Apache Spark je open-source výpočetní rámec pro zpracování analytických dat a strojového učení ve velkém měřítku. Podporuje různé preferované jazyky, jako je scala, R, Python a Java. Poskytuje nástroje na vysoké úrovni pro streamování jisker, GraphX pro zpracování grafů, SQL, MLLib.
V tomto článku se seznámíte se způsobem instalace a konfigurace Apache Spark na ubuntu. K demonstraci toku v tomto článku jsem použil systém verze Ubuntu 20.04 LTS. Před instalací Apache Spark musíte na svůj systém nainstalovat Scala i scalu.
Instalace Scala
Pokud jste nenainstalovali Javu a Scala, můžete je nainstalovat podle následujícího postupu.
Pro Javu nainstalujeme otevřený JDK 8 nebo si můžete nainstalovat svou preferovanou verzi.
$ sudo apt update
$ sudo apt install openjdk-8-jdk
Pokud potřebujete ověřit instalaci java, můžete provést následující příkaz.
$ java -version

Pokud jde o Scala, scala je objektově orientovaný a funkční programovací jazyk, který jej spojuje do jediného stručného. Scala je kompatibilní jak s javascriptovým runtime, tak s JVM, což vám poskytuje snadný přístup k ekosystému velkých knihoven, který pomáhá při budování vysoce výkonného systému. Spusťte následující příkaz apt pro instalaci scala.
$ sudo apt update
$ sudo apt install scala
Nyní zkontrolujte verzi a ověřte instalaci.
$ scala -version

Instalace Apache Spark
Neexistuje žádné oficiální úložiště apt pro instalaci apache-spark, ale můžete si předkompilovat binární soubor z oficiálních stránek. Ke stažení binárního souboru použijte následující příkaz wget a odkaz.
$ wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Nyní rozbalte stažený binární soubor pomocí následujícího příkazu tar.
$ tar -xzvf spark-3.1.2-bin-hadoop3.2.tgz
Nakonec přesuňte extrahované soubory Spark do adresáře /opt.
$ sudo mv spark-3.1.2-bin-hadoop3.2 /opt/spark
Nastavení proměnných prostředí
Proměnnou cesty pro jiskru ve vašem .profile v souboru, který je potřeba nastavit, aby příkaz fungoval bez úplné cesty, můžete tak učinit buď pomocí příkazu echo, nebo ručně pomocí preferovaného textového editoru. Pro snazší způsob spusťte následující příkaz echo.
$ echo "export SPARK_HOME=/opt/spark" >> ~/.profile
$ echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile
$ echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profile
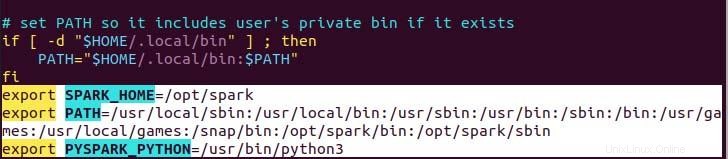
Jak můžete vidět, proměnná path je připojena na konec souboru .profile pomocí operace echo s>>.
Nyní spusťte následující příkaz, abyste použili nové změny proměnné prostředí.
$ source ~/.profile
Nasazení Apache Spark
Nyní jsme pomocí následujícího příkazu nastavili vše, co můžeme spustit jak hlavní službu, tak pracovní službu.
$ start-master.sh
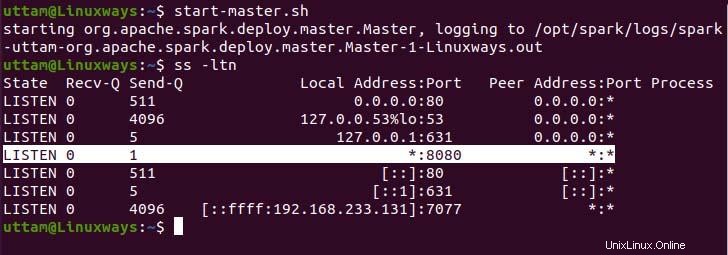
Jak můžete vidět, naše služba spark master běží na portu 8080. Pokud procházíte localhost na portu 8080, což je výchozí port spark. Při procházení adresy URL se můžete setkat s následujícím typem uživatelského rozhraní. Spuštěním pouze hlavní služby nemusíte najít spuštěný žádný pracovní procesor. Když spustíte službu Worker, najdete nový uzel v seznamu stejně jako v následujícím příkladu.
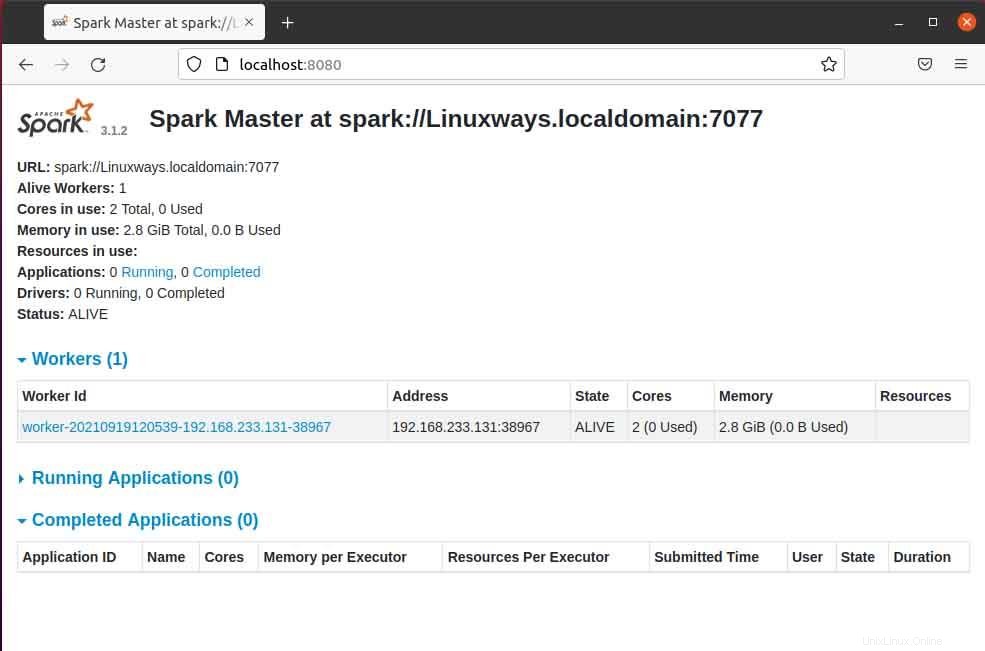
Když otevřete hlavní stránku v prohlížeči, můžete vidět spark master spark://HOST:PORT URL, která se používá k připojení pracovních služeb přes tohoto hostitele. Pro mého aktuálního hostitele je moje hlavní adresa URL sparku spark://Linuxways.localdomain:7077, takže ke spuštění pracovního procesu musíte provést příkaz následujícím způsobem.
$ start-workers.sh <spark-master-url>
Chcete-li spustit následující příkaz ke spuštění pracovních služeb.
$ start-workers.sh spark://Linuxways.localdomain:7077

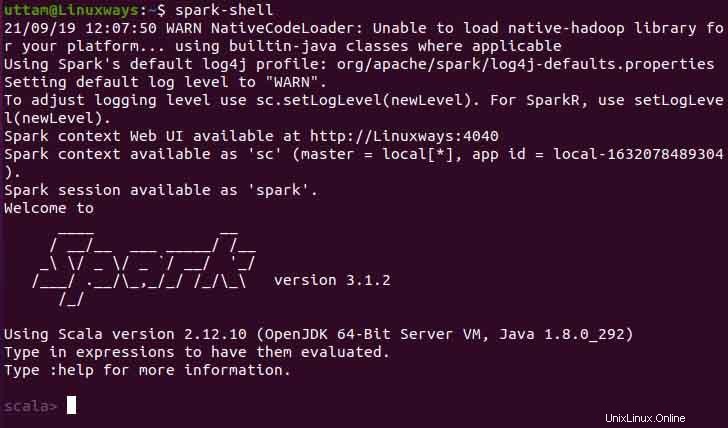
Spark-shell můžete také použít provedením následujícího příkazu.
$ spark-shell
Závěr
Doufám, že z tohoto článku se dozvíte, jak nainstalovat a nakonfigurovat apache spark na ubuntu. V tomto článku jsem se snažil, aby byl proces co nejsrozumitelnější.