Příkaz cut se používá k vyříznutí částí standardního vstupního toku nebo datových souborů pomocí unixového nástroje cut. Je součástí balíku GNU Coreutils a základního systému BSD, a proto je standardně dostupný na všech systémech Linux a BSD. Příkaz cut v Unixu umožňuje řezání sekcí na základě pozic bajtů, znaků nebo polí oddělených oddělovačem, jako jsou znaky „-“ nebo „:“. Náš průvodce poskytuje praktický úvod do linuxového příkazu cut pomocí dobře uspořádané sady příkladů. Vyzkoušejte je spolu s tímto příspěvkem, abyste získali zkušenosti z první ruky.
Příklady příkazu Linux Cut v systému Unix
Naši odborníci se ze všech sil snažili, aby byla tato příručka přátelská pro nové uživatele Linuxu. Navíc bude sloužit jako praktický referenční bod pro zkušené uživatele. Doporučujeme čtenářům, aby si příkazy vyzkoušeli, když je prozkoumají. Tyto příkazy Linux Cut předvedeme pomocí standardního vstupu a referenčního souboru. Odtud můžete zkopírovat a vložit obsah souboru a vytvořit jej ve vašem systému.
Referenční soubor používaný pro účely demonstrace
Používáme textový soubor s názvem test.txt sídlící v domovském adresáři. Soubor obsahuje pět řádků nebo řádků, které všechny obsahují čtyři sloupce. Každý řádek obsahuje název země, její hlavní město, měnu a obyvatelstvo; vše odděleno oddělovací dvojtečkou. Vytvořte tento soubor ve svém systému a vyplňte jej níže uvedeným obsahem.
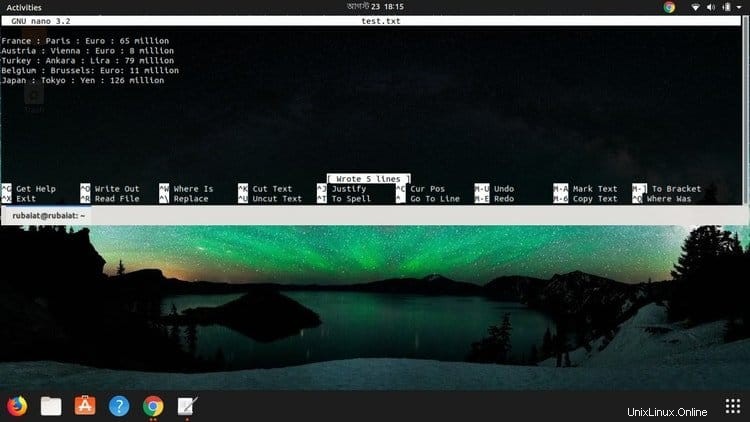
France: Paris: Euro: 65 million Austria: Vienna: Euro: 8 million Turkey: Ankara: Lira: 79 million Belgium: Brussels: Euro: 11 million Japan: Tokyo: Yen: 126 million
Syntaxe příkazu Cut v systému Unix
Linuxový příkaz cut má níže uvedenou syntaxi.
cut OPTION... [FILE]...
Možnost OPTION s zahrnují b pro (řezání na základě bajtů), f (pole), c (znak), d (oddělovač), doplňovat a –output-delimiter . SOUBOR je název souboru. Také si ukážeme, jak střih funguje se standardním vstupním streamem.
--K vyjmutí textu ze vstupního proudu použijeme příkaz echo a svislou čáru (|) jeho výstup do příkazu cut. Stejnou metodu lze použít pro poskytnutí vstupu řezu z kat.
Vyjmout text na základě pozic bajtů
Volba b poskytovaná obslužným programem cut nám umožňuje řezat části textu na základě jejich pozic bajtů. Pro tento účel musíme použít příkaz cut s parametrem -b následovaným čísly bajtů.
1. Vyjmout pouze jeden bajt ze vstupního streamu
$ echo "cutting text from input" | cut -b 1
Výše uvedený příkaz opakuje řetězec “vyjmutí textu ze vstupu“ na standardní výstup a převede jej jako vstup do příkazu cut. Příkaz cut vyřízne pouze první bajt (c ) z tohoto řetězce, protože pouze 1 byla poskytnuta s -b vlajka.
2. Vyjmout konkrétní bajty ze vstupního toku
$ echo "cutting text from input" | cut -b 1,3
Tento příkaz vyjme pouze první a třetí bajt řetězce “vyjmutí textu ze vstupu” a zobrazí se „ct “ jako jeho výstup. Vyzkoušejte to s různými pozicemi bajtů.
3. Omezte rozsah bajtů ze vstupního toku
$ echo "cutting text from input" | cut -b 1-12
Výše uvedený příkaz vyjme z daného řetězce bajtový rozsah 1-12 a vytiskne "text oříznutí" na standardním výstupu. Poskytnutí bajtových rozsahů, které jsou mimo obsazení řetězce, bude mít za následek zprávu zobrazující „cut:neplatný rozsah bajtů nebo znaků“ .
4. Vyjmout pouze jeden bajt z textového souboru
$ cut -b 1 test.txt
Tento příkaz zobrazí pouze první bajty každého z pěti řádků v souboru test.txt . Je ekvivalentní příkazu $ cat test.txt | řez -b 1
5. Vyjmout konkrétní bajty z textového souboru
$ cut -b 1,3 test.txt
Výše uvedený příkaz ořízne pouze první a třetí bajt každého řádku. Můžete zadat libovolná čísla bajtů, pokud spadají do rozsahu dostupných bajtů.
6. Vyjmout rozsah bajtů z textového souboru
$ cut -b 1-12 test.txt
Tento příkaz vypíše první až dvanáctý bajt každého řádku v test.txt soubor. Měli byste si všimnout podobnosti funkcí tohoto příkazu s 3. příkazem.
7. Vystřihněte prvních 7 bajtů v abecedním pořadí
$ cut -b 1-7 test.txt | sort
Můžeme poskytnout výstup příkazu cut jako vstup pro příkaz řazení pro abecední zobrazení prvních sedmi bajtů každého řádku. Pro abecední řazení nevyžaduje příkaz řazení žádné volby.
8. Ořízněte prvních 7 bajtů v opačném pořadí
$ cut -b 1-7 test.txt | sort -r
Tento příkaz cut vyjme prvních 7 bajtů z každého řádku a vydá je v opačném pořadí. Podívejte se, jak je výstup příkazu cut přiváděn do příkazu sort pomocí potrubí.
9. Vyjmout z pátého bajtu do konce vstupního tokuu
$ echo "cutting text from input" | cut -b 5-
Výše uvedený příkaz cut ořízne text od pátého bajtu do konce řetězce. Tento příkaz se vám bude hodit, když potřebujete řezat od zadané pozice bajtu až do konce vstupního toku. Jednoduše změňte hodnotu příznaku b a ponechte koncovou – zapnutou.
10. Vyjmout z pátého bajtu na konec souboru
$ cut -b 5- test.txt
Tento příkaz spustí řezání každého z pěti řádků test.txt od pozice pátého bajtu a končí až po skončení každého řádku. Koncová pomlčka (-) je pro tuto operaci povinná.
11. Omezte zadané množství bajtů počínaje prvníma
$ echo "cutting text from input" | cut -b -5
Tento příkaz ořízne prvních pět bajtů vstupního řetězce. Můžete řezat z počátečního bajtu na jakoukoli jinou pozici bajtu pouhým nahrazením hodnoty příznaku b. Nezapomeňte přidat předchozí pomlčku (-), jinak výstup nebude podle očekávání.
12. Vyjmout z prvního bajtu na zadanou pozici ze souboru
$ cut -b -5 test.txt
Výše uvedený příkaz vyjme z našeho textového souboru pouze prvních pět bajtů každého řádku. Všimněte si, jak se spojovník (-) používá pro příkazy 9-12 v tomto seznamu.
Vyjmout text na základě znaků
Příkaz vyjmout v Unixu umožňuje uživatelům vyjmout část textu na základě znaků. Když zpracováváte velké úlohy zpracování souborů, budete to muset dělat poměrně často. Vyzkoušejte je a všimněte si podobnosti mezi vyřezáváním na základě znaků a vyřezáváním na bázi bajtů.
13. Vyjmout pouze jeden znak ze vstupního streamu
$ echo "cutting text from input" | cut -c 1
Výše uvedený příkaz vyjme první znak ze standardního vstupu a zobrazí jej v terminálu. V tomto případě je to „c “. Změňte svůj řetězec na něco jiného, abyste tomu jasně rozuměli.
14. Vyjmout konkrétní znaky ze vstupního streamu
$ echo "cutting text from input" | cut -c 1,3
Tento příkaz vyjme pouze první a třetí znak vstupního řetězce a zobrazí je. Můžete zkusit vyjmout jiné znaky, ale pamatujte, abyste nepřekročili limit počtu znaků ve svém řetězci.
15. Vyjmout rozsah znaků ze vstupního streamu
$ echo "cutting text from input" | cut -c 1-12
V případě tohoto příkazu „cut“ ořízne znaky v rozsahu od první pozice do dvanácté pozice. Výsledkem bude „oříznutí textu “. Všimněte si podobnosti mezi tímto linuxovým příkazem cut a třetím příkazem.
16. Vyjmout pouze jeden znak z textového souboru
$ cut -c 1 test.txt
Tento příkaz zobrazí pouze první znaky každého z pěti řádků našeho souboru test.txt. Je ekvivalentní příkazu $ cat test.txt | cut -c 1 a poskytuje stejný výsledek, jaký bychom dostali při použití příznaku byte.
17. Vyjmout konkrétní znaky z textového souboru
$ cut -c 7,10 test.txt
Výše uvedený příkaz vyjme pouze sedmý a desátý znak z každých pěti řádků. Můžete zadat libovolné pozice znaků, pokud spadají do rozsahu dostupných znaků.
18. Vyjmout rozsah znaků textového souboru
$ cut -c 1-12 test.txt
Tento příkaz vypíše první až dvanáctý znak každého řádku v test.txt soubor. Příkaz cut v Unixu se chová stejně při ořezávání rozsahu znaků a rozsahu bajtů.
19. Vystřihněte prvních 5 postav v abecedním pořadí
$ cut -c 1-5 test.txt | sort
Výstup příkazu vyjmout můžete zadat jako vstup příkazu řazení pro oříznutí prvních pěti bajtů každého řádku abecedně. Příkaz řazení nevyžaduje při řazení podle abecedy žádné volby.
20. Vystřihněte prvních 5 postav v opačném pořadí
$ cut -c 1-5 test.txt | sort -r
Tento příkaz vyjmout vyjme prvních pět znaků z každého řádku a zobrazí je po obráceném řazení. Podívejte se, jak je výstup příkazu cut přiváděn do příkazu sort pomocí potrubí.
21. Vyjmout od pátého znaku po konec vstupního tokuu
$ echo "cutting text from input" | cut -c 5-
Výše uvedený příkaz cut ořízne text od pátého bajtu do konce řetězce. To může být výhodné, když potřebujete stříhat od zadané pozice znaku až do konce vstupního toku. Jednoduše změňte hodnotu po b při zachování koncové – zapnuté.
22. Vyjmout z pátého znaku na konec souboru
$ cut -c 5- test.txt
Tento příkaz spustí řezání každého z pěti řádků souboru test.txt od pozice pátého znaku a skončí po dosažení konce každého řádku. Koncová pomlčka (-) je pro tento druh operace povinná.
23. Vystřihněte určitý počet znaků počínaje první pozicí
$ echo "cutting text from input" | cut -c -5
Tento příkaz vyjme pouze prvních pět pozic znaků našeho vstupu. Z počátečního znaku můžete přecházet na libovolnou jinou pozici znaku pouhým nahrazením hodnoty -c . Nezapomeňte přidat předchozí pomlčku (-), jinak výstup nebude stejný, jak očekáváte.
24. Vyjmout z prvního znaku na určenou pozici ze souboru
$ cut -c -5 test.txt
Tento příkaz cut v Unixu vyjme prvních pět znaků každého řádku ze souboru test.txt. Všimněte si, jak se spojovník (-) používá pro příkazy 21-24 v tomto seznamu.
Vyjmout text ze sloupců pomocí polí a oddělovačů
Příkaz vyjmout umožňuje uživatelům velmi snadno vyjmout části textu. K tomu musíme použít d i f příznak řezu. Příznak d znamená oddělovače a f znamená pole. Oddělovače jsou speciální znaky, které oddělují část textu od ostatních. Mezi běžné příklady patří „-“, „:“ a „ “ (mezera). Referenční soubor, který používáme, má jako oddělovač „:“.
25. Vystřihněte první sekci vstupního toku
$ echo "Let's cut this input stream section by section" | cut -d ' ' -f 1
Výše uvedený příkaz vyjmout vyřízne první část textu („Pojďme“ v tomto případě) ze vstupního proudu. Všimněte si, že hodnota příznaku oddělovače -d je jeden prostor. Zkuste to s textem odděleným dvojtečkou a sami uvidíte, co se stane.
26. Vystřihněte první oddíl souboru
$ cut -d ':' -f 1 test.txt
Tento příkaz vrátí první sloupce každého řádku v našem referenčním souboru a vytiskne názvy všech pěti zemí. Hodnota poskytnutá příznaku oddělovače byla dvojtečka, protože tak náš soubor odděluje sloupce.
27. Vyjmout konkrétní části vstupního streamu
$ echo "Let's cut this input stream section by section" | cut -d ' ' -f 1,2,3
Zde jsme dali pokyn cut, aby zobrazil pouze první tři pole daného vstupního řetězce. To se provádí pomocí pole pozic polí oddělených čárkami. Výstupem tohoto příkazu bude ‘Pojďme to oříznout ‘.
28. Vyjmout konkrétní části souboru
$ cut -d ':' -f 1,2,3 test.txt
Tento příkaz také poskytne stejný druh výstupu jako předchozí příkaz. Zde cut pouze pracuje na souboru namísto standardního vstupu, to je vše. Měl by zobrazovat název, hlavní město a měnu každé země na seznamu. Všimněte si však rozdílu mezi jejich oddělovači (mezera vs. dvojtečka).
29. Vyjmout rozsah polí ze vstupního streamu
$ echo "Let's cut this input stream section by section" | cut -d ' ' -f 1-5
Výše uvedený příkaz vyřízne prvních pět polí řetězce a zobrazí jej v terminálu. Apostrofy jsou povinné, když se jako oddělovač mezi více poli používá mezera.
30. Vyjmout rozsah polí ze souboru
$ cut -d ':' -f 1-3 test.txt
Tento příkaz vyjmout vyřízne každý z prvních tří sloupců našeho textového souboru a zobrazí jej jako výstup. Měl by zobrazit stejný výsledek, jaký poskytuje příkaz předcházející předchozímu. Apostrofy nejsou povinné pro znaky jako – nebo :.
31. Vyjmout každou položku z konkrétního pole a uvést je v abecedním pořadí
$ cut -d ':' -f 1 test.txt | awk '{print $1}' | sort Předpokládejme, že potřebujete zjistit názvy pěti zemí v našem seznamu v abecedním pořadí, můžete k tomu použít výše uvedený příkaz. Zobrazí seznam zemí seřazených abecedně. Nahrazení hodnoty příznaku f vám to umožní podobně i na jiných polích.
32. Vyjměte každý záznam z pole a uveďte je v abecedně opačném pořadí
$ cut -d ':' -f 1 test.txt | awk '{print $1}' | sort -r Tento příkaz provede stejnou operaci jako výše uvedený, pouze seřadí položky opačným způsobem, to je vše. Výstup je zde změněn kvůli -r příznak předán k řazení.
33. Vyjmout z pevného pole na konec vstupního streamu
$ echo "Let's cut this input stream section by section" | cut -d ' ' -f 2-
Tento příkaz řezu bude řezat počínaje druhým polem až do konce řetězce. To může být výhodné, když potřebujete řezat z určené pozice až do konce vstupu. Hodnotu -f můžete změnit při zachování vleku – zapnuto pro řezání z různých polí.
34. Vyjmout z pevného pole na konec souboru
$ cut -d ':' -f 2- test.txt
Při tomto použití příkaz řezu začne řezat ze zadaného pole a bude pokračovat až na konec každého řádku. V tomto případě vytiskne hlavní město, měnu a obyvatelstvo každé z pěti zemí na seznamu.
35. Vyřízněte zadaný počet sloupců počínaje prvníma
$ echo "Let's cut this input stream section by section" | cut -d ' ' -f -5
Tento příkaz vyřízne pouze prvních pět polí daného vstupu. Z počátečního sloupce můžete přecházet na jakoukoli jinou pozici sloupce pouhým nahrazením hodnoty -f. Musíte však přidat předchozí pomlčku (-), jinak výstup nebude odpovídat vašemu očekávání.
36. Vyjmout některé zadané sloupce souboru počínaje prvníma
$ cut -d ':' -f -2 test.txt
Tento linuxový příkaz cut začne ořezávat náš soubor test.txt z prvního sloupce a skončí poté, co dokončí řezání druhého příkazu. Takže výstup tohoto příkazu jednoduše zobrazí název každé země a její příslušná hlavní města.
37. Vyjmout více polí ze souborů CSV
$ cut -d ',' -f 1,2 file.csv
Příkaz vyjmout se často ukáže jako životaschopný nástroj, když pracujete s masivními dokumenty CSV. Výše uvedený příkaz například vyjme první dva sloupce souboru CSV s názvem file.csv odděleného čárkami.
38. Vyjmout konkrétní pole souborů CSV a seřadit je v opačném pořadí
$ cut -d ',' -f 1,3,5 file.csv | sort -r
Výše uvedený příkaz vyjme první, třetí a pátý sloupec souboru CSV odděleného čárkami s názvem file.csv a zobrazí výstup v opačném pořadí.
Některé různé příkazy Linux Cut pro experty
Příkaz cut lze použít pro pokročilé zpracování souborů pomocí vhodných filtrů a dalších robustních příkazů Linuxu. Níže si projdeme několik takových příkazů, které vám mohou z dlouhodobého hlediska přinést užitek.
39. Zkontrolujte soubor passwd pomocí příkazu Cut
$ cut -d ':' -f1 /etc/passwd
Soubor passwd uložený v /etc ve většině systémů obsahuje velmi citlivé informace o systému a jeho uživatelích. Tento soubor můžete rychle zkontrolovat pomocí příkazu vyjmout. Oddělovač „:“ se používá, protože sloupce tohoto souboru jsou pomocí něj odděleny. Změňte hodnotu -f pro sledování různých polí.
40. Vyjmout konkrétní pole a zobrazit pouze jedinečné položky
$ cut -d ':' -f 3 test.txt | uniq -u
Tento příkaz cut v Linuxu vyřízne třetí sloupec souboru test.txt a zobrazí pouze jedinečné položky. Takže pro tento soubor bude výstup obsahovat pouze tři měny – konkrétně euro, liru a jen.
41. Vyjmout všechny bajty vstupního toku kromě specifikovaných
$ echo "Let's cut this input stream section by section" | cut -b 1,3,5,7 --complement
Tento příkaz vyjmout vyřízne všechny znaky daného vstupního řetězce kromě těch, které byly dodány do -b . Takže bajtové pozice první, třetí, pátá a sedmá budou z výstupu vynechány.
42. Vyjmout všechny bajty souboru kromě zadaných
$ cut -b 2,4,6 test.txt --complement
Při použití tímto způsobem příkaz cut vyřízne všechny bajty souboru test.txt kromě toho, který je uveden v příkazu. Výstup tedy nebude obsahovat druhý, čtvrtý a šestý bajt každého řádku.
43. Vyjmout všechny znaky vstupního streamu kromě specifikovaných
$ echo "Let's cut this input stream section by section" | cut -c 1,3,5,7 --complement
Tento příkaz se zdrží oříznutí prvního, třetího, pátého a sedmého znaku vstupního řetězce a místo toho ořízne všechny ostatní znaky kromě těchto čtyř.
44. Vyjmout všechny znaky souboru kromě zadaných
$ cut -c 2,4,6 test.txt --complement
V případě tohoto příkazu bude výstup obsahovat všechny znaky souborů test.txt kromě zmíněných. Druhé, čtvrté a šesté znaky se tedy nezobrazí.
45. Vystřihněte všechny vstupní sekce kromě těch určených
$ echo "Let's cut this input stream section by section" | cut -d ' ' -f 1,3,5 --complement
Výše uvedený příkaz vypíše řetězec „cut input section by section “. Zobrazí tedy všechny vstupní sekce bez těch uvedených za příznakem pole.
46. Vyjmout všechny sloupce souboru kromě zadaných
$ cut -d ':' -f 2,3 test.txt --complement
Tento příkaz vyjme pouze první a poslední sloupec souboru test.txt . Takže můžete snadno zrušit výběr některých polí při zpracování velkých tabulkových dokumentů pomocí příznaku doplňku.
47. Vystřihněte část vstupu a obraťte je na znaky
$ echo "Let's cut this input stream section by section" | rev | cut -d ' ' -f 1,3
Výše uvedený příkaz pro Linux přeruší první a třetí část vstupu a obrátí je podle znaků. Všimněte si, jak je výstup jednoho příkazu přiváděn jako vstup pro jiné příkazy.
48. Vyjmout konkrétní sloupce v souboru a obrátit je podle znaků
$ cut -d ':' -f 1,3 test.txt | rev
Tento příkaz pouze vyjme zadaná pole souboru test.txt a zobrazí výsledek obráceným způsobem.
49. Upravte výstupní oddělovač příkazu Vyjmout
$ echo "A,comma,separated,list,for,demonstration,purposes" | cut -d ',' -f 1- --output-delimiter=' '
Vyjmout nám umožňuje upravit výstupní oddělovač při zobrazení výsledku. Výše uvedený příkaz vyjme všechny části seznamu odděleného čárkami, ale při zobrazení výsledku nahradí čárky mezerami.
50. Příklad příkazu Cut+Sed s oddělovačem tabulátoru
$ sed 's/:/\t/g' test.txt | cut -f 1-4
Poslední příkaz vyjmout z našeho seznamu využívá mocný nástroj sed k nahrazení dvojteček v našem souboru tabulátory. Můžete nahradit \t s některými dalšími znaky jako – nebo; pro změnu na výstupní oddělovač dle vašeho výběru.
Konec myšlenek
Příkaz cut v Unixu je všestranný nástroj, který může pomoci uživatelům, kteří potřebují často zpracovávat velké soubory, řadu výhod. Nastínili jsme 50 nejlepších příkazů Linux cut, které vám pomohou seznámit se s tímto fantastickým nástrojem. Měli byste je vyzkoušet jednotlivě a upravit různé dostupné možnosti. To vám pomůže pochopit různé varianty příkazu řezu do hloubky. Doufáme, že jsme byli úspěšní v naší snaze vám co nejvíce pomoci. Zůstaňte s námi pro další připravované průvodce užitečnými příkazy Linuxu.