Úvod
Elasticsearch je škálovatelný vyhledávač v reálném čase nasazený v clusterech. V kombinaci s orchestrací Kubernetes lze Elasticsearch snadno konfigurovat, spravovat a škálovat.
Nasazení clusteru Elasticsearch ve výchozím nastavení vytvoří tři moduly. Každý modul slouží všem třem funkcím:master, data a client. Nejlepším postupem by však bylo nasadit více vyhrazených modulů Elasticsearch pro každou roli ručně.
Tento článek vysvětluje, jak nasadit Elasticsearch na Kubernetes na sedmi podech ručně a pomocí předem vytvořeného Helm diagramu.

Předpoklady
- Cluster Kubernetes (použili jsme Minikube).
- Správce balíčků Helm.
- Nástroj příkazového řádku kubectl.
- Přístup k příkazovému řádku nebo terminálu.
Jak ručně nasadit Elasticsearch na Kubernetes
Osvědčeným postupem je použít sedm modulů v clusteru Elasticsearch:
- Tři hlavní moduly pro správu clusteru.
- Dva datové moduly pro ukládání dat a zpracování dotazů.
- Dva klientské (nebo koordinační) moduly pro řízení provozu.
Ruční nasazení Elasticsearch na Kubernetes se sedmi vyhrazenými moduly je jednoduchý proces, který vyžaduje nastavení hodnot Helm podle role.
Krok 1:Nastavení Kubernetes
1. Cluster vyžaduje značné zdroje. Nastavte CPU Minikube na minimálně 4 a paměť na 8192 MB:
minikube config set cpus 4
minikube config set memory 8192
2. Otevřete terminál a spusťte minikube s následujícími parametry:
minikube start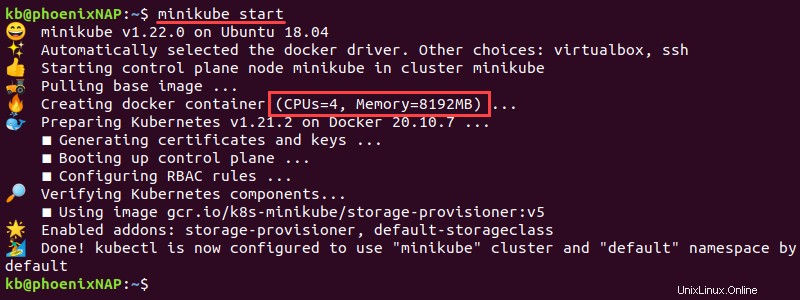
Instance začíná s nakonfigurovanou pamětí a CPU.
3. Minikube vyžaduje values.yaml soubor pro spuštění Elasticsearch. Stáhněte soubor pomocí:
curl -O https://raw.githubusercontent.com/elastic/helm-charts/master/elasticsearch/examples/minikube/values.yaml
Soubor obsahuje informace použité v dalším kroku pro všechny tři konfigurace pod.
Krok 2:Nastavení hodnot podle role podu
1. Zkopírujte obsah souboru values.yaml pomocí cp příkaz do tří různých konfiguračních souborů pod:
cp values.yaml master.yaml
cp values.yaml data.yaml
cp values.yaml client.yaml
2. Pomocí ls vyhledejte čtyři soubory YAML příkaz:
ls -l *.yaml3. Otevřete soubor master.yaml soubor pomocí textového editoru a na začátek přidejte následující konfiguraci:
# master.yaml
---
clusterName: "elasticsearch"
nodeGroup: "master"
roles:
master: "true"
ingest: "false"
data: "false"
replicas: 3
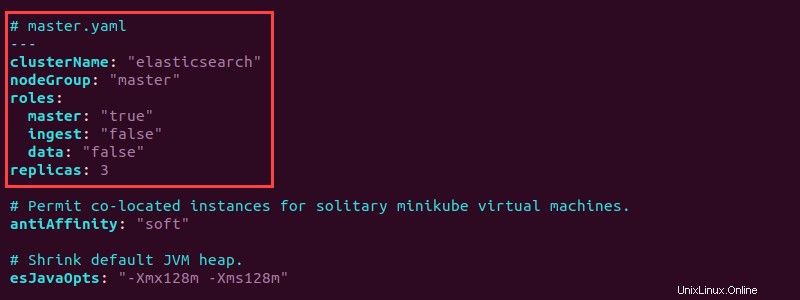
Konfigurace nastaví skupinu uzlů na master v elasticsearch cluster a nastaví hlavní roli na "true" . Navíc master.yaml vytvoří tři repliky hlavního uzlu.
Úplné znění master.yaml vypadá následovně:
# master.yaml
---
clusterName: "elasticsearch"
nodeGroup: "master"
roles:
master: "true"
ingest: "false"
data: "false"
replicas: 3
# Permit co-located instances for solitary minikube virtual machines.
antiAffinity: "soft
# Shrink default JVM heap.
esJavaOpts: "-Xmx128m -Xms128m"
# Allocate smaller chunks of memory per pod.
resources:
requests:
cpu: "100m"
memory: "512M"
limits:
cpu: "1000m"
memory: "512M"
# Request smaller persistent volumes.
volumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "standard"
resources:
requests:
storage: 100M
4. Uložte soubor a zavřete jej.
5. Otevřete soubor data.yaml a přidejte na začátek následující informace pro konfiguraci datových modulů:
# data.yaml
---
clusterName: "elasticsearch"
nodeGroup: "data"
roles:
master: "false"
ingest: "true"
data: "true"
replicas: 2
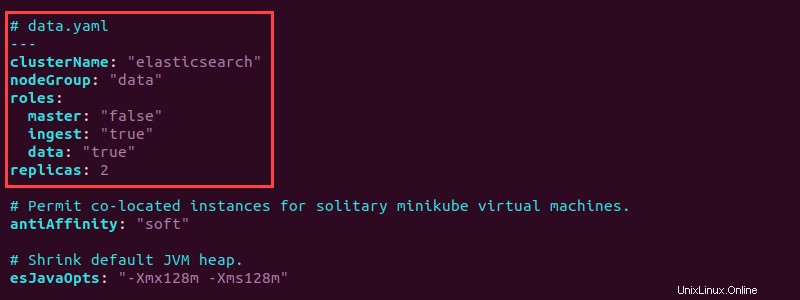
Nastavení vytvoří dvě repliky datového modulu. Nastavte datovou i ingestovou roli na "true" . Uložte soubor a zavřete.
6. Otevřete soubor client.yaml a na začátek přidejte následující konfigurační informace:
# client.yaml
---
clusterName: "elasticsearch"
nodeGroup: "client"
roles:
master: "false"
ingest: "false"
data: "false"
replicas: 2
service:
type: "LoadBalancer"
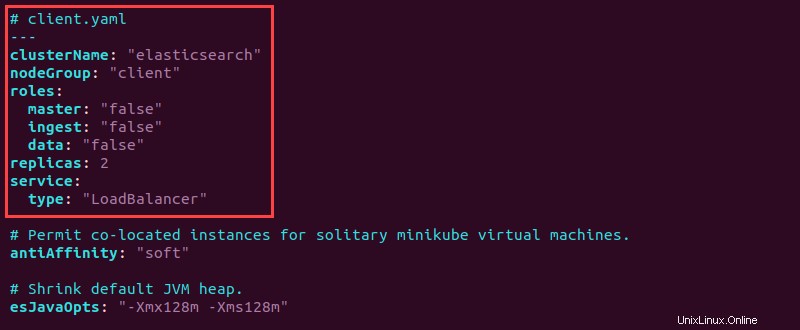
7. Uložte soubor a zavřete jej.
Klient má všechny role nastaveny na "false" protože klient zpracovává požadavky na služby. Typ služby je označen jako "LoadBalancer" aby byly požadavky na služby vyrovnány rovnoměrně napříč všemi uzly.
Krok 3:Nasaďte Elasticsearch Pods podle role
1. Přidejte úložiště Helm:
helm repo add elastic https://helm.elastic.co
2. Použijte helm install třikrát, jednou pro každý vlastní soubor YAML vytvořený v předchozím kroku:
helm install elasticsearch-multi-master elastic/elasticsearch -f ./master.yaml
helm install elasticsearch-multi-data elastic/elasticsearch -f ./data.yaml
helm install elasticsearch-multi-client elastic/elasticsearch -f ./client.yaml
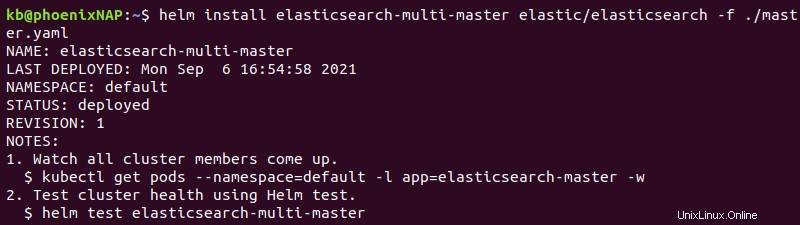
Výstup vytiskne podrobnosti o nasazení.
3. Počkejte na nasazení členů klastru. Ke kontrole průběhu a potvrzení dokončení použijte následující příkaz:
kubectl get pods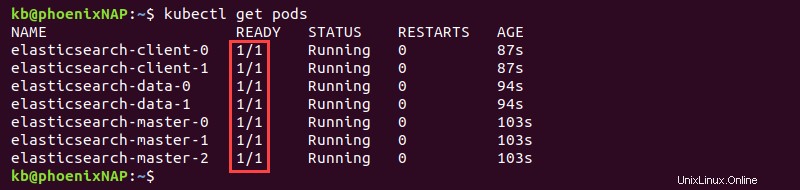
Na výstupu se zobrazí READY sloupec s hodnotami 1/1 jakmile bude nasazení dokončeno pro všech sedm modulů.
Krok 4:Otestujte připojení
1. Pro místní přístup k Elasticsearch, přesměrujte port 9200 pomocí kubectl příkaz:
kubectl port-forward service/elasticsearch-master
Příkaz předá připojení a ponechá jej otevřené. Nechte okno terminálu spuštěné a přejděte k dalšímu kroku.
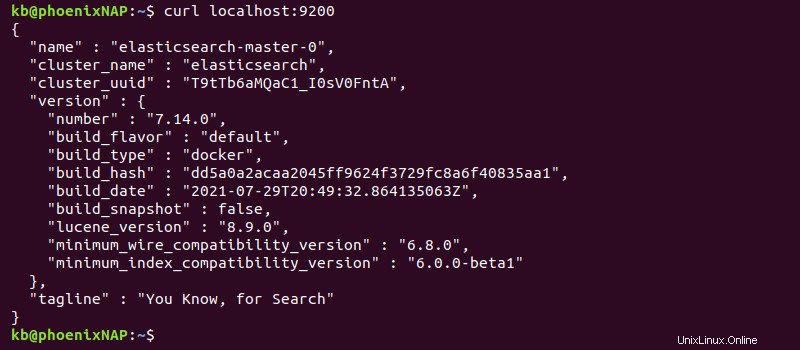
2. Na další kartě terminálu otestujte připojení pomocí:
curl localhost:9200Výstup vytiskne informace o nasazení.
Případně přejděte na localhost:9200 z prohlížeče.
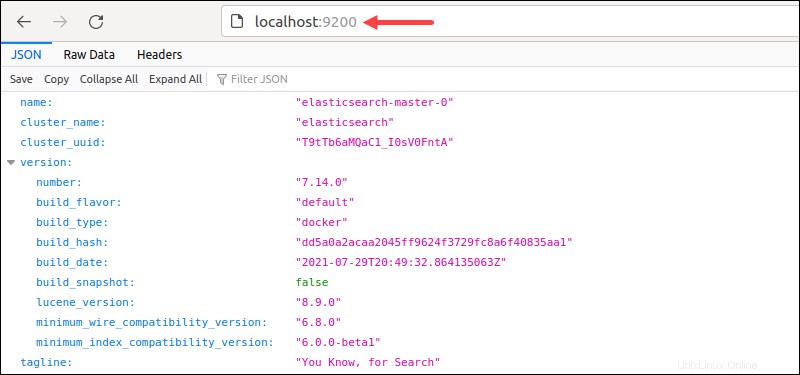
Výstup zobrazuje podrobnosti clusteru ve formátu JSON, což znamená, že nasazení bylo úspěšné.
Jak nasadit elastické vyhledávání se sedmi moduly pomocí předem sestaveného diagramu kormidla
Předem sestavený graf Helm pro nasazení Elasticsearch na sedmi vyhrazených modulech je k dispozici v úložišti Bitnami. Instalace grafu tímto způsobem zabrání ručnímu vytváření konfiguračních souborů.
Krok 1:Nastavení Kubernetes
1. Přidělte alespoň 4 CPU a 8192 MB paměti:
minikube config set cpus 4
minikube config set memory 8192
2. Spusťte Minikube:
minikube startInstance Minikube začíná se zadanou konfigurací.
Krok 2:Přidejte úložiště Bitnami a nasaďte graf Elasticsearch
1. Přidejte úložiště Bitnami Helm pomocí:
helm repo add bitnami https://charts.bitnami.com/bitnami
2. Nainstalujte graf spuštěním:
helm install elasticsearch --set master.replicas=3,coordinating.service.type=LoadBalancer bitnami/elasticsearch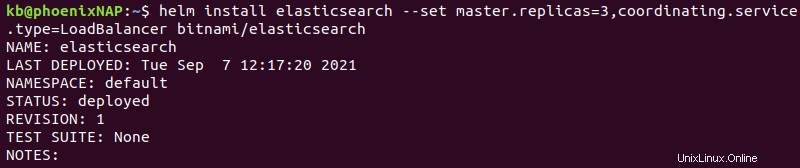
Příkaz má následující možnosti:
- Elasticsearch se instaluje pod názvem vydání
elasticsearch. master.replicas=3přidá tři hlavní repliky do clusteru. Doporučujeme zůstat u tří hlavních uzlů.coordinating.service.type=LoadBalancernastaví klientské uzly tak, aby vyrovnaly požadavky na služby rovnoměrně napříč všemi uzly.
3. Monitorujte nasazení pomocí:
kubectl get pods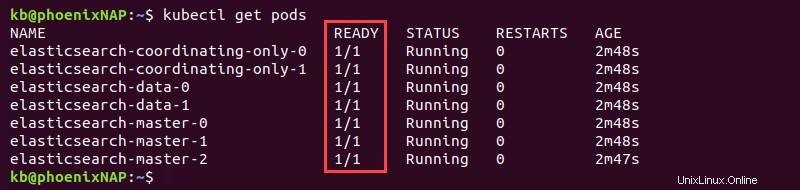
Sedm podů ukazuje 1/1 v READY při plném nasazení Elasticsearch.
Krok 3:Otestujte připojení
1. Předejte připojení na port 9200 :
kubectl port-forward svc/elasticsearch-master 9200Nechte připojení otevřené a pokračujte dalším krokem.
2. Na další kartě terminálu zkontrolujte připojení pomocí:
curl localhost:9200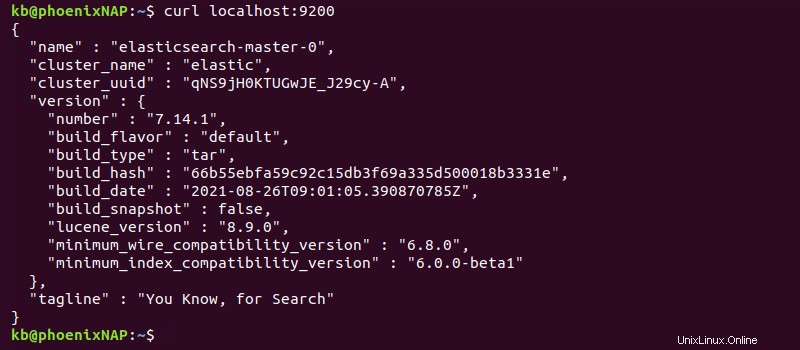
Případně přejděte na stejnou adresu z prohlížeče a zobrazte informace o nasazení ve formátu JSON.