Hodnoty oddělené čárkami neboli CSV je polostrukturovaná data, která jako oddělovač k oddělení slov používá čárku. Formáty souborů CSV jsou mezi datovými profesionály velmi oblíbené, protože se musí vypořádat s mnoha soubory CSV a zpracovávat je, aby vytvořili přehled. V tomto článku se zaměříme na to, jak analyzovat soubory CSV ve skriptech shellu Bash v Linuxu.
Ve většině částí tohoto článku budu používat awk a sed nástroje pro analýzu csv namísto kombinování různých příkazů, jako je grep , cut , tr , atd.
awk obslužný program snižuje složitost propojování více příkazů nebo psaní smyčky s logikou pro zachycení dat. Místo toho můžete napsat jednořádkový kód v awk dělat tu práci.
1. Příprava souboru CSV pro zpracování
Váš soubor CSV může být vygenerován z databáze, rozhraní API nebo jste možná spustili nějaké příkazy a převedli výstup na oddělovač ve formátu CSV. V každém z případů musíte nejprve analyzovat datovou sadu, než nad ní spustíte svou logiku.
Nejlepším postupem je vyčistit datovou sadu před jejím použitím. Proč bychom měli čistit datovou sadu? Mohou nastat situace, kdy budou prázdné hodnoty buněk nebo žádné správné formátování v záhlaví, další sloupce, které nejsou nutné pro zpracování, a mnoho dalších.
Používám níže uvedená data CSV, která jsem získal z Kaggle pro demonstrační účely.
Player_Id,Player_Name,DOB,Batting_Hand,Bowling_Skill,Country 1,SC Ganguly,8-Jul-72,Left_Hand,Right-arm medium, 2,BB McCullum,27-Sep-81,Right_Hand,Right-arm medium, 3,RT Ponting,19-Dec-74,Right_Hand,Right-arm medium, 4,DJ Hussey,15-Jul-77,Right_Hand,Right-arm offbreak,Australia 5,Mohammad Hafeez,17-Oct-80,,Right-arm offbreak,Pakistan 6,R Dravid,11-Jan-73,,Right-arm offbreak,India 7,W Jaffer,16-Feb-78,,Right-arm offbreak,India 8,V Kohli,5-Nov-88,,Right-arm medium,India 9,JH Kallis,16-Oct-75,,Right-arm fast-medium,South Africa 10,CL White,18-Aug-83,Right_Hand,Legbreak googly,Australia 11,MV Boucher,3-Dec-76,Right_Hand,Right-arm medium,South Africa 12,B Akhil,7-Oct-77,Right_Hand,Right-arm medium-fast,India 13,AA Noffke,30-Apr-77,Right_Hand,Right-arm fast-medium,Australia 14,P Kumar,2-Oct-86,Right_Hand,Right-arm medium,India 15,Z Khan,7-Oct-78,Right_Hand,Left-arm fast-medium,India
1.1. Nahradit prázdné buňky
V některých případech nebude mít soubor CSV v konkrétních buňkách žádné hodnoty. Podívejte se na níže uvedený snímek obrazovky, kde jsou mezi sloupci nějaké prázdné buňky.
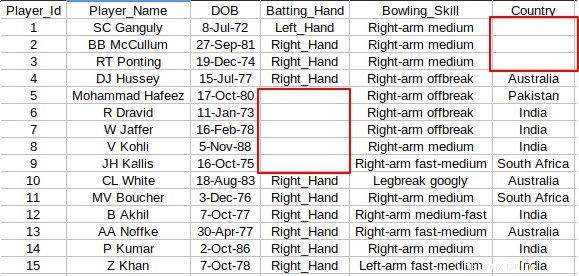
Vždy bych to nahradil "NA" nebo "No Value", takže nebudou žádné prázdné buňky. Můžete použít následující awk úryvek, kterým nahradíte libovolnou prázdnou buňku požadovanou hodnotou. V tomto případě nahrazuji prázdné buňky "Žádná hodnota".
awk 'BEGIN{FS=",";OFS=","}
{
for(i=1;i<=NF;i++)
{
if($i == ""){
$i="No Value"
}
}
print
}' ~/Downloads/Player.csv > player_cleaned.csv
Tento fragment funguje tak, že nastavuji oddělovač polí a oddělovač výstupních polí na čárku (FS=",";OFS="," ). Pomocí for loop , iterujte každou buňku v řádku, a pokud je buňka nalezena prázdná ($i == "" ) pak jej nahraďte "No value" ($i="No value" ). Změny musíte přesměrovat do nového souboru.
Doporučené čtení:
- Přesměrování Bash vysvětleno na příkladech
1.2. Velká písmena v záhlaví
Soubory CSV mohou nebo nemusí mít záhlaví. Ale pokud tam je záhlaví, vždy bych ho psal velkým písmenem pro lepší čitelnost. Můžete to udělat snadno pomocí awk nebo sed . Ukážu vám oba způsoby.
awk 'BEGIN{FS=",";OFS=","}
{
if(NR==1){
print toupper($0)
} else {
print
}
}' player.csv > player_cleaned.csv
Zde kontrolujeme, zda je řádek prvního řádku pomocí (NR==1 ) a pomocí toupper() funkce pro velké písmeno. Stejný úryvek lze napsat jako jeden řádek.
awk 'NR==1{ print toupper($0) }NR>1' player.csv > player_cleaned.csv
Pomocí awk , musíte změny znovu přesměrovat do nového souboru. Místo toho můžete použít 'sed ' pro úpravu změn přímo do souboru. Zde \U převede velká písmena na velká. Pokud chcete provést převod malých písmen, použijte \L .
$ sed -i -e '1 s/(.*)/\U\1/' player_cleaned.csv
$ cat player_cleaned.csv
1.3. Odebrat koncovou čárku
Váš soubor CSV může mít na konci čárku. Chcete-li vyčistit koncové čárky, můžete postupovat podle níže uvedené metody.
Záměrně jsem přidal koncovou čárku z řádků 7 do 11 v mém datovém souboru.
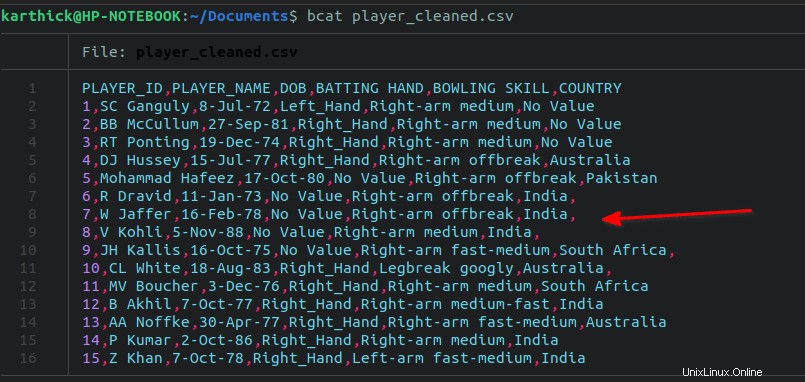
Chcete-li odstranit všechny koncové čárky, spusťte následující sed příkaz:
$ sed -i 's/,$//' ~/Documents/player_cleaned.csv
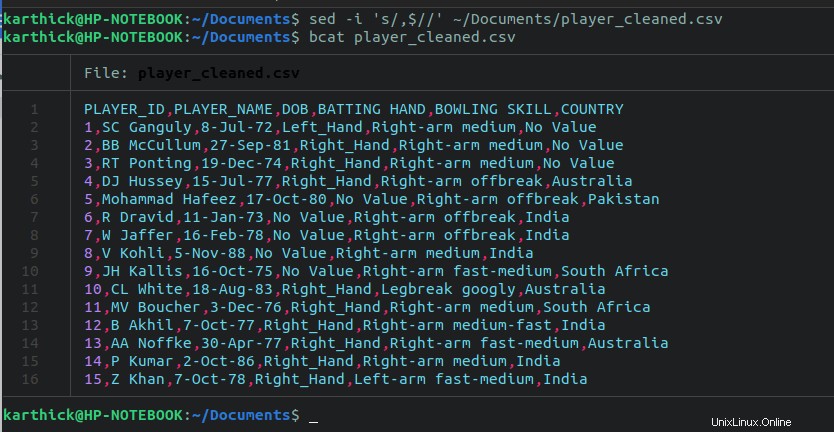
Nyní máme hotovou část čištění. Možná budete muset provést několik dalších kroků, ale to závisí na tom, jak je váš soubor CSV strukturován a co je třeba vyčistit.
2. Pretty Print CSV soubor v terminálu
Pokud se pokoušíte zobrazit soubory CSV v terminálu, existuje několik možností, jak si soubor vytisknout v tabulkovém formátu, který vám poskytne lepší čitelnost.
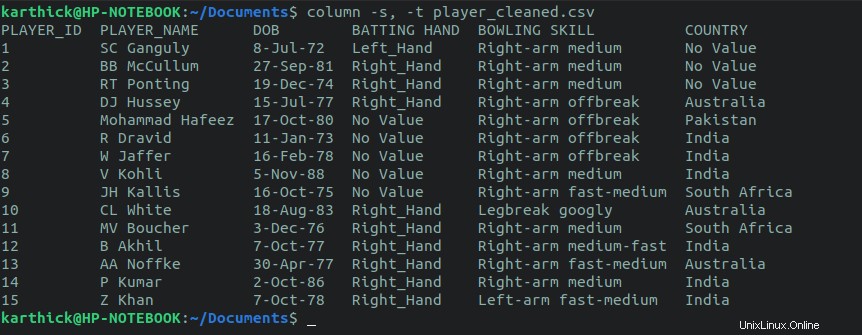
2.1. Příkaz sloupce
Prvním přístupem je použití column příkaz. Příkaz Column přijímá oddělovač, který je nastaven na čárku, a oddělovač pro rozdělení sloupce, který je v níže uvedeném příkazu nastaven na tabulátor. Můžete si také nastavit vlastní oddělovače.
$ cat player_cleaned.csv | column -s, -t $ column -s, -t player_cleaned.csv
2.2. Příkaz CSV Look
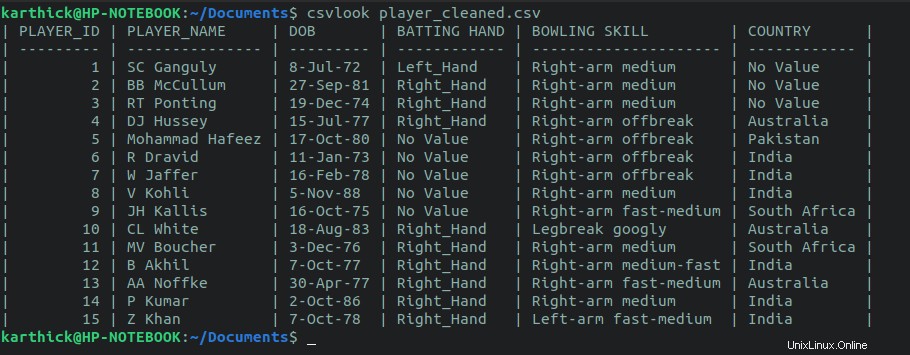
Csvlook je nástroj, který je součástí balíčku csvkit. Není třeba nastavovat oddělovač, jako jsme to udělali u column příkaz.
$ cat player_cleaned.csv | csvlook
$ csvlook player_cleaned.csv
2.3. Python Pretty Table
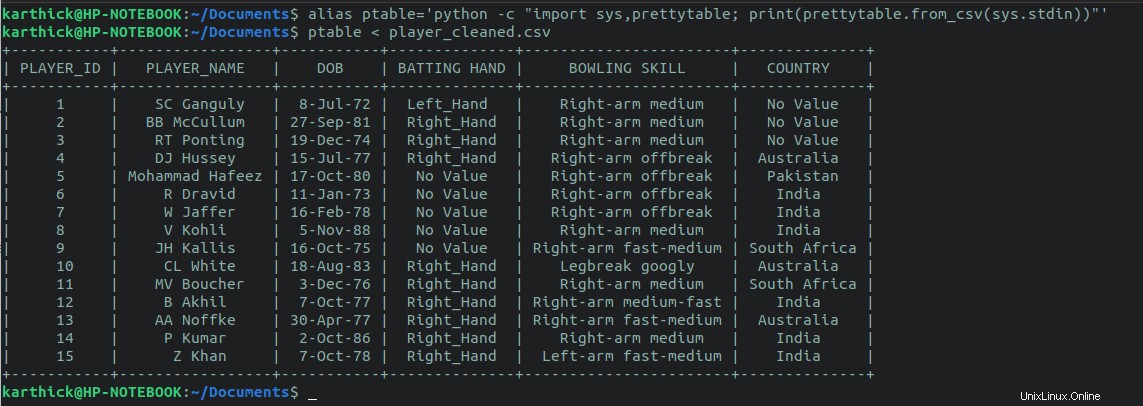
Pokud máte python prettytable nainstalovaný modul, pak můžete spustit následující jednořádkový řádek a přesměrovat soubor CSV, abyste vygenerovali tabulku.
python -c "import sys,prettytable; print(prettytable.from_csv(sys.stdin))" < player_cleaned.csv
Můžete také vytvořit alias pro jednořádkovou a předejte název souboru jako argument.
$ alias ptable='python -c "import sys,prettytable; print(prettytable.from_csv(sys.stdin))"'
$ ptable < player_cleaned.csv
3. Získávání dat ze souboru CSV
3.1. Tisk počtu řádků a sloupců
Chcete-li získat počet sloupců v souboru CSV, spusťte následující příkaz. Zde proměnná NF představuje počet polí rozdělených čárkou jako oddělovačem.
$ awk -F, 'END{print NF}' player_cleaned.csv
6
Chcete-li získat počet řádků, spusťte následující příkaz. Zde proměnná NR představuje aktuální záznam (tj. každý řádek je považován za jeden záznam.
$ awk -F, 'END{print NR}' player_cleaned.csv
16 Chcete-li přeskočit první řádek (záhlaví) a vypočítat počet řádků, spusťte následující příkaz.
$ awk -F, 'END{print NR-1}' player_cleaned.csv
15 3.2. Vytisknout celý soubor CSV
To je docela jednoduché. Můžete použít cat nebo awk vytisknout celý soubor CSV.
$ cat player_cleaned.csv
$ awk '{print}' player_cleaned.csv 3.3. Tisknout pouze záhlaví ze souboru CSV
Samotný tisk záhlaví vám poskytne pěkný přehled o tom, jaký typ dat váš soubor CSV obsahuje. Můžete použít head nebo awk příkaz k uchopení samotné hlavičky.
$ head -n 1 player_cleaned.csv
$ awk 'NR==1' player_cleaned.csv PLAYER_ID,PLAYER_NAME,DOB,BATTING HAND,BOWLING SKILL,COUNTRY
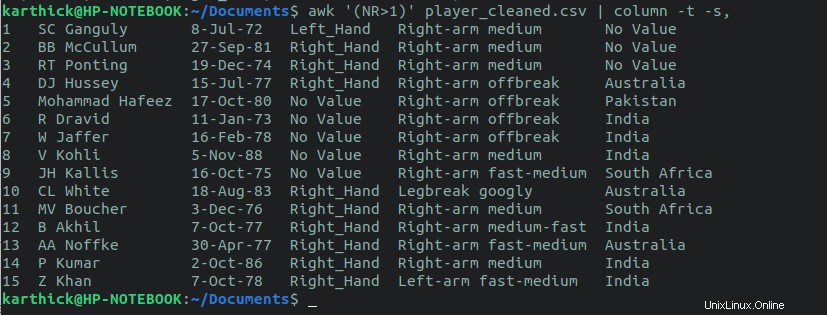
3.4. Vyloučit řádek záhlaví
Chcete-li vyloučit řádek záhlaví a vytisknout všechny ostatní řádky, použijte awk příkaz. Proměnná awk NR > 1 vytvoří první řádek, který bude přeskočen.
$ awk '(NR>1)' player_cleansed.csv
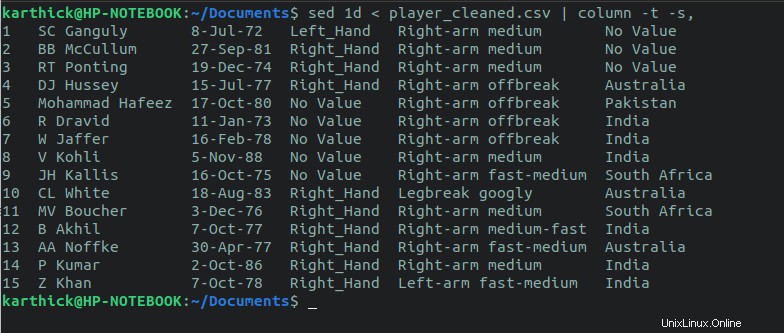
Sed lze také použít k vyloučení prvního řádku a tisku všech ostatních řádků. 1d flag vymaže první řádek a vytiskne všechny ostatní řádky na stdout (Terminál).
$ sed 1d < player_cleaned.csv
3.5. Tisk konkrétních sloupců
Pro tisk celého sloupce můžeme použít pozici sloupce. Existují dva přístupy, jak toho dosáhnout. Prvním přístupem bude použití awk a druhým přístupem bude použití smyček . Awk bude mnohem jednodušší uchopit sloupec.
Awk ve výchozím nastavení rozdělí řádek na základě oddělovače a uloží hodnoty do $1 , $2 , $3 atd. Výchozí oddělovač pro awk je bílé místo .
Podívejte se na níže uvedený úryvek, kde je oddělovač polí (FS="," ) a oddělovač výstupních polí (OFS="," ) je nastaven na čárku. Příkaz print vytiskne první sloupec, druhý sloupec a šestý sloupec.
awk 'BEGIN{FS=",";OFS=","}
{
print $1,$2,$6
}' player_cleansed.csv Výše uvedený úryvek můžete napsat také na jeden řádek.
awk 'BEGIN{FS=",";OFS=","}{print $1,$2,$6}' player_cleansed.csv 
Nyní by druhým přístupem bylo použití smyček.
IFS=","
while read -r -a fields
do
echo ${fields[0]},${fields[1]},${fields[5]}
done < player_cleaned.csv Dovolte mi vysvětlit, co se přesně stane, když spustíte výše uvedený fragment.
- Interní oddělovač polí IFS nastavujeme na čárku.
- Pomocí příkazu read vytváříme pole s názvem "fields" a přesměrováváme vstupní soubor do
while loop. - Pro každou iteraci bude číst řádek po řádku a řádek uloží jako prvky pole v "polích", takže můžete použít pozici indexu pole k zachycení konkrétního sloupce samostatně.
Poznámka: Hodnota indexu začíná od 0..N
3.6. Vytisknout řádek, který odpovídá podmínce
Pokud chcete vytisknout řádky, které odpovídají určité podmínce, můžete to udělat snadno pomocí awk . Pojďme si projít několik scénářů.
Chcete-li vytisknout všechny řádky, které odpovídají hodnotě ve sloupci, spusťte následující příkaz. Zde se snažím vytisknout všechny řádky, které odpovídají hodnotě „Indie“ ve sloupci 6.
$ awk -F , '$6 == "India"' player_cleaned.csv

Chcete-li vytisknout všechny řádky, které neodpovídají určité hodnotě, spusťte následující příkaz. Místo operátoru rovnosti , používáme nerovný operátor .
$ awk -F , '$6 != "India"' player_cleaned.csv
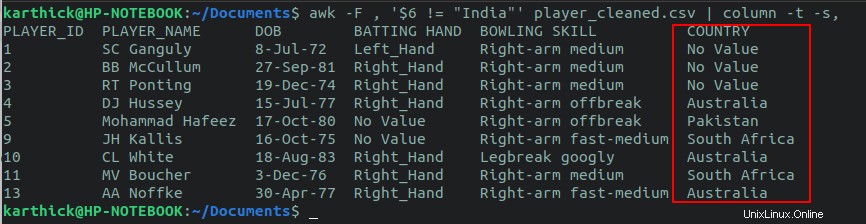
Můžete také provést kontrolu stavu na více než jednom sloupci pomocí logického AND, logického operátoru OR. Řekněme, že chci zkontrolovat všechny řádky, které mají zemi jako „Indie“ a odpalující ruku jako „Pravá_ruka“.
Zde $4 ukazuje na 4. sloupec a $6 ukazuje na 6. sloupec. Symbol && se používá jako logický operátor AND k vyhodnocení dvou podmínek.
$ awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv

Pokud si přejete zahrnout záhlaví spolu s výsledkem z podmíněné kontroly, použijte následující příkaz. Nejprve vytisknu první řádek pomocí NR==1 a poté pomocí logického operátoru AND spuštěním podmíněné kontroly vytiskněte výsledky.
$ awk 'NR==1' player_cleaned.csv && awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv
Pokud si přejete vytisknout nebo přesměrovat výstup, spusťte celý příkaz uvnitř subshell tak, že jej uzavřete do závorek .
$ (awk 'NR==1' player_cleaned.csv && awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv) | column -t -s,

Poznámka k Csvkit
To, co jsme zatím viděli v tomto článku, je jednoduché a přímočaré. Ale když má váš soubor CSV složitou strukturu, stává se zdlouhavé analyzovat pomocí výše uvedeného přístupu. Existuje nástroj s názvem CSVKIT , což je vynikající nástroj pro práci se soubory CSV v bash.
Problém s nástrojem csvkit je ten, že je ve vaší distribuci nainstalován ve výchozím nastavení a možná jej budete muset nainstalovat ručně. Ve vašem podnikovém prostředí to nemusí být možné, protože mohou existovat určitá omezení pro instalaci externích balíčků. Tato utilita ale stojí za zmínku a vytvoříme pro ni samostatný podrobný článek.
Závěr
V této příručce jsme viděli, jak pracovat se soubory CSV pomocí awk, sed. K dosažení požadovaného výsledku můžete použít i další nástroje jako cut, grep, tr atd., ale awk a sed vám zjednoduší život a sníží složitost psaní mnoha kódů. Pokud máte nějakou zpětnou vazbu, uveďte ji v sekci komentářů a my ji rádi uslyšíme.
Podobné čtení:
- Skriptování Bash – Analýza argumentů ve skriptech Bash pomocí getopts
- Jak analyzovat a pěkně tisknout JSON pomocí nástrojů příkazového řádku Linux