Úvod
Apache Spark je rámec používaný v prostředích clusterových počítačů pro analýzu velkých dat . Tato platforma se stala široce populární díky jejímu snadnému použití a vylepšené rychlosti zpracování dat oproti Hadoopu.
Apache Spark je schopen rozložit pracovní zátěž mezi skupinu počítačů v clusteru a efektivněji zpracovávat velké sady dat. Tento open source engine podporuje širokou škálu programovacích jazyků. To zahrnuje Java, Scala, Python a R.
V tomto tutoriálu se dozvíte, jak nainstalovat Spark na počítač s Ubuntu . Průvodce vám ukáže, jak spustit hlavní a podřízený server a jak načíst shelly Scala a Python. Poskytuje také nejdůležitější příkazy Spark.

Předpoklady
- Systém Ubuntu.
- Přístup k terminálu nebo příkazovému řádku.
- Uživatel s sudo nebo root oprávnění.
Instalujte balíčky požadované pro Spark
Před stažením a nastavením Sparku musíte nainstalovat potřebné závislosti. Tento krok zahrnuje instalaci následujících balíčků:
- JDK
- Scala
- Git
Otevřete okno terminálu a spusťte následující příkaz pro instalaci všech tří balíčků najednou:
sudo apt install default-jdk scala git -yUvidíte, které balíčky se nainstalují.
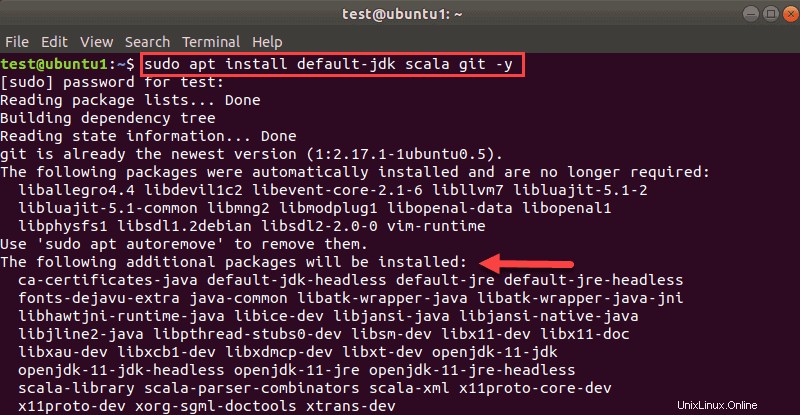
Po dokončení procesu ověřte nainstalované závislosti spuštěním těchto příkazů:
java -version; javac -version; scala -version; git --version
Výstup vytiskne verze, pokud byla instalace úspěšně dokončena pro všechny balíčky.
Stáhněte si a nastavte Spark na Ubuntu
Nyní je třeba stáhnout verzi aplikace Spark, kterou chcete tvoří jejich webové stránky. Budeme používat Spark 3.0.1 s Hadoop 2.7 protože je to nejnovější verze v době psaní tohoto článku.
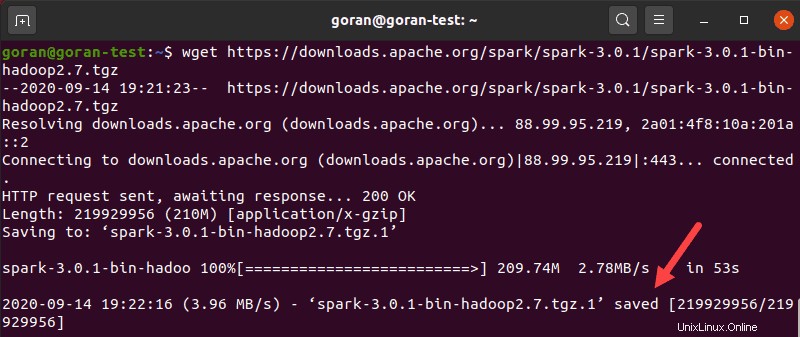
Použijte wget příkaz a přímý odkaz ke stažení archivu Spark:
wget https://downloads.apache.org/spark/spark-3.0.1/spark-3.0.1-bin-hadoop2.7.tgzPo dokončení stahování se zobrazí uloženo zprávu.
Nyní rozbalte uložený archiv pomocí tar:
tar xvf spark-*Nechte proces dokončit. Výstup zobrazuje soubory, které se rozbalují z archivu.
Nakonec přesuňte rozbalený adresář spark-3.0.1-bin-hadoop2.7 na opt/spark adresář.
Použijte mv příkaz k tomu:
sudo mv spark-3.0.1-bin-hadoop2.7 /opt/sparkTerminál nevrací žádnou odpověď, pokud úspěšně přesune adresář. Pokud jméno zadáte špatně, zobrazí se zpráva podobná:
mv: cannot stat 'spark-3.0.1-bin-hadoop2.7': No such file or directory.Konfigurace prostředí Spark
Před spuštěním hlavního serveru musíte nakonfigurovat proměnné prostředí. Existuje několik domovských cest Spark, které musíte přidat do uživatelského profilu.
Použijte echo příkaz k přidání těchto tří řádků do .profile :
echo "export SPARK_HOME=/opt/spark" >> ~/.profile
echo "export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin" >> ~/.profile
echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profileMůžete také přidat cesty exportu úpravou .profile soubor v editoru dle vašeho výběru, jako je nano nebo vim.
Chcete-li například použít nano, zadejte:
nano .profilePo načtení profilu přejděte na konec souboru.
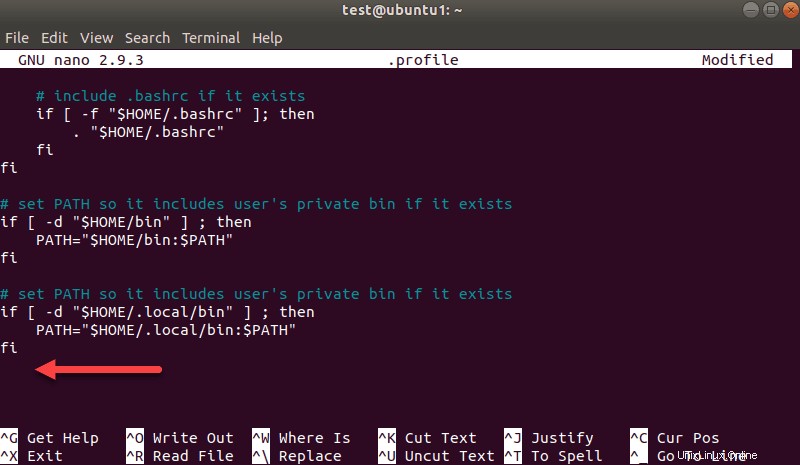
Poté přidejte tyto tři řádky:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_PYTHON=/usr/bin/python3Po zobrazení výzvy ukončete a uložte změny.
Po dokončení přidávání cest načtěte .profile soubor na příkazovém řádku zadáním:
source ~/.profileSpusťte samostatný Spark Master Server
Nyní, když jste dokončili konfiguraci vašeho prostředí pro Spark, můžete spustit hlavní server.
V terminálu zadejte:
start-master.shChcete-li zobrazit uživatelské rozhraní Spark Web, otevřete webový prohlížeč a zadejte adresu IP localhost na portu 8080.
http://127.0.0.1:8080/Stránka zobrazuje vaši Spark URL , stavové informace pro pracovníky, využití hardwarových prostředků atd.
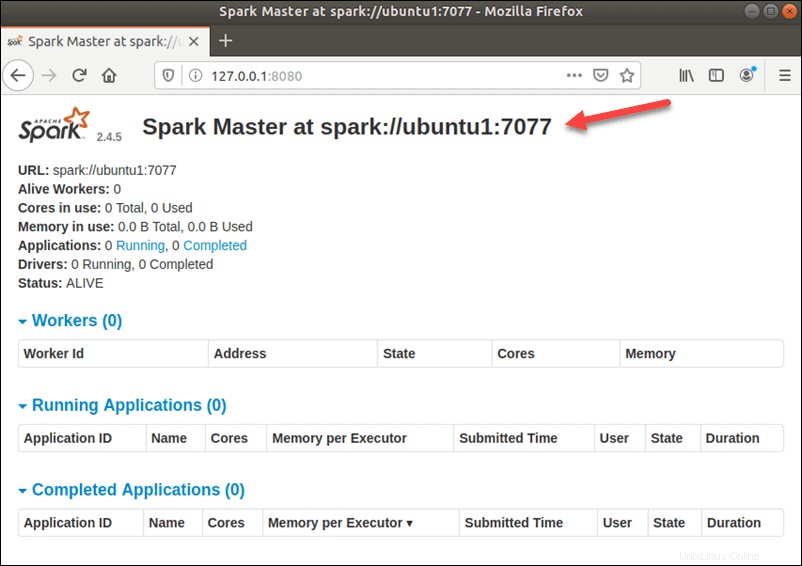
Adresa URL pro Spark Master je název vašeho zařízení na portu 8080. V našem případě je to ubuntu1:8080 . Existují tedy tři možné způsoby, jak načíst webové uživatelské rozhraní Spark Master:
- 127.0.0.1:8080
- localhost:8080
- název zařízení :8080
Spustit Spark Slave Server (spustit pracovní proces)
V tomto samostatném nastavení s jedním serverem spustíme jeden podřízený server spolu s hlavním serverem.
Chcete-li tak učinit, spusťte následující příkaz v tomto formátu:
start-slave.sh spark://master:port
master v příkazu může být IP nebo název hostitele.
V našem případě je to ubuntu1 :
start-slave.sh spark://ubuntu1:7077
Nyní, když je pracovník spuštěn, a pokud znovu načtete webové uživatelské rozhraní Spark Master, měli byste jej vidět v seznamu:
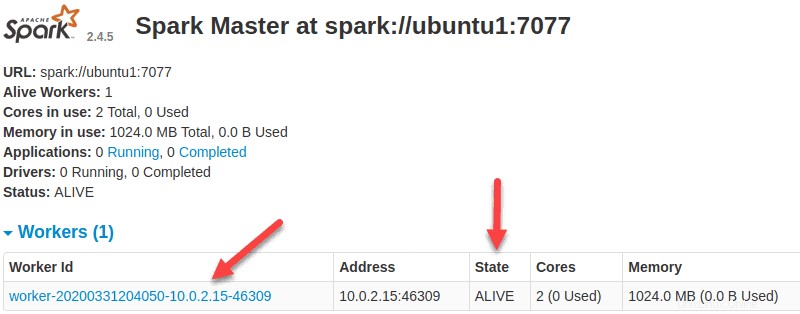
Upřesněte alokaci zdrojů pro pracovníky
Výchozí nastavení při spouštění pracovníka na počítači je použití všech dostupných jader CPU. Počet jader můžete určit předáním -c příznak na start-slave příkaz.
Chcete-li například spustit pracovníka a přiřadit pouze jedno jádro CPU zadejte tento příkaz:
start-slave.sh -c 1 spark://ubuntu1:7077Znovu načtěte webové uživatelské rozhraní Spark Master a potvrďte konfiguraci pracovníka.

Podobně můžete při spouštění pracovníka přiřadit konkrétní množství paměti. Výchozí nastavení je použít jakékoli množství paměti RAM, kterou má váš počítač, mínus 1 GB.
Chcete-li spustit pracovníka a přiřadit mu konkrétní množství paměti, přidejte -m možnost a číslo. Pro gigabajty použijte G a pro megabajty použijte M .
Chcete-li například spustit worker s 512 MB paměti, zadejte tento příkaz:
start-slave.sh -m 512M spark://ubuntu1:7077Znovu načtěte webové uživatelské rozhraní Spark Master, abyste viděli stav pracovníka a potvrdili konfiguraci.

Test Spark Shell
Po dokončení konfigurace a spuštění hlavního a podřízeného serveru otestujte, zda shell Spark funguje.
Načtěte shell zadáním:
spark-shellMěli byste získat obrazovku s upozorněními a informacemi Spark. Scala je výchozí rozhraní, takže se shell načte, když spustíte spark-shell .
Konec výstupu vypadá takto pro verzi, kterou používáme v době psaní této příručky:
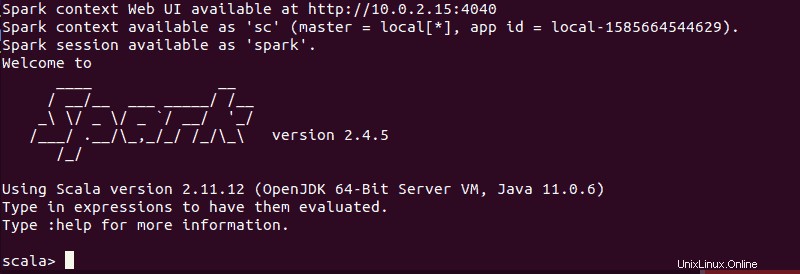
Zadejte :q a stiskněte Enter opustit Scala.
Otestujte Python ve Sparku
Pokud nechcete používat výchozí rozhraní Scala, můžete přejít na Python.
Ujistěte se, že ukončíte Scala a poté spusťte tento příkaz:
pysparkVýsledný výstup vypadá podobně jako ten předchozí. Směrem dolů uvidíte verzi Pythonu.
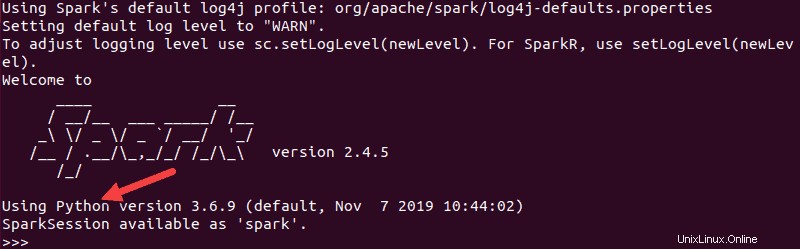
Chcete-li tento shell ukončit, zadejte quit() a stiskněte Enter .
Základní příkazy pro spuštění a zastavení hlavního serveru a pracovníků
Níže jsou uvedeny základní příkazy pro spouštění a zastavování hlavního serveru Apache Spark a pracovníků. Protože toto nastavení je pouze pro jeden počítač, skripty, které spouštíte, jsou standardně nastaveny na localhost.
Začít mistr server instance na aktuálním počítači spusťte příkaz, který jsme použili dříve v příručce:
start-master.shZastavení hlavního instance spuštěná spuštěním skriptu výše, spusťte:
stop-master.shZastavení běžícího pracovníka proces, zadejte tento příkaz:
stop-slave.shStránka Spark Master v tomto případě zobrazuje stav pracovníka jako DEAD.

Můžete spustit hlavní i server instance pomocí příkazu start-all:
start-all.shPodobně můžete zastavit všechny instance pomocí následujícího příkazu:
stop-all.sh