . Také můžeme říci, že způsob, jakým přistupují k toleranci chyb, je odlišný.
Hadoop má jako základ svého fungování odolnost proti chybám. Mnohokrát replikuje data napříč uzly. V případě, že dojde k problému, systém obnoví práci vytvořením chybějících bloků z jiných míst. Hlavní uzly sledují stav všech podřízených uzlů. A konečně, pokud podřízený uzel nereaguje na ping od hlavního, hlavní přiřadí čekající úlohy jinému podřízenému uzlu.
Spark používá bloky RDD k dosažení odolnosti proti chybám. Systém sleduje, jak je neměnná datová sada vytvořena. Poté může v případě problému restartovat proces. Spark může přestavět data v clusteru pomocí DAG sledování pracovních postupů. Tato datová struktura umožňuje Sparku zvládnout selhání v ekosystému distribuovaného zpracování dat.
Škálovatelnost
Hranice mezi Hadoopem a Sparkem je v této sekci rozmazaná. Hadoop používá HDFS k řešení velkých dat. Když objem dat rychle roste, Hadoop může rychle škálovat, aby vyhovoval poptávce. Protože Spark nemá svůj souborový systém, musí se spoléhat na HDFS, když jsou data příliš velká na to, aby je zvládla.
Clustery lze snadno rozšířit a zvýšit výpočetní výkon přidáním dalších serverů do sítě. Výsledkem je, že počet uzlů v obou rámcích může dosáhnout tisíců. Neexistuje žádné pevné omezení počtu serverů, které můžete přidat do každého clusteru, a množství dat, které můžete zpracovat.
Některá z potvrzených čísel zahrnují 8 000 strojů v prostředí Spark s petabajty dat. Když mluvíme o klastrech Hadoop, je dobře známo, že obsahují desítky tisíc strojů a téměř exabajt dat.
Snadné použití a podpora programovacích jazyků
Spark může být novější framework s ne tolika dostupnými odborníky jako Hadoop, ale je známo, že je uživatelsky přívětivější. Naproti tomu Spark poskytuje podporu pro více jazyků vedle nativního jazyka (Scala):Java, Python, R a Spark SQL. To umožňuje vývojářům používat programovací jazyk, který preferují.
Rámec Hadoop je založen na Javě . Dva hlavní jazyky pro psaní kódu MapReduce jsou Java nebo Python. Hadoop nemá interaktivní režim, který by uživatelům pomáhal. Integruje se však s nástroji Pig a Hive pro usnadnění psaní složitých programů MapReduce.
Kromě podpory rozhraní API ve více jazycích Spark vítězí v sekci snadného použití s jeho interaktivním režimem. Shell Spark můžete použít k interaktivní analýze dat pomocí Scala nebo Python. Shell poskytuje okamžitou zpětnou vazbu k dotazům, díky čemuž je použití Sparku jednodušší než Hadoop MapReduce.
Další věcí, která dává Sparku navrch, je to, že programátoři mohou znovu použít existující kód tam, kde je to možné. Vývojáři tak mohou zkrátit dobu vývoje aplikací. Historická a streamovaná data lze kombinovat, aby byl tento proces ještě efektivnější.
Zabezpečení
Při srovnání zabezpečení Hadoop vs. Spark pustíme kočku hned z pytle – Hadoop je jasný vítěz . Především zabezpečení Sparku je ve výchozím nastavení vypnuto. To znamená, že pokud tento problém nevyřešíte, vaše nastavení bude odhaleno.
Zabezpečení Sparku můžete zlepšit zavedením ověřování prostřednictvím sdíleného tajemství nebo protokolování událostí. To však na produkční zátěž nestačí.
Naproti tomu Hadoop pracuje s více metodami ověřování a řízení přístupu. Nejobtížnější implementací je ověřování Kerberos. Pokud je Kerberos příliš obtížné zvládnout, Hadoop také podporuje Ranger , LDAP , ACL , meziuzlové šifrování , standardní oprávnění k souboru na HDFS a Oprávnění na úrovni služeb .
Spark však může dosáhnout adekvátní úrovně zabezpečení integrací s Hadoop . Tímto způsobem může Spark používat všechny metody dostupné pro Hadoop a HDFS. Kromě toho, když Spark běží na YARN, můžete využít výhody dalších autentizačních metod, které jsme zmínili výše.
Strojové učení
Strojové učení je iterativní proces, který nejlépe funguje s využitím in-memory computingu. Z tohoto důvodu se Spark ukázal jako rychlejší řešení v této oblasti.
Důvodem je to, že Hadoop MapReduce rozděluje úlohy na paralelní úlohy, které mohou být příliš velké pro algoritmy strojového učení. Tento proces vytváří problémy s výkonem I/O v těchto aplikacích Hadoop.
Knihovna Mahout je hlavní platformou strojového učení v clusterech Hadoop. Mahout spoléhá na MapReduce při provádění shlukování, klasifikace a doporučení. Samsara začala tento projekt nahrazovat.
Spark přichází s výchozí knihovnou strojového učení MLlib. Tato knihovna provádí iterativní výpočty ML v paměti. Zahrnuje nástroje pro provádění regrese, klasifikace, persistence, vytváření potrubí, vyhodnocování a mnoho dalších.
Spark s MLlib se ukázal být devětkrát rychlejší než Apache Mahout v diskovém prostředí Hadoop. Když potřebujete efektivnější výsledky, než jaké nabízí Hadoop, Spark je lepší volbou pro strojové učení.
Plánování a správa zdrojů
Hadoop nemá vestavěný plánovač. Využívá externí řešení pro správu zdrojů a plánování. Pomocí ResourceManager a NodeManager YARN je zodpovědný za správu zdrojů v clusteru Hadoop. Jedním z dostupných nástrojů pro plánování pracovních postupů je Oozie.
YARN se nezabývá správou stavu jednotlivých aplikací. Přiděluje pouze dostupný výpočetní výkon.
Hadoop MapReduce funguje se zásuvnými moduly, jako je CapacityScheduler a FairScheduler . Tyto plánovače zajišťují, že aplikace získávají nezbytné zdroje podle potřeby při zachování účinnosti clusteru. FairScheduler poskytuje aplikacím potřebné zdroje a zároveň sleduje, že nakonec všechny aplikace dostanou stejný přidělený zdroj.
Spark má naopak tyto funkce zabudované. Plánovač DAG je zodpovědný za rozdělení operátorů do etap. Každá fáze má několik úloh, které DAG naplánuje a Spark musí provést.
Spark Scheduler a Block Manager provádějí plánování úloh a úloh, monitorování a distribuci zdrojů v clusteru.
Případy použití Hadoop versus Spark
Když se podíváme na Hadoop versus Spark ve výše uvedených částech, můžeme extrahovat několik případů použití pro každý rámec.
Mezi případy použití Hadoop patří:
- Zpracování velkých datových sad v prostředích, kde velikost dat přesahuje dostupnou paměť.
- Budování infrastruktury pro analýzu dat s omezeným rozpočtem.
- Dokončování úloh, kde nejsou vyžadovány okamžité výsledky a čas není omezujícím faktorem.
- Dávkové zpracování s úlohami využívajícími operace čtení a zápisu z disku.
- Analýza historických a archivních dat.
Se Sparkem můžeme oddělit následující případy použití, kde překonává Hadoop:
- Analýza dat streamu v reálném čase.
- Když jde o čas, Spark poskytuje rychlé výsledky pomocí výpočtů v paměti.
- Zacházení s řetězci paralelních operací pomocí iterativních algoritmů.
- Grafově paralelní zpracování pro modelování dat.
- Všechny aplikace strojového učení.
Poznámka :Pokud jste se rozhodli, můžete postupovat podle našeho průvodce, jak nainstalovat Hadoop na Ubuntu nebo jak nainstalovat Spark na Ubuntu. Pokud pracujete ve Windows 10, přečtěte si část Jak nainstalovat Spark na Windows 10.
Hadoop nebo Spark?
Hadoop a Spark jsou technologie pro zpracování velkých dat. Kromě toho jde o značně odlišné rámce ve způsobu, jakým spravují a zpracovávají data.
Podle předchozích částí tohoto článku se zdá, že Spark je jasným vítězem. I když to může být do určité míry pravda, ve skutečnosti nejsou vytvořeny, aby si navzájem konkurovaly, ale spíše se doplňovaly.
Samozřejmě, jak jsme uvedli dříve v tomto článku, existují případy použití, kdy je jeden nebo druhý rámec logičtější volbou. Ve většině ostatních aplikací Hadoop a Spark fungují nejlépe společně . Jako nástupce zde Spark není proto, aby nahradil Hadoop, ale aby využil jeho funkcí k vytvoření nového, vylepšeného ekosystému.
Kombinací těchto dvou může Spark využít funkce, které mu chybí, jako je systém souborů. Hadoop ukládá obrovské množství dat pomocí dostupného hardwaru a později provádí analýzy, zatímco Spark přináší zpracování v reálném čase pro zpracování příchozích dat. Bez Hadoopu mohou obchodní aplikace postrádat zásadní historická data, která Spark nezpracovává.
V tomto kooperativním prostředí Spark také využívá výhod zabezpečení a správy zdrojů Hadoop. S YARN je klastrování Spark a správa dat mnohem jednodušší. Úlohy Spark můžete automaticky spouštět pomocí jakýchkoli dostupných prostředků.
Tato spolupráce poskytuje nejlepší výsledky v retroaktivní analýze transakčních dat, pokročilé analýze a zpracování dat IoT. Všechny tyto případy použití jsou možné v jednom prostředí.
Tvůrci Hadoop a Spark zamýšleli, aby byly tyto dvě platformy kompatibilní a poskytovaly optimální výsledky vhodné pro jakékoli obchodní požadavky.