Pokud jste uživatelem příkazového řádku Linuxu a vaše práce zahrnuje hraní si s textovými soubory, měli byste vědět (pokud ještě ne), že existuje mnoho nástrojů příkazového řádku, které vám mohou být v různých situacích velmi nápomocné. Například existuje nástroj nazvaný 'uniq', který hlásí nebo dokonce odstraňuje opakované řádky v souboru.
V tomto článku budeme diskutovat o „uniq“ prostřednictvím snadno srozumitelných příkladů. Ale než to uděláme, stojí za zmínku, že všechny příklady a pokyny uvedené v tomto tutoriálu byly testovány na Ubuntu 16.04LTS.
Příkaz Linux Uniq
Jak již bylo zmíněno na začátku, příkaz uniq hlásí nebo vynechává opakované řádky. Zde je obecná syntaxe tohoto příkazu:
uniq [MOŽNOST]... [VSTUP [VÝSTUP]]
Podle manuálové stránky obslužného programu:"Filtrování sousedních odpovídajících řádků z INPUT (nebo standardního vstupu), zápis do OUTPUT (nebo standardního výstupu). Bez možnosti jsou odpovídající řádky sloučeny do prvního výskytu."
Následuje několik příkladů, které vám pomohou nástroj lépe pochopit.
1. Jak odstranit opakované řádky pomocí příkazu uniq
Předpokládejme, že soubor obsahuje následující řádky:
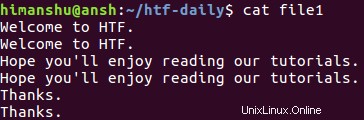
Je zřejmé, že každý řádek se opakuje. Nyní spustíme Uniq na tomto souboru a uvidíme, co se stane.
uniq file1

Jak tedy vidíte, výstup vytvořený příkazem neobsahuje žádné opakované řádky. Upozorňujeme, že původní soubor - v našem případě 'file1' - zůstává nedotčen. Výstup nástroje můžete přesměrovat do jiného souboru pro případ, že jej chcete uložit a pracovat na něm.
2. Jak zobrazit počet opakování pro každý řádek
Pokud chcete, můžete také nastavit jedinečné zobrazení počtu opakování řádku na výstupu. To lze provést pomocí -c možnost příkazového řádku. Například následující příkaz:
uniq -c file1
vytvoří následující výstup:

Jak tedy vidíte, počet opakování pro každý řádek je ve výstupu uveden před ním.
3. Jak tisknout pouze duplicitní řádky pomocí uniq
Chcete-li, aby uniq tiskl pouze duplicitní řádky, použijte -D možnost příkazového řádku. Předpokládejme například, že soubor1 nyní obsahuje další řádek ve spodní části (všimněte si, že tento řádek se neopakuje).
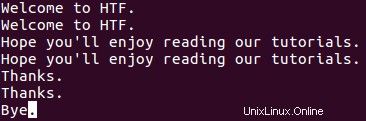
Nyní, když spustím následující příkaz:
uniq -D file1
Vytvoří se následující výstup:
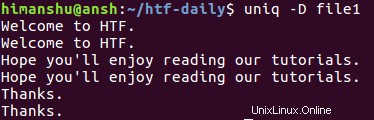
Jak můžete vidět, volba -D umožňuje uniq zobrazit všechny opakující se řádky ve výstupu, včetně všech jejich opakování. Pro lepší oddělení můžete mít po každé skupině opakovaných řádků prázdný řádek, což lze provést pomocí --all-repeated možnost.
uniq --all-repeated[=METODA] soubor1
Tato možnost vyžaduje zadání názvu metody uživatelem. Hodnoty mohou být předřazeny (pro přidání prázdného řádku) nebo oddělit (pro připojení prázdného řádku). Zde je například tato možnost v akci s předřazením metoda.
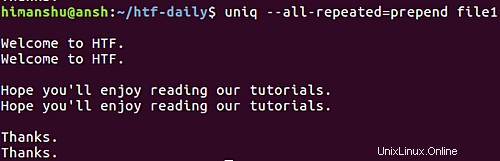
Pokud chcete, aby nástroj zobrazoval pouze jeden duplicitní řádek na skupinu, můžete přejít na -d volba. Zde je příklad:

Je zřejmé, že ve výstupu byl zobrazen pouze jeden opakovaný řádek z každé skupiny.
4. Jak zajistit, aby uniq neporovnával prvních několik polí
Někdy, v závislosti na situaci, je podobnost dvou čar definována malou částí těchto čar. Zvažte například obsah následujícího souboru:
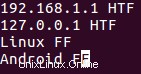
Nyní předpokládejme, že řádky jsou považovány za podobné nebo odlišné na základě jejich druhého pole (HTF nebo FF) a chcete to sdělit uniq, pak to lze provést pomocí -f možnost příkazového řádku.
uniq -f [number-of-fields-to-skip] [file-name]
Volba -f vyžaduje, abyste předali číslo, které představuje počet polí, která chcete příkazem přeskočit. V našem případě můžeme například předat '1' jako argument parametru -f, protože je to pouze první pole, které chceme, aby uniq přeskočilo.
uniq -f 1 file1

Výstup jasně ukazuje, že uniq považoval první i třetí řádek za opakované na základě jejich příslušných druhých polí.
5. Jak docílit toho, aby uniq zobrazoval všechny řádky a zároveň odděloval opakující se skupiny prázdným řádkem
V případě, že je požadavkem zobrazit všechny řádky a zároveň oddělit opakující se skupiny řádků prázdným řádkem, můžete použít --group volba. Stejně jako --všechno-opakované možnost, o které jsme hovořili dříve, --group také vyžaduje, abyste sdělili pozici prázdného řádku (prepend , připojit nebo obě ).
Zde je příklad:
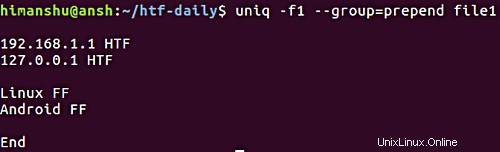
Všimněte si, že možnost -f jsme již probrali v předchozí části.
6. Jak zajistit, aby uniq tiskl pouze neopakující se řádky
Jak jste již pochopili, příkaz uniq standardně zobrazuje ve výstupu pouze opakované řádky. Ale pokud chcete, můžete místo toho zobrazit pouze neopakované nebo jedinečné řádky. To lze provést pomocí -u možnost příkazového řádku.
uniq -u [file-name]
Takže v našem případě:
uniq -u soubor1
Zde je příklad:

Všimněte si, že možnost -f jsme již probrali v sekci/bodu číslo 4.
7. Jak zajistit, aby se uniq vyhnul porovnávání nastaveného počtu počátečních znaků
V jednom z našich dřívějších příkladů jsme diskutovali o tom, jak můžete vytvořit uniq přeskočení polí. Pokud však chcete, můžete nástroj donutit, aby také vynechal nastavený počet počátečních znaků. K této funkci lze přistupovat pomocí -s možnost příkazového řádku.
uniq -s [počet-znaků] název_souboru
Předpokládejme například, že soubor obsahuje následující řádky:
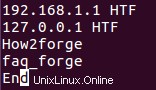
Pokud nyní chcete, aby uniq před porovnáním vynechal první 4 znaky v každém řádku, můžete to provést následujícím způsobem:
uniq -s 4 soubor1
Zde je výše uvedený příkaz v akci:
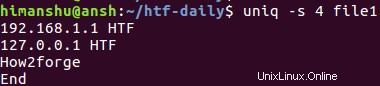
Můžete tedy vidět, že čtvrtý řádek (faq_forge), který tam původně byl, byl ve výstupu přeskočen. Důvodem je to, že po přeskočení prvních čtyř znaků byly třetí a čtvrtý řádek stejné, a proto je uniq považuje za opakované.
8. Jak omezit porovnání na nastavený počet znaků
Podobně jako přeskakujete znaky, můžete také požádat uniq, aby omezil srovnání na stanovený počet znaků. K tomu budete muset použít -w možnost příkazového řádku.
uniq -w [počet-znaků] [název-souboru]
Předpokládejme například, že soubor obsahuje následující řádky:

Pokud je nyní požadavkem omezit srovnání na první 3 znaky, lze to provést následujícím způsobem:
uniq -w 3 soubor1
Zde je výše uvedený příkaz v akci:
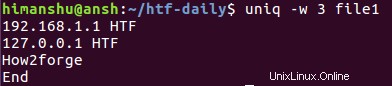
Vzhledem k tomu, že první 3 znaky třetího a čtvrtého řádku jsou stejné, byly tyto řádky považovány za opakované. Ve výstupu se tedy zobrazí pouze třetí.
9. Jak zajistit, aby uniq porovnání nerozlišovalo malá a velká písmena
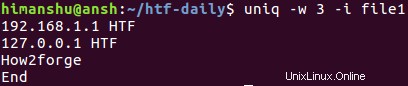
Ve výchozím nastavení se při porovnání, které provádí uniq, rozlišují velká a malá písmena. V procesu však můžete rozlišovat malá a velká písmena pomocí -i možnost příkazového řádku.
Uvažujme například stejný případ, o kterém jsme hovořili v předchozí části, jen čtvrtý řádek začíná velkými H, O a W.
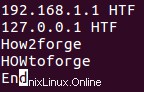
Nyní, pokud zkusíte spustit stejný příkaz, jaký jsme použili v předchozí části, uvidíte, že výstup je jiný:

Je to proto, že první tři znaky třetího a čtvrtého řádku se pro uniq liší velikostí písmen. V situacích, kde jsou tyto řádky, můžete provést porovnání tak, že nebude rozlišovat malá a velká písmena pomocí volby příkazového řádku -i.
10. Jak zajistit, aby výstup uniq byl ukončen NUL
Ve výchozím nastavení je výstup uniq ukončen novým řádkem. Pokud však chcete, můžete mít místo toho výstup ukončený NUL (užitečné při práci s uniq ve skriptech). To lze provést pomocí -z možnost příkazového řádku.
uniq -z [název-souboru]
Závěr
Pokryli jsme téměř všechny možnosti příkazového řádku, které příkaz uniq nabízí, takže si procvičte vše, co jsme zde probrali, a měli byste získat solidní představu o tom, jak uniq funguje a jaké funkce poskytuje. Jako vždy si v případě jakéhokoli dotazu nebo pochybností nejprve projděte manuálovou stránku příkazu.