Pro úspěšnou práci s linuxovým editorem sed a příkazem awk ve vašich skriptech shellu musíte rozumět regulárním výrazům nebo zkráceně regulárnímu výrazu. Protože existuje mnoho motorů pro regulární výraz, použijeme regulární výraz shellu a uvidíme sílu bash při práci s regulárním výrazem.
Nejprve musíme pochopit, co je regulární výraz; pak uvidíme, jak to použít.
Co je regulární výraz
Někteří lidé, když poprvé viděli regulární výrazy, řekli si, co je to za ASCII zvratky!!
No, regulární výraz nebo regulární výraz obecně je vzor textu, který definujete a který linuxový program jako sed nebo awk používá k filtrování textu.
Některé z těchto vzorů jsme viděli při zavádění základních příkazů Linuxu a viděli jsme, jak příkaz ls používá zástupné znaky k filtrování výstupu.
Typy regulárních výrazů
Mnoho různých aplikací používá v Linuxu různé typy regulárních výrazů, jako je regulární výraz obsažený v programovacích jazycích (Java, Perl, Python) a linuxových programech jako (sed, awk, grep) a mnoha dalších aplikacích.
Vzor regulárního výrazu používá modul regulárních výrazů, který tyto vzory překládá.
Linux má dva motory regulárních výrazů:
- Základní regulární výraz (BRE) motor.
- Rozšířený regulární výraz (ERE) motor.
Většina linuxových programů funguje dobře se specifikacemi BRE engine, ale některé nástroje jako sed rozumí některým pravidlům BRE engine.
Motor POSIX ERE je dodáván s některými programovacími jazyky. Poskytuje více vzorů, jako je shoda číslic a slov. Příkaz awk používá stroj ERE ke zpracování svých vzorců regulárních výrazů.
Protože existuje mnoho implementací regulárních výrazů, je obtížné napsat vzory, které fungují na všech motorech. Proto se zaměříme na nejčastěji se vyskytující regulární výraz a ukážeme si, jak jej použít v sed a awk.
Definujte vzory BRE
Vzor, který bude odpovídat textu, můžete definovat takto:
$ echo "Testing regex using sed" | sed -n '/regex/p'
$ echo "Testing regex using awk" | awk '/regex/{print $0}'

Můžete si všimnout, že regulárnímu výrazu nezáleží na tom, kde se vzor vyskytuje nebo kolikrát v datovém toku.
První pravidlo, které je třeba vědět, je, že vzory regulárních výrazů rozlišují velká a malá písmena.
$ echo "Welcome to LikeGeeks" | awk '/Geeks/{print $0}' $ echo "Welcome to Likegeeks" | awk '/Geeks/{print $0}'

První regulární výraz je úspěšný, protože slovo „Geeks“ existuje velkými písmeny, zatímco druhý řádek selže, protože používá malá písmena.
Ve vzoru můžete použít mezery nebo čísla takto:
$ echo "Testing regex 2 again" | awk '/regex 2/{print $0}'

Speciální znaky
vzory regulárních výrazů používají některé speciální znaky. A nemůžete je zahrnout do svých vzorů, a pokud tak učiníte, nedosáhnete očekávaného výsledku.
Tyto speciální znaky jsou rozpoznány regulárním výrazem:
.*[]^${}\+?|() Tyto speciální znaky musíte ukončit pomocí znaku zpětného lomítka (\).
Chcete-li například odpovídat znaku dolaru ($), ukončete jej znakem zpětného lomítka, jako je tento:
$ cat myfile There is 10$ on my pocket
$ awk '/\$/{print $0}' myfile
Pokud potřebujete odpovídat samotnému zpětnému lomítku (\), musíte jej ukončit takto:
$ echo "\ is a special character" | awk '/\\/{print $0}'

Ačkoli lomítko není speciální znak, přesto se zobrazí chyba, pokud jej použijete přímo.
$ echo "3 / 2" | awk '///{print $0}'

Takže tomu musíte uniknout takto:
$ echo "3 / 2" | awk '/\//{print $0}'

Ukotvovací znaky
Chcete-li najít začátek řádku v textu, použijte znak stříšky (^).
Můžete jej použít takto:
$ echo "welcome to likegeeks website" | awk '/^likegeeks/{print $0}' $ echo "likegeeks website" | awk '/^likegeeks/{print $0}'

Znak stříšky (^) odpovídá začátku textu:
$ awk '/^this/{print $0}' myfile

Co když jej použijete uprostřed textu?
$ echo "This ^ caret is printed as it is" | sed -n '/s ^/p'

Je vytištěna jako normální znak.
Při použití awk jej musíte opustit takto:
$ echo "This ^ is a test" | awk '/s \^/{print $0}'

Tady jde o pohled na začátek textu, co o pohled na konec?
Znak dolaru ($) kontroluje konec řádku:
$ echo "Testing regex again" | awk '/again$/{print $0}'

Na stejném řádku můžete použít stříšku i dolar takto:
$ cat myfile this is a test This is another test And this is one more
$ awk '/^this is a test$/{print $0}' myfile
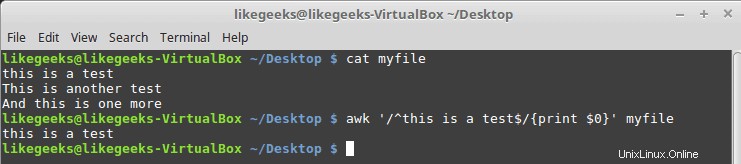
Jak vidíte, vytiskne pouze řádek, který má pouze odpovídající vzor.
Prázdné řádky můžete filtrovat pomocí následujícího vzoru:
$ awk '!/^$/{print $0}' myfile Zde představujeme negaci, kterou můžete provést pomocí vykřičníku!
Vzor hledá prázdné řádky, kde mezi začátkem a koncem řádku není nic, a neguje to, aby se vytiskly pouze řádky s textem.
Znak tečky
Znak tečka používáme k nalezení jakéhokoli znaku kromě nového řádku (\n).
Pro představu se podívejte na následující příklad:
$ cat myfile this is a test This is another test And this is one more start with this
$ awk '/.st/{print $0}' myfile
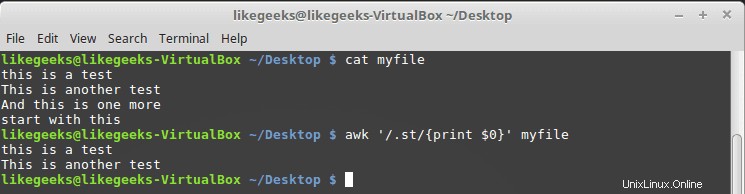
Z výsledku můžete vidět, že vytiskne pouze první dva řádky, protože obsahují vzor st, zatímco třetí řádek tento vzor nemá a čtvrtý řádek začíná st, takže to také neodpovídá našemu vzoru.
Třídy znaků
Ke speciálnímu znaku tečky můžete přiřadit jakýkoli znak, ale co když porovnáte pouze sadu znaků, můžete použít třídu znaků.
Třída znaků odpovídá sadě znaků, pokud se některý z nich najde, vzor se shoduje.
Třídy znaků můžeme definovat pomocí hranatých závorek [] takto:
$ awk '/[oi]th/{print $0}' myfile
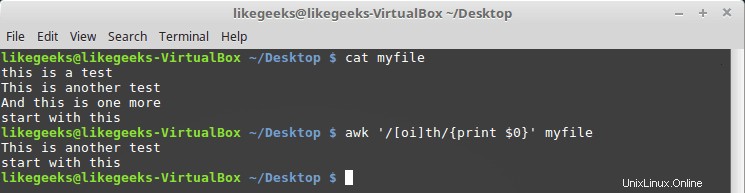
Zde hledáme všechny znaky, které mají o znak nebo i před ním.
To se hodí, když hledáte slova, která mohou obsahovat velká nebo malá písmena a nejste si tím jisti.
$ echo "testing regex" | awk '/[Tt]esting regex/{print $0}' $ echo "Testing regex" | awk '/[Tt]esting regex/{print $0}'

Samozřejmě se neomezuje na postavy; můžete použít čísla nebo cokoli chcete. Můžete jej používat, jak chcete, pokud máte nápad.
Negování tříd znaků
Co takhle hledat postavu, která není ve třídě postav?
Chcete-li toho dosáhnout, uveďte před rozsah třídy znaků stříšku, jako je tato:
$ awk '/[^oi]th/{print $0}' myfile
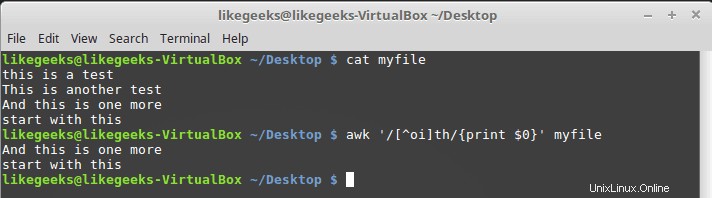
Takže je přijatelné cokoli kromě o a i.
Použití rozsahů
Chcete-li zadat rozsah znaků, můžete použít symbol (-) takto:
$ awk '/[e-p]st/{print $0}' myfile
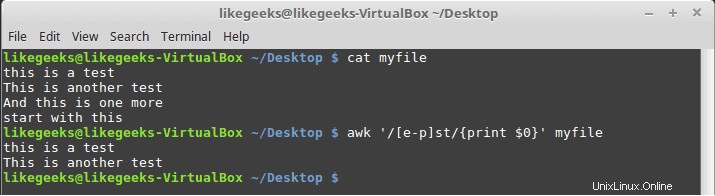
To odpovídá všem znakům mezi e a p, poté následuje st, jak je znázorněno.
Pro čísla můžete také použít rozsahy:
$ echo "123" | awk '/[0-9][0-9][0-9]/'
$ echo "12a" | awk '/[0-9][0-9][0-9]/'

Můžete použít více a oddělených rozsahů takto:
$ awk '/[a-fm-z]st/{print $0}' myfile
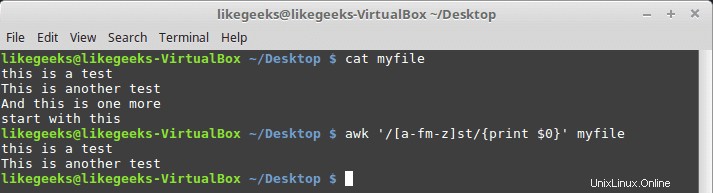
Vzor zde znamená od a do f a m až z se musí objevit před textem st.
Speciální třídy znaků
Následující seznam obsahuje třídy speciálních znaků, které je můžete použít:
| [[:alnum:]] | Vzor pro 0–9, A–Z nebo a–z. |
| [[:blank:]] | Vzor pouze pro mezeru nebo kartu. |
| [[:digit:]] | Vzor pro 0 až 9. |
| [[:lower:]] | Vzor pouze pro malá písmena a–z. |
| [[:print:]] | Vzor pro jakýkoli tisknutelný znak. |
| [[:punct:]] | Vzor pro jakýkoli interpunkční znak. |
| [[:space:]] | Vzor pro jakýkoli znak mezery:mezera, Tab, NL, FF, VT, CR. |
| [[:upper:]] | Vzor pouze pro velká písmena A–Z. |
Můžete je použít takto:
$ echo "abc" | awk '/[[:alpha:]]/{print $0}' $ echo "abc" | awk '/[[:digit:]]/{print $0}' $ echo "abc123" | awk '/[[:digit:]]/{print $0}'

Hvězdička
Hvězdička znamená, že znak musí existovat nula nebo vícekrát.
$ echo "test" | awk '/tes*t/{print $0}' $ echo "tessst" | awk '/tes*t/{print $0}'

Tento symbol vzoru je užitečný pro kontrolu překlepů nebo jazykových variací.
$ echo "I like green color" | awk '/colou*r/{print $0}' $ echo "I like green colour " | awk '/colou*r/{print $0}'

Zde v těchto příkladech platí, že ať už zadáte barvu nebo barvu, bude se shodovat, protože hvězdička znamená, zda znak „u“ existoval mnohokrát nebo nula čas, který bude odpovídat.
Chcete-li porovnat libovolné číslo libovolného znaku, můžete použít tečku s hvězdičkou takhle:
$ awk '/this.*test/{print $0}' myfile
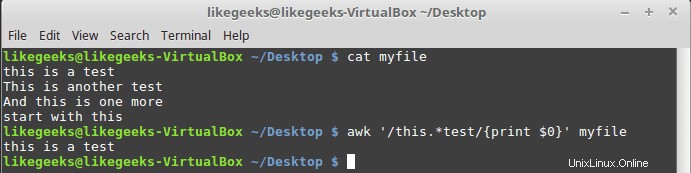
Nezáleží na tom, kolik slov mezi slovy „toto“ a „test“ se vytiskne, jakýkoli odpovídající řádek se vytiskne.
Znak hvězdička můžete použít s třídou znaků.
$ echo "st" | awk '/s[ae]*t/{print $0}' $ echo "sat" | awk '/s[ae]*t/{print $0}' $ echo "set" | awk '/s[ae]*t/{print $0}'
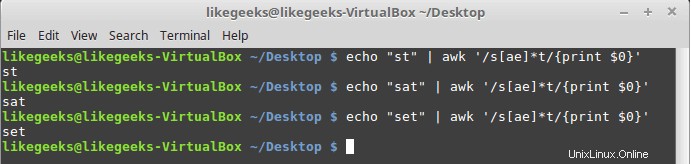
Všechny tři příklady se shodují, protože hvězdička znamená, že pokud nenajdete nulakrát nebo více, vytiskne jakýkoli znak „a“ nebo „e“.
Rozšířené regulární výrazy
Níže jsou uvedeny některé vzory, které patří k Posix ERE:
Otazník
Otazník znamená, že předchozí znak může existovat jednou nebo žádný.
$ echo "tet" | awk '/tes?t/{print $0}' $ echo "test" | awk '/tes?t/{print $0}' $ echo "tesst" | awk '/tes?t/{print $0}'
Otazník můžeme použít v kombinaci s třídou znaků:
$ echo "tst" | awk '/t[ae]?st/{print $0}' $ echo "teest" | awk '/t[ae]?st/{print $0}' $ echo "tast" | awk '/t[ae]?st/{print $0}' $ echo "taest" | awk '/t[ae]?st/{print $0}' $ echo "teest" | awk '/t[ae]?st/{print $0}'
Pokud některá z položek znakové třídy existuje, porovnávání vzorů projde. Jinak vzor selže.
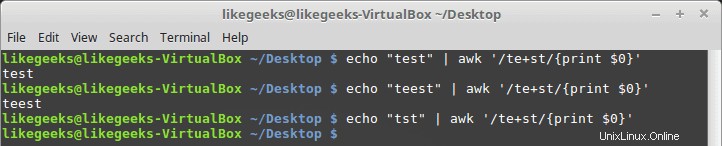
Znaménko plus
Znaménko plus znamená, že znak před znaménkem plus by měl existovat jednou nebo vícekrát, ale musí existovat alespoň jednou.
$ echo "teest" | awk '/te+st/{print $0}' $ echo "teest" | awk '/te+st/{print $0}' $ echo "tst" | awk '/te+st/{print $0}'
Pokud znak „e“ nebyl nalezen, selže.
Můžete jej použít s třídami postav, jako je tato:
$ echo "tst" | awk '/t[ae]+st/{print $0}' $ echo "test" | awk '/t[ae]+st/{print $0}' $ echo "teast" | awk '/t[ae]+st/{print $0}' $ echo "teeast" | awk '/t[ae]+st/{print $0}'
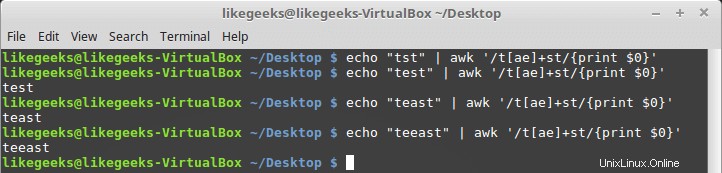
pokud existuje jakýkoli znak ze třídy znaků, uspěje.
Složené závorky
Složené závorky umožňují zadat počet existence vzoru, má dva formáty:
n:Regulární výraz se objeví přesně nkrát.
n,m:Regulární výraz se objeví alespoň nkrát, ale ne více než mkrát.
$ echo "tst" | awk '/te{1}st/{print $0}' $ echo "test" | awk '/te{1}st/{print $0}'

Ve starých verzích awk byste měli pro příkaz awk použít volbu –re-interval, aby četl složené závorky, ale v novějších verzích to nepotřebujete.
$ echo "tst" | awk '/te{1,2}st/{print $0}' $ echo "teest" | awk '/te{1,2}st/{print $0}' $ echo "teest" | awk '/te{1,2}st/{print $0}' $ echo "teeest" | awk '/te{1,2}st/{print $0}'

V tomto příkladu, pokud znak „e“ existuje jednou nebo dvakrát, uspěje; jinak se nezdaří.
Můžete jej použít s třídami postav, jako je tato:
$ echo "tst" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teest" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teest" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teeast" | awk '/t[ae]{1,2}st/{print $0}'
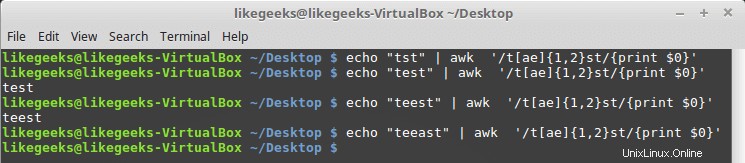
Pokud existuje jeden nebo dva výskyty písmene „a“ nebo „e“, vzor projde; jinak se nezdaří.
Symbol potrubí
Symbol čáry tvoří logické NEBO mezi 2 vzory. Pokud jeden ze vzorů existuje, uspěje; jinak selže, zde je příklad:
$ echo "Testing regex" | awk '/regex|regular expressions/{print $0}' $ echo "Testing regular expressions" | awk '/regex|regular expressions/{print $0}' $ echo "This is something else" | awk '/regex|regular expressions/{print $0}'
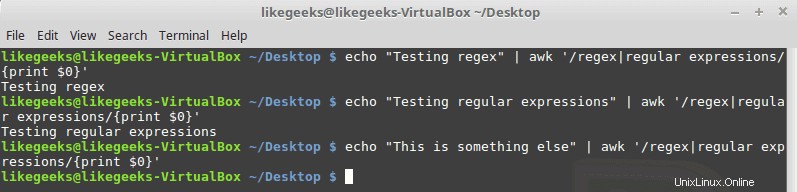
Mezi vzor a symbol dýmky nepište žádné mezery.
Skupinové výrazy
Výrazy můžete seskupit, aby je regulární výrazy považovaly za jeden kus.
$ echo "Like" | awk '/Like(Geeks)?/{print $0}' $ echo "LikeGeeks" | awk '/Like(Geeks)?/{print $0}'
Seskupení „Geeks“ způsobuje, že motor regulárních výrazů s ním zachází jako s jedním kusem, takže pokud existuje „LikeGeeks“ nebo slovo „Like“, uspěje.
Praktické příklady
Viděli jsme několik jednoduchých ukázek používání vzorů regulárních výrazů. Je čas to uvést do praxe, jen pro procvičování.
Počítání adresářových souborů
Podívejme se na bash skript, který počítá spustitelné soubory ve složce z proměnné prostředí PATH.
$ echo $PATH
Chcete-li získat výpis adresáře, musíte nahradit každou dvojtečku mezerou.
$ echo $PATH | sed 's/:/ /g'
Nyní iterujme každý adresář pomocí cyklu for takto:
mypath=$(echo $PATH | sed 's/:/ /g') for directory in $mypath; do done
Skvělé!!
Soubory v každém adresáři můžete získat pomocí příkazu ls a uložit je do proměnné.
#!/bin/bash path_dir=$(echo $PATH | sed 's/:/ /g') total=0 for folder in $path_dir; do files=$(ls $folder) for file in $files; do total=$(($total + 1)) done echo "$folder - $total" total=0 done
Můžete si všimnout, že některé adresáře neexistují, s tím není problém, je to v pořádku.
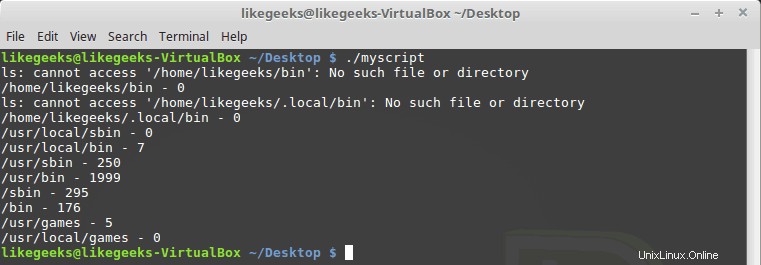
Chladný!! Toto je síla regulárního výrazu – těchto pár řádků kódu počítá všechny soubory ve všech adresářích. Samozřejmě existuje linuxový příkaz, jak to udělat velmi snadno, ale zde diskutujeme o tom, jak použít regex na něco, co můžete použít. Můžete přijít s dalšími užitečnými nápady.
Ověřování e-mailové adresy
Existuje spousta webových stránek, které nabízejí vzory regulárních výrazů připravené k použití pro všechno, včetně e-mailu, telefonního čísla a mnoha dalších, je to užitečné, ale chceme pochopit, jak to funguje.
example@unixlinux.online
Uživatelské jméno může používat libovolné alfanumerické znaky v kombinaci s tečkou, pomlčkou, znaménkem plus a podtržítkem.
Název hostitele může používat libovolné alfanumerické znaky kombinované s tečkou a podtržítkem.
Pro uživatelské jméno platí následující vzor pro všechna uživatelská jména:
^([a-zA-Z0-9_\-\.\+]+)@
Znaménko plus znamená, že musí existovat jeden nebo více znaků následovaný znakem @.
Vzor názvu hostitele by pak měl vypadat takto:
([a-zA-Z0-9_\-\.]+)
Pro TLD nebo domény nejvyšší úrovně existují zvláštní pravidla, která nesmí být kratší než 2 a maximálně pět znaků. Následuje vzor regulárního výrazu pro doménu nejvyšší úrovně.
\.([a-zA-Z]{2,5})$ Nyní je dáme dohromady:
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$ Pojďme tento regulární výraz otestovat proti e-mailu:
$ echo "example@unixlinux.online" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}' $ echo "example@unixlinux.online" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}'

Skvělé!!
To byl jen začátek světa regulárních výrazů, který nikdy nekončí. Doufám, že rozumíte těmto ASCII zvratkům 🙂 a používáte je profesionálněji.
Doufám, že se vám příspěvek líbí.
Děkuji.