Apache Spark je distribuovaný výpočetní systém. Skládá se z hlavního a jednoho nebo více slave, kde master rozděluje práci mezi slave, čímž dává možnost využít naše mnoho počítačů k práci na jednom úkolu. Dalo by se hádat, že se skutečně jedná o mocný nástroj, kde úkoly vyžadují velké výpočty, ale lze je rozdělit na menší části kroků, které lze podřídit otrokům, aby na nich pracovali. Jakmile je náš cluster v provozu, můžeme psát programy, které na něm běží v Pythonu, Javě a Scale.
V tomto tutoriálu budeme pracovat na jednom počítači se systémem Red Hat Enterprise Linux 8 a nainstalujeme Spark master a slave na stejný počítač, ale mějte na paměti, že kroky popisující nastavení slave lze použít na libovolný počet počítačů, čímž se vytvoří skutečný cluster, který dokáže zpracovat velké pracovní zatížení. Přidáme také potřebné soubory jednotek pro správu a spustíme jednoduchý příklad na clusteru dodaném s distribuovaným balíčkem, abychom zajistili, že náš systém bude funkční.
V tomto tutoriálu se naučíte:
- Jak nainstalovat Spark master a slave
- Jak přidat soubory systemd unit
- Jak ověřit úspěšné připojení master-slave
- Jak spustit jednoduchou ukázkovou úlohu v clusteru
 Spark shell s pyspark.
Spark shell s pyspark. Požadavky na software a použité konvence
| Kategorie | Požadavky, konvence nebo použitá verze softwaru |
|---|---|
| Systém | Red Hat Enterprise Linux 8 |
| Software | Apache Spark 2.4.0 |
| Jiné | Privilegovaný přístup k vašemu systému Linux jako root nebo prostřednictvím sudo příkaz. |
| Konvence | # – vyžaduje, aby dané linuxové příkazy byly spouštěny s právy root buď přímo jako uživatel root, nebo pomocí sudo příkaz$ – vyžaduje, aby dané linuxové příkazy byly spouštěny jako běžný neprivilegovaný uživatel |
Jak nainstalovat spark na Redhat 8 krok za krokem
Apache Spark běží na JVM (Java Virtual Machine), takže ke spuštění aplikací je vyžadována funkční instalace Java 8. Kromě toho je v balení dodáváno několik skořápek, jedna z nich je pyspark , shell založený na pythonu. Abyste s tím mohli pracovat, budete také potřebovat nainstalovaný a nastavený python 2.
- Chceme-li získat adresu URL nejnovějšího balíčku Spark, musíme navštívit web pro stahování Spark. Musíme vybrat zrcadlo, které je nejblíže našemu umístění, a zkopírovat adresu URL poskytnutou webem pro stahování. To také znamená, že vaše adresa URL se může lišit od níže uvedeného příkladu. Balíček nainstalujeme pod
/opt/, takže adresář zadáme jakoroot:# cd /opt
A vložte získanou adresu URL do
wgetzískat balíček:# wget https://www-eu.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
- Rozbalíme tarball:
# tar -xvf spark-2.4.0-bin-hadoop2.7.tgz
- A v následujících krocích vytvořte symbolický odkaz, abyste si naše cesty lépe zapamatovali:
# ln -s /opt/spark-2.4.0-bin-hadoop2.7 /opt/spark
- Vytváříme neprivilegovaného uživatele, který bude spouštět obě aplikace, hlavní i podřízenou:
# useradd spark
A nastavte jej jako vlastníka celého
/opt/sparkadresář, rekurzivně:# chown -R spark:spark /opt/spark*
- Vytváříme
systemdsoubor jednotky/etc/systemd/system/spark-master.servicepro hlavní službu s následujícím obsahem:[Unit] Description=Apache Spark Master After=network.target [Service] Type=forking User=spark Group=spark ExecStart=/opt/spark/sbin/start-master.sh ExecStop=/opt/spark/sbin/stop-master.sh [Install] WantedBy=multi-user.targetA také jeden pro podřízenou službu, která bude
/etc/systemd/system/spark-slave.service.services níže uvedeným obsahem:[Unit] Description=Apache Spark Slave After=network.target [Service] Type=forking User=spark Group=spark ExecStart=/opt/spark/sbin/start-slave.sh spark://rhel8lab.linuxconfig.org:7077 ExecStop=/opt/spark/sbin/stop-slave.sh [Install] WantedBy=multi-user.targetVšimněte si zvýrazněné adresy URL. Toto je vytvořeno pomocí
spark://<hostname-or-ip-address-of-the-master>:7077, v tomto případě má laboratorní stroj, který poběží master, název hostitelerhel8lab.linuxconfig.org. Jméno vašeho pána bude jiné. Každý slave musí být schopen přeložit tento název hostitele a dostat se k master na zadaném portu, což je port7077ve výchozím nastavení. - Když máme soubory služeb na svém místě, musíme se zeptat
systemdpro opětovné přečtení:# systemctl daemon-reload
- Můžeme spustit náš Spark master pomocí
systemd:# systemctl start spark-master.service
- Pro ověření, že náš master běží a je funkční, můžeme použít systemd status:
# systemctl status spark-master.service spark-master.service - Apache Spark Master Loaded: loaded (/etc/systemd/system/spark-master.service; disabled; vendor preset: disabled) Active: active (running) since Fri 2019-01-11 16:30:03 CET; 53min ago Process: 3308 ExecStop=/opt/spark/sbin/stop-master.sh (code=exited, status=0/SUCCESS) Process: 3339 ExecStart=/opt/spark/sbin/start-master.sh (code=exited, status=0/SUCCESS) Main PID: 3359 (java) Tasks: 27 (limit: 12544) Memory: 219.3M CGroup: /system.slice/spark-master.service 3359 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181.b13-9.el8.x86_64/jre/bin/java -cp /opt/spark/conf/:/opt/spark/jars/* -Xmx1g org.apache.spark.deploy.master.Master --host [...] Jan 11 16:30:00 rhel8lab.linuxconfig.org systemd[1]: Starting Apache Spark Master... Jan 11 16:30:00 rhel8lab.linuxconfig.org start-master.sh[3339]: starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-spark-org.apache.spark.deploy.master.Master-1[...]Poslední řádek také označuje hlavní soubor protokolu master, který je v
logsadresář v základním adresáři Spark,/opt/sparkv našem případě. Když se podíváme do tohoto souboru, měli bychom na konci vidět řádek podobný níže uvedenému příkladu:2019-01-11 14:45:28 INFO Master:54 - I have been elected leader! New state: ALIVE
Měli bychom také najít řádek, který nám říká, kde hlavní rozhraní naslouchá:
2019-01-11 16:30:03 INFO Utils:54 - Successfully started service 'MasterUI' on port 8080
Pokud nasměrujeme prohlížeč na port hostitelského počítače
8080, měli bychom vidět stavovou stránku hlavního serveru, v tuto chvíli nejsou připojeni žádní pracovníci.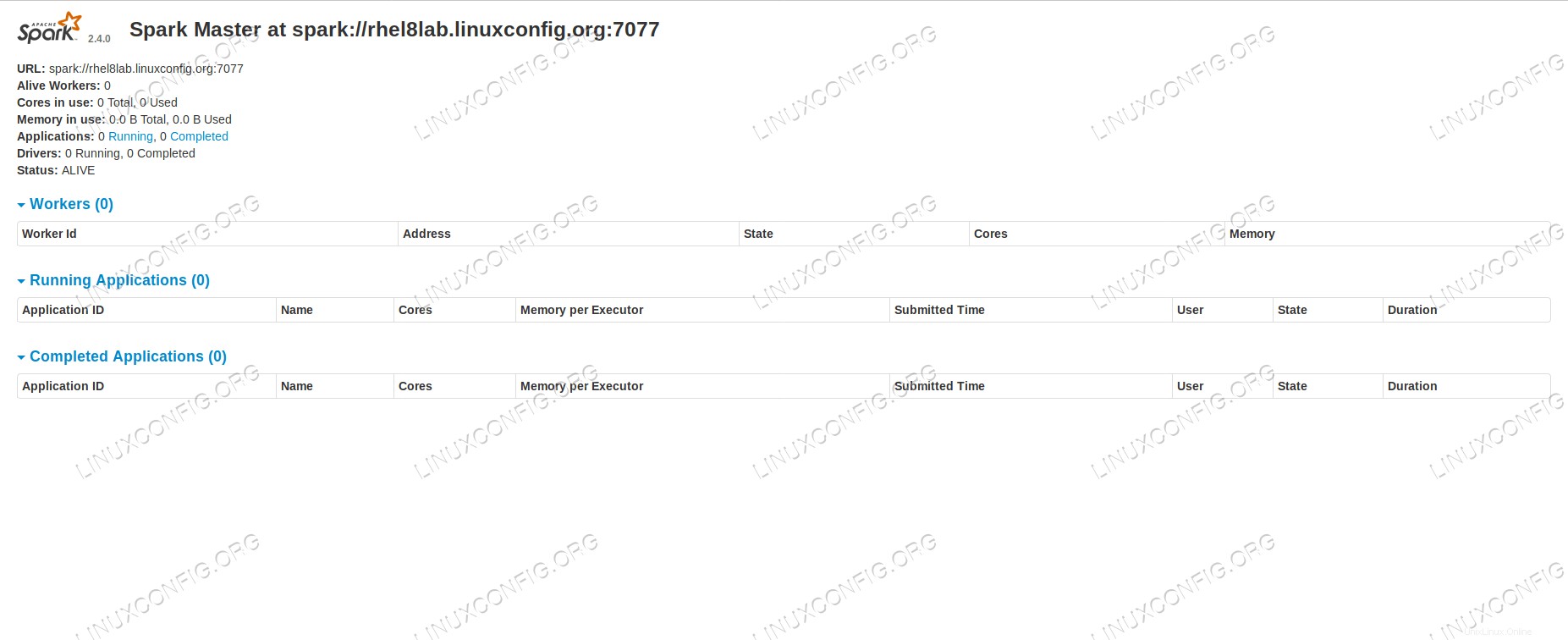 Stránka s hlavním stavem Sparku bez připojených pracovníků.
Stránka s hlavním stavem Sparku bez připojených pracovníků. Všimněte si řádku URL na stavové stránce Spark master. Toto je stejná adresa URL, kterou musíme použít pro každý soubor podřízených jednotek, který jsme vytvořili v
step 5.
Pokud se v prohlížeči zobrazí chybová zpráva „připojení odmítnuto“, pravděpodobně budeme muset otevřít port na bráně firewall:# firewall-cmd --zone=public --add-port=8080/tcp --permanent success # firewall-cmd --reload success
- Náš pán běží, připojíme k němu otroka. Spustíme podřízenou službu:
# systemctl start spark-slave.service
- Můžeme ověřit, že náš slave běží pomocí systemd:
# systemctl status spark-slave.service spark-slave.service - Apache Spark Slave Loaded: loaded (/etc/systemd/system/spark-slave.service; disabled; vendor preset: disabled) Active: active (running) since Fri 2019-01-11 16:31:41 CET; 1h 3min ago Process: 3515 ExecStop=/opt/spark/sbin/stop-slave.sh (code=exited, status=0/SUCCESS) Process: 3537 ExecStart=/opt/spark/sbin/start-slave.sh spark://rhel8lab.linuxconfig.org:7077 (code=exited, status=0/SUCCESS) Main PID: 3554 (java) Tasks: 26 (limit: 12544) Memory: 176.1M CGroup: /system.slice/spark-slave.service 3554 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181.b13-9.el8.x86_64/jre/bin/java -cp /opt/spark/conf/:/opt/spark/jars/* -Xmx1g org.apache.spark.deploy.worker.Worker [...] Jan 11 16:31:39 rhel8lab.linuxconfig.org systemd[1]: Starting Apache Spark Slave... Jan 11 16:31:39 rhel8lab.linuxconfig.org start-slave.sh[3537]: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-spar[...]Tento výstup také poskytuje cestu k souboru protokolu slave (nebo pracovníka), který bude ve stejném adresáři s „pracovníkem“ ve svém názvu. Kontrolou tohoto souboru bychom měli vidět něco podobného níže uvedenému výstupu:
2019-01-11 14:52:23 INFO Worker:54 - Connecting to master rhel8lab.linuxconfig.org:7077... 2019-01-11 14:52:23 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@62059f4a{/metrics/json,null,AVAILABLE,@Spark} 2019-01-11 14:52:23 INFO TransportClientFactory:267 - Successfully created connection to rhel8lab.linuxconfig.org/10.0.2.15:7077 after 58 ms (0 ms spent in bootstraps) 2019-01-11 14:52:24 INFO Worker:54 - Successfully registered with master spark://rhel8lab.linuxconfig.org:7077To znamená, že pracovník je úspěšně připojen k hlavnímu zařízení. Ve stejném souboru protokolu najdeme řádek, který nám říká adresu URL, na které pracovník poslouchá:
2019-01-11 14:52:23 INFO WorkerWebUI:54 - Bound WorkerWebUI to 0.0.0.0, and started at http://rhel8lab.linuxconfig.org:8081
Náš prohlížeč můžeme nasměrovat na stránku stavu pracovníka, kde je uveden její hlavní server.
 Stránka stavu pracovníka Spark, připojená k hlavnímu serveru.
Stránka stavu pracovníka Spark, připojená k hlavnímu serveru. V souboru protokolu hlavního serveru by se měl objevit ověřovací řádek:
2019-01-11 14:52:24 INFO Master:54 - Registering worker 10.0.2.15:40815 with 2 cores, 1024.0 MB RAM
Pokud nyní znovu načteme stavovou stránku předlohy, měl by se tam objevit také pracovník s odkazem na její stavovou stránku.
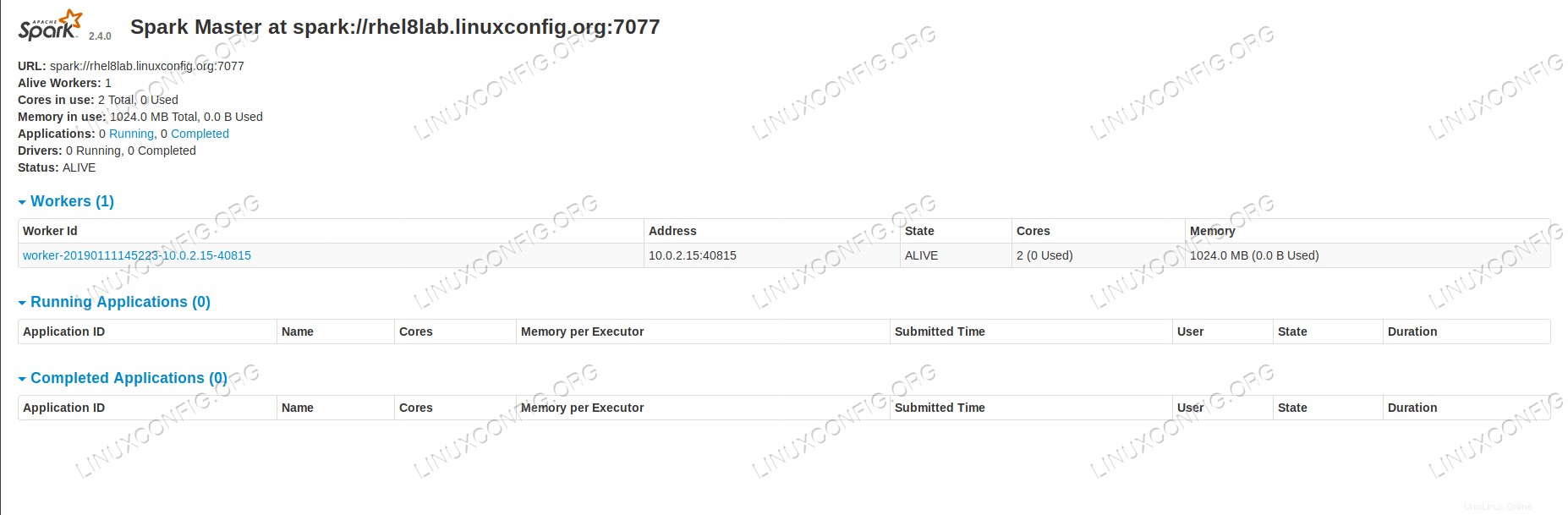 Stránka s hlavním stavem Spark s jedním připojeným pracovníkem.
Stránka s hlavním stavem Spark s jedním připojeným pracovníkem. Tyto zdroje ověřují, že je náš cluster připojený a připravený k práci.
- Chceme-li na clusteru spustit jednoduchou úlohu, provedeme jeden z příkladů dodaných s balíčkem, který jsme si stáhli. Zvažte následující jednoduchý textový soubor
/opt/spark/test.file:line1 word1 word2 word3 line2 word1 line3 word1 word2 word3 word4Spustíme
wordcount.pypříklad na něm, který bude počítat výskyt každého slova v souboru. Můžeme použítsparkuživatel, žádnýrootpotřebná oprávnění.$ /opt/spark/bin/spark-submit /opt/spark/examples/src/main/python/wordcount.py /opt/spark/test.file 2019-01-11 15:56:57 INFO SparkContext:54 - Submitted application: PythonWordCount 2019-01-11 15:56:57 INFO SecurityManager:54 - Changing view acls to: spark 2019-01-11 15:56:57 INFO SecurityManager:54 - Changing modify acls to: spark [...]
Při provádění úlohy je poskytován dlouhý výstup. Na konci výstupu se zobrazí výsledek, shluk vypočítá potřebné informace:
2019-01-11 15:57:05 INFO DAGScheduler:54 - Job 0 finished: collect at /opt/spark/examples/src/main/python/wordcount.py:40, took 1.619928 s line3: 1 line2: 1 line1: 1 word4: 1 word1: 3 word3: 2 word2: 2 [...]
Díky tomu jsme viděli náš Apache Spark v akci. Lze nainstalovat a připojit další podřízené uzly, aby se škáloval výpočetní výkon našeho clusteru.