Vytváření statistických grafů v Pythonu může být bolestné, zvláště pokud je generujete ručně. Ale s pomocí knihovny vizualizace dat Seaborn Python si můžete zjednodušit práci a vytvořit krásné grafy rychle as menším počtem řádků kódu.
Se Seabornem je vytváření krásných statistických grafů pro vaše data hračka. Tato příručka vám ukáže, jak používat tuto výkonnou knihovnu na příkladech ze skutečného života.
Předpoklady
Tento tutoriál bude praktickou ukázkou. Pokud je chcete sledovat, ujistěte se, že máte následující:
- Počítač se systémem Windows nebo Linux s nainstalovanými programy Python a Anaconda. Tento tutoriál bude používat Anaconda 2021.11 s Pythonem 3.9 na Windows 10 PC.
Co je to Seaborn Python Library?
Knihovna Seaborn Python je knihovna Python pro vizualizaci dat postavená na knihovně Matplotlib. Seaborn nabízí bohatou sadu nástrojů na vysoké úrovni pro vytváření statistických grafů a grafů. Schopnost Seabornu integrovat se s objekty Pandas Dataframe vám umožňuje rychle vizualizovat data.
Datový rámec představuje tabulková data, například to, co byste našli v tabulce, tabulce nebo souboru CSV s hodnotami oddělenými čárkami.
Seaborn pracuje s Pandas DataFrames a převádí data pod kapotou na kód, kterému Matplotlib rozumí.
Přestože je k dispozici mnoho vysoce kvalitních pozemků, v tomto tutoriálu se dozvíte o třech nejběžnějších vestavěných rodinách pozemků Seaborn, které vám pomohou začít.
- Relační grafy.
- Distribuční grafy.
- Kategorické grafy.
Seaborn obsahuje mnohem více zápletek a tento tutoriál nemůže pokrýt všechny. Dokumentace Seaborn API a výukový program jsou skvělými výchozími body pro seznámení se všemi různými druhy zápletek Seaborn.
Nastavení nového prostředí JupyterLab a Seaborn Python
Než se vydáte na cestu Seaborn, musíte nejprve nastavit prostředí Jupyter Lab. Kvůli konzistenci s příklady budete spolu s tímto návodem pracovat také na konkrétní datové sadě.
JupyterLab je webová aplikace, která umožňuje kombinovat kód, formátovaný text, grafy a další média do jednoho dokumentu. Poznámkové bloky můžete také sdílet online s ostatními nebo je používat jako spustitelné dokumenty.
Chcete-li začít s nastavením prostředí, postupujte podle těchto kroků.
1. Otevřete Anaconda Navigato r na vašem počítači.
A. V počítači se systémem Windows:Klikněte na Start —> Anaconda3 —> Anaconda Navigator .
b. Na počítači se systémem Linux:Spusťte anaconda-navigator příkaz na terminálu.
2. V Anaconda Navigator vyhledejte JupyterLab aplikaci a klikněte na Spustit . Pokud tak učiníte, otevře se instance JupyterLab ve webovém prohlížeči.

3. Po spuštění JypyterLab otevřete postranní panel Prohlížeče souborů a vytvořte novou složku s názvem ATA_Seaborn pod vaším profilem nebo domovským adresářem. Tato nová složka bude vaším projektovým adresářem.
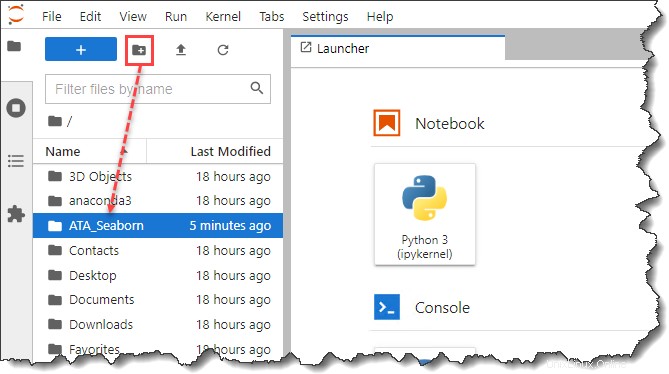
4. Dále otevřete novou kartu prohlížeče a stáhněte si Pokémona datový soubor. Nezapomeňte uložit ata_pokemon.csv soubor do adresáře projektu, který jste vytvořili, což je v tomto příkladu ATA_Seaborn .
5. Vraťte se do JupyterLab a dvakrát klikněte na ATA_Seaborn složku. Nyní byste měli vidět ata_pokemon.csv pod tou složkou.
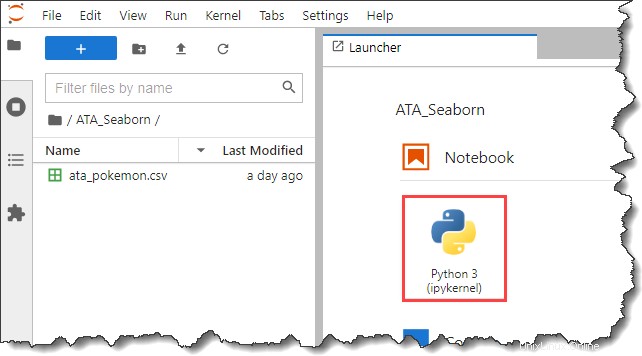
6. Nyní klikněte na Python 3 pod Notebook v sekci Spouštěč vytvořte nový poznámkový blok.
7. Nyní klikněte na nový poznámkový blok Untitled.ipynb a stiskněte F2 pro přejmenování souboru. Změňte název souboru na ata_pokemon.ipynb .

8. Dále přidejte název do poznámkového bloku. Tento krok je volitelný, ale doporučuje se, aby byl váš projekt lépe identifikovatelný.
Na panelu nástrojů poznámkového bloku klikněte na rozbalovací nabídku Kód a klikněte na Označit.
9. Do buňky markdown zadejte text „# Pokemon Data Visualization“ a stiskněte klávesy Shift + Enter.
Výběr typu buňky se automaticky změní na Kód a notebook bude mít název Vizualizace dat Pokémonů Nahoře.
10. Nakonec uložte svou práci stisknutím kláves Ctrl + S.
Ujistěte se, že si práci často ukládáte. Svou práci byste měli často ukládat, abyste v případě problémů s připojením k internetu o nic nepřišli. Kdykoli provedete změnu, stiskněte
CTRL+Suložit svůj postup. Můžete také kliknout na tlačítko Uložit na panelu nástrojů.
Import knihoven Pandy a Seaborn Python
Kód Pythonu obvykle začíná importem potřebných knihoven. A v tomto projektu budete pracovat s knihovnami Pandas a Seaborn Python.
Chcete-li importovat Pandy a Seaborn, zkopírujte níže uvedený kód a vložte jej do příkazové buňky v notebooku.
Toto si zapamatujte – pro spuštění kódu nebo příkazů v buňce příkazu stiskněte klávesy Shift + Enter.
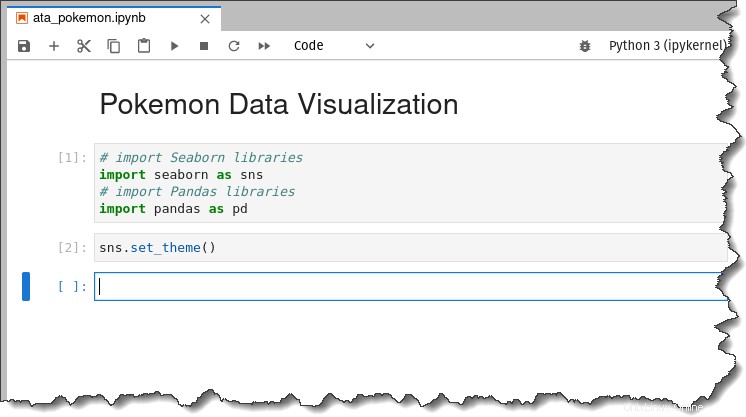
# import Seaborn libraries
import seaborn as sns
# import Pandas libraries
import pandas as pdDále spusťte níže uvedený příkaz a použijte výchozí estetiku motivu Seaborn na výkresy, které budete generovat.
sns.set_theme()
Seaborn má k dispozici pět integrovaných motivů. Jsou darkgrid (výchozí), whitegrid , dark , white a ticks .
Import ukázkové datové sady
Nyní, když jste nastavili prostředí JupyterLab, pojďme importovat data z datové sady do vašeho prostředí Jupyter.
1. Spusťte pd.read_csv() příkaz v buňce pro import dat. Název souboru datové sady musí být uvnitř závorky, aby označoval soubor k importu, uzavřený do uvozovek.
Níže uvedený příkaz importuje soubor ata_pokemon.csv a uložte datovou sadu do pokemon variabilní.
pokemon = pd.read_csv("ata_pokemon.csv")
2. Spusťte pokemon.head() k náhledu prvních pěti řádků importované datové sady.
pokemon.head()Získáte následující výstup.
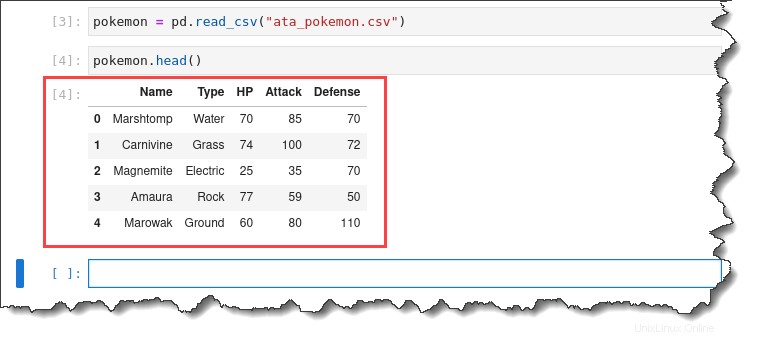
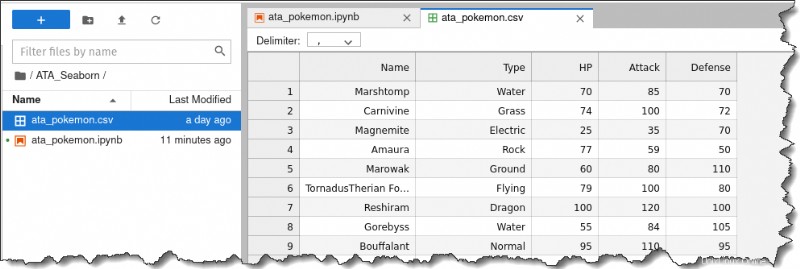
3. Dvakrát klikněte na ata_pokemon.csv soubor vlevo pro kontrolu každého jednotlivého řádku. Získáte následující výstup.
Jak vidíte, s touto datovou sadou se docela pohodlně pracuje, protože uvádí každé pozorování po řádcích a všechny číselné informace jsou v samostatných sloupcích.
Nyní si položme několik otázek o datové sadě, které nám pomohou s analýzou.
- Jaký je vztah mezi Attack a HP?
- Jaká je distribuce Attack?
- Jaký je vztah mezi Attack a Type?
- Jaká je distribuce Attack pro jednotlivé typy?
- Jaký je průměrný nebo průměrný útok pro každý typ?
- A jaký je počet Pokémonů pro každý typ?
Všimněte si, že mnoho z těchto otázek se zaměřuje na číselné a kategorické vztahy dat. Kategorická data znamenají nenumerická data, která v tomto vzorovém souboru dat představuje typ Pokémona.
Na rozdíl od Matplotlib, který je optimalizován pro vytváření grafů s přísně číselnými daty, můžete Seaborn použít k analýze dat, která obsahují jak kategorická, tak číselná data.
Vytváření grafů vztahů
Takže jste importovali datovou sadu. Co bude dál? Nyní budete používat svá importovaná data a generovat z nich statistické grafy. Začněme vytvořením relačního nebo vztahového vykreslování, abychom objevili vztah mezi HP a Útok data.
Vykreslování vztahů je praktické při identifikaci možných vztahů mezi proměnnými ve vaší datové sadě. Seaborn má dva grafy pro vykreslení vztahů:bodový graf a čárový graf.
Čárové vykreslování
Vytvoření čárového grafu vyžaduje, abyste zavolali Seaborn Python lineplot() funkce. Tato funkce má tři parametry — data= , x=' a y=' ‘.
Zkopírujte níže uvedený příkaz a spusťte jej v buňce příkazu Jupyter. Tento příkaz používá pokemon objekt jako zdroj dat, který jste dříve importovali, HP data sloupce pro osu x a Attack data pro osu y.
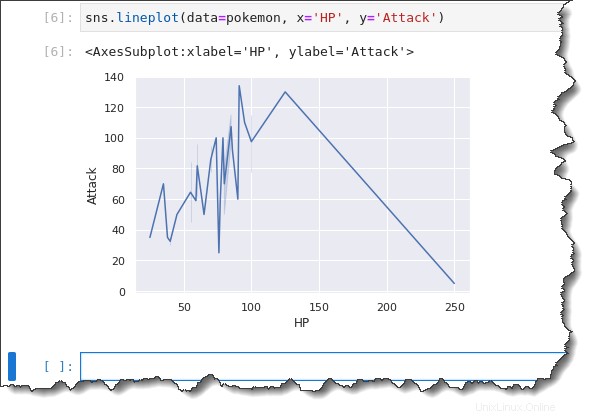
sns.lineplot(data=pokemon, x='HP', y='Attack')Jak můžete vidět níže, čárový graf neodvádí skvělou práci při zobrazování informací, které můžete rychle analyzovat. Čárový graf lépe zobrazuje osu x, která sleduje spojitou proměnnou, jako je čas.
V tomto příkladu vykreslujete diskrétní proměnnou HP. Stane se tedy, že čárový děj se rozprostírá všude. A je těžší odvodit trend.
Rozptylování
Součástí průzkumné analýzy dat je zkoušení různých věcí, abyste zjistili, co funguje dobře. A přitom se dozvíte, že některé grafy vám mohou ukázat lepší postřehy než jiné.
Co tedy dělá lepší zápletku vztahů než zápletky? — Bodové grafy.
Chcete-li vytvořit bodový graf, zavoláte funkci bodového grafu sns.scatterplot a předejte tři parametry: data=pokemon , x=HP a y=Attack .
Spusťte následující příkaz a vytvořte bodový graf pro datovou sadu pokémonů.
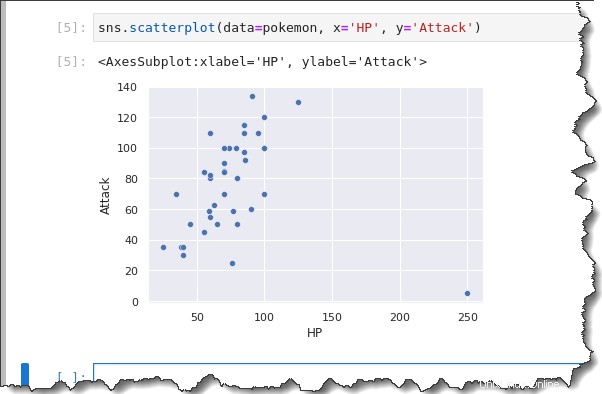
sns.scatterplot(data=pokemon, x='HP', y='Attack')Jak můžete vidět na níže uvedeném výsledku, bodový graf ukazuje, že mezi HP může existovat obecná pozitivní korelace (osa x) a Útok (osa y), s jednou odlehlou hodnotou.
Obecně platí, že jak se zvyšuje HP, zvyšuje se i útok. Pokémoni s většími body zdraví bývají silnější.
Rozptylování pomocí legend
Zatímco bodový graf již představoval rozumnější vizualizaci dat, můžete graf ještě dále vylepšit rozdělením rozdělení typů pomocí legendy.
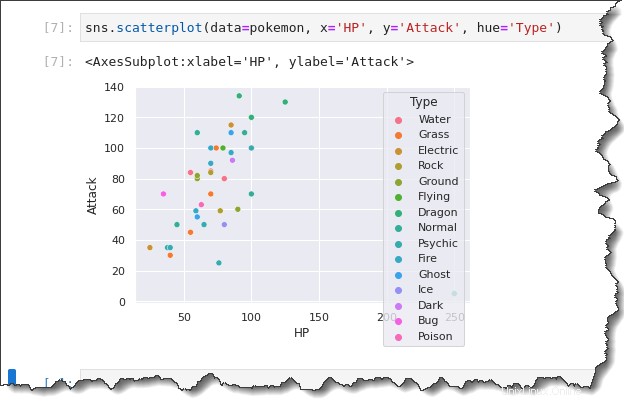
Spusťte sns.scatterplot() fungovat znovu v následujícím příkladu. Tentokrát však přidejte hue='Type' klíčové slovo, které vytvoří legendu zobrazující různé typy pokémonů. Zpět na kartě notebooku Jupyter spusťte níže uvedený příkaz.
sns.scatterplot(data=pokemon, x='HP', y='Attack', hue='Type')Všimněte si níže uvedeného výsledku, bodový graf má nyní jiné barvy. Analýza kategorických aspektů vašich dat je nyní mnohem lepší díky vizuálním rozdílům, které legenda poskytuje.
Ještě lepší je, že pomocí sns.relplot() můžete děj rozdělit ještě dále pomocí col=Type a col_wrap argumenty klíčových slov.
Spusťte níže uvedený příkaz v Jupyteru a vytvořte graf pro každý typ Pokémona ve formátu multi-plot grids.
sns.relplot(data=pokemon, x='HP', y='Attack', hue='Type', col='Type', col_wrap=3)Při pohledu na výsledek níže můžete usoudit, že HP a Attack jsou obecně poněkud pozitivně korelovány. Pokémoni s více HP bývají silnější.
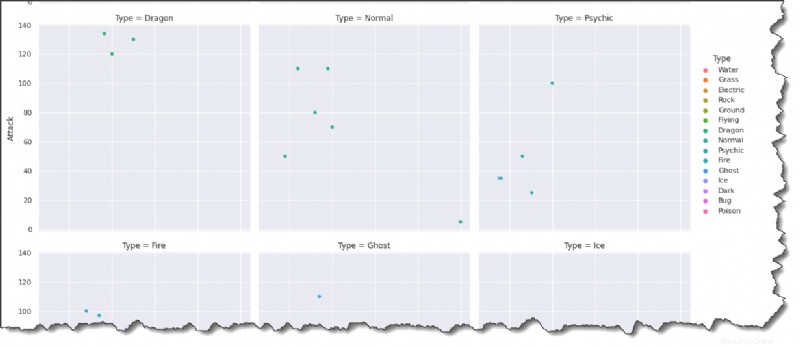
Souhlasíte s tím, že přidáním barev a legend bude vykreslování zajímavější?
Vytváření distribučních grafů
V předchozí části jste vytvořili bodový graf. Tentokrát použijeme distribuční graf, abychom získali přehled o distribuci Attack a HP pro každý typ Pokémona.
Vykreslování histogramu
Histogram můžete použít k vizualizaci rozložení proměnné. Ve vaší ukázkové datové sadě je proměnnou Pokémonův útok.
Chcete-li vytvořit graf histogramu, spusťte sns.histplot() funkce níže. Tato funkce má dva parametry:data=pokemon a x='Attack' . Zkopírujte níže uvedený příkaz a spusťte jej v Jupyter.
sns.histplot(data=pokemon, x='Attack')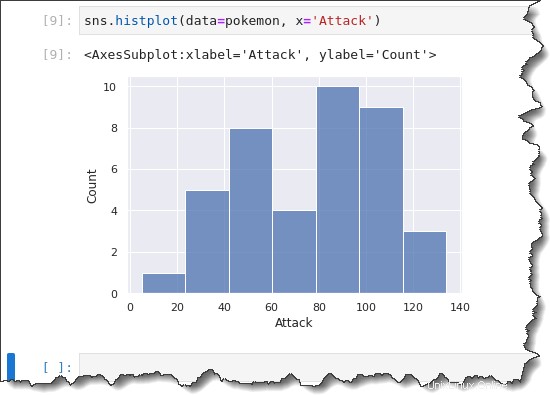
Při vytváření histogramu pro vás Seaborn automaticky vybere optimální velikost koše. Možná budete chtít změnit velikost přihrádky, abyste mohli sledovat rozložení dat v různě tvarovaných seskupení.
Chcete-li zadat pevnou nebo vlastní velikost přihrádky, připojte bins=x argument k příkazu kde x je vlastní velikost koše. Spusťte níže uvedený příkaz a vytvořte histogram s velikostí koše 10.
sns.histplot(data=pokemon, x='Attack', bins=10)V předchozím histogramu, který jste vytvořili, se zdá, že útok Pokémona má bimodální rozložení (dva velké hrby.)
Ale když se podíváte na velikost vaší přihrádky 10, seskupení jsou rozdělena více segmentově. Můžete vidět, že existuje více unimodální distribuce se zkosením doprava.
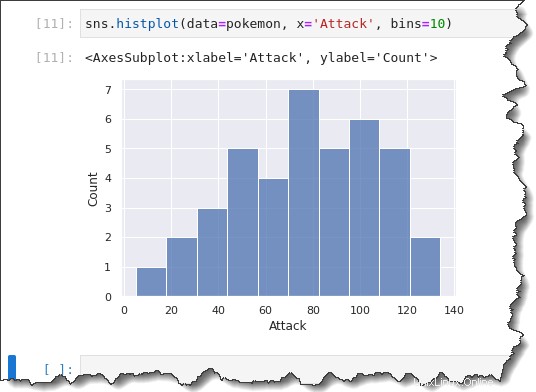
Vykreslování odhadu hustoty jádra (KDE)
Dalším způsobem vizualizace distribuce je vykreslení odhadu hustoty jádra. KDE je v podstatě jako histogram, ale s křivkami namísto sloupců.
Výhodou použití grafu KDE je, že můžete rychleji usuzovat o tom, jak jsou data distribuována díky pravděpodobnostní křivce, která ukazuje vlastnosti, jako je centrální tendence, modalita a šikmost.
Chcete-li vytvořit graf KDE, zavolejte sns.kdeplot() funkci a předat ve stejném data=pokemon , x='Attack' jako argumenty. Spusťte níže uvedený kód v Jupyteru, abyste viděli graf KDE v akci.
sns.kdeplot(data=pokemon, x='Attack')Jak můžete vidět níže, graf KDE je podobný zkreslení jako histogram s velikostí koše 10.
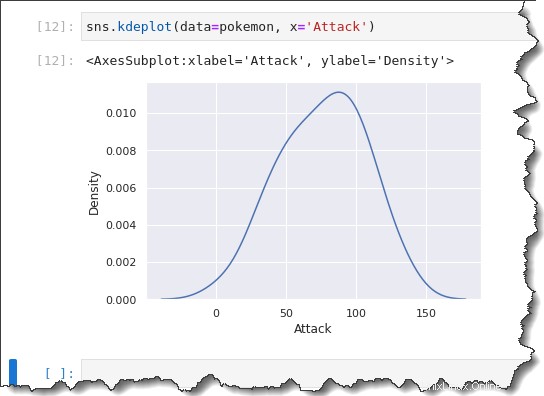
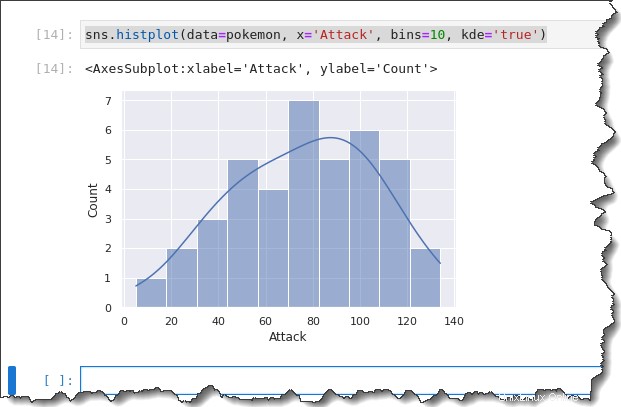
Protože histogram a KDE jsou podobné, proč je nepoužít společně? Seaborn vám umožňuje překrýt KDE na histogramu přidáním klíčového slova kde='true' argument k předchozímu příkazu, jak můžete vidět níže.
sns.histplot(data=pokemon, x='Attack', bins=10, kde='true')Získáte následující výstup. Podle histogramu níže má většina Pokémonů bod útoku rozdělený mezi 50 a 120. Není to pěkné rozšíření!
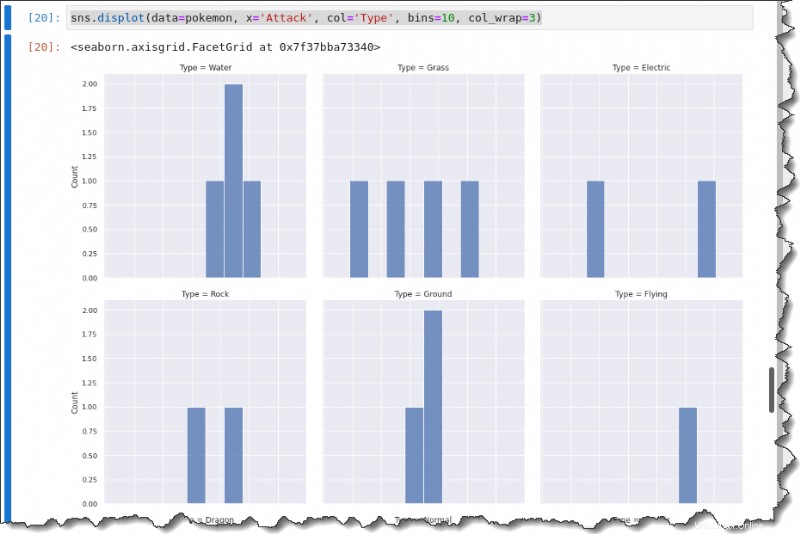
Chcete-li rozdělit jednotlivé distribuce útoků podle typu, zavolejte displot() funkce s col klíčové slovo níže pro vytvoření multimřížkového grafu zobrazujícího každý typ.
sns.displot(data=pokemon, x='Attack', col='Type', bins=10, col_wrap=3)Získáte následující výstup.
Generování kategorických grafů
Dělat samostatné histogramy na základě kategorie typu je fajn. Histogramy vám však nemusí poskytnout jasný obrázek. Použijme tedy některé kategorické grafy Seaborn, které vám pomohou ponořit se dále do analýzy dat o útocích na základě typů Pokémonů.
Vykreslování pruhů
V předchozích bodových grafech a histogramech jste se pokusili vizualizovat data útoku podle kategorické proměnné (Type ). Tentokrát vytvoříte pruhový graf, sérii bodových grafů seskupených podle kategorií.
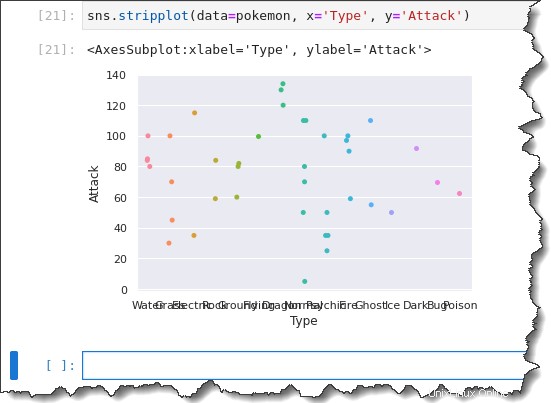
Chcete-li vytvořit svůj kategorický pásový graf, zavolejte sns.stripplot() funkci a předejte tři argumenty:data=pokemon , x='Type' a y='Attack' . Spuštěním níže uvedeného kódu v Jupyteru vygenerujte graf kategorických pruhů.
sns.stripplot(data=pokemon, x='Type', y='Attack')Nyní máte pruhový graf se všemi pozorováními seskupenými podle typu. Ale všimněte si, jak jsou všechny štítky na ose x rozbité dohromady? To není tak užitečné, že?
Chcete-li opravit štítky osy x, budete muset použít jinou funkci nazvanou catplot() .
V buňce příkazu notebooku Jupyter spusťte sns.catplot() funkci a předejte pět argumentůkind='strip' , data=pokemon , x='Type' , y='Attack' aaspect=2 , jak je uvedeno níže.
sns.catplot(kind='strip', data=pokemon, x='Type', y='Attack', aspect=2)Tentokrát výsledný květináč zobrazuje popisky osy x v plné šířce, takže vaše analýza je pohodlnější.
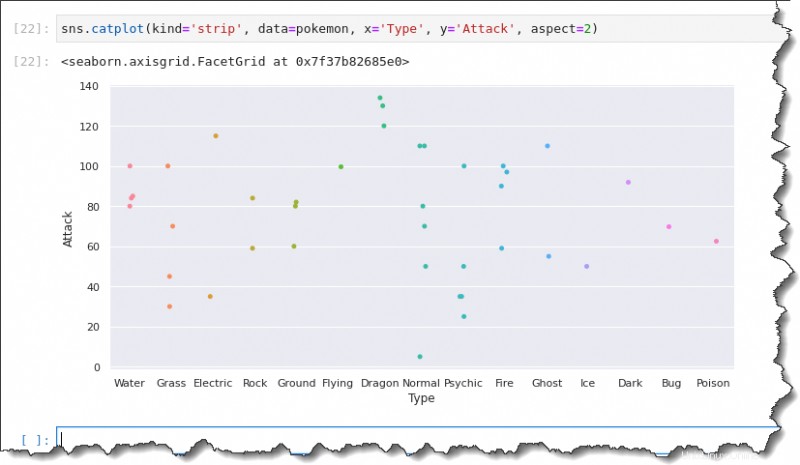
Krabicové vykreslování
catplot() má další podrodinu grafů, které vám pomohou vizualizovat distribuci dat pomocí kategoriální proměnné. Jedním z nich je krabicová zápletka.
Chcete-li vytvořit krabicový graf, spusťte sns.catplot() funkce s následujícími argumenty:data=pokemon , kind='box' , x='Type' , y='Attack' a aspect=2 .
aspect argument řídí mezery mezi popisky osy x. Vyšší hodnota znamená širší rozptyl.
sns.catplot(data=pokemon, kind='box', x='Type', y='Attack', aspect=2)
Tento výstup poskytuje souhrn údajů o šíření. Pomocí catplot() můžete získat rozložení dat pro každý typ Pokémona na jednom pozemku.
Všimněte si, že černé diamantové značky představují odlehlé hodnoty. Namísto krabicového grafu čára uprostřed znamená, že pro daný typ Pokémona existuje pouze jedno pozorování.
Pro každý z těchto políček a vousů máte k dispozici pěticiferný souhrn. Čára uprostřed rámečku představuje střední hodnotu nebo jejich centrální tendenci bodů útoku.
Máte také první a třetí kvartil a vousy, které představují maximální a minimální hodnoty.
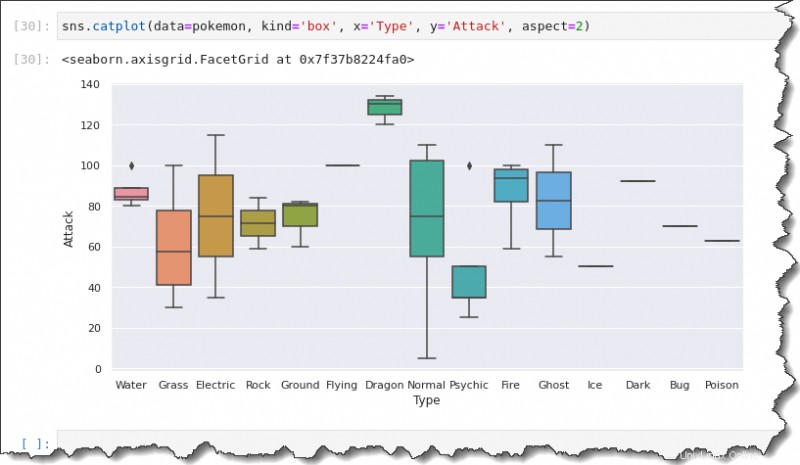
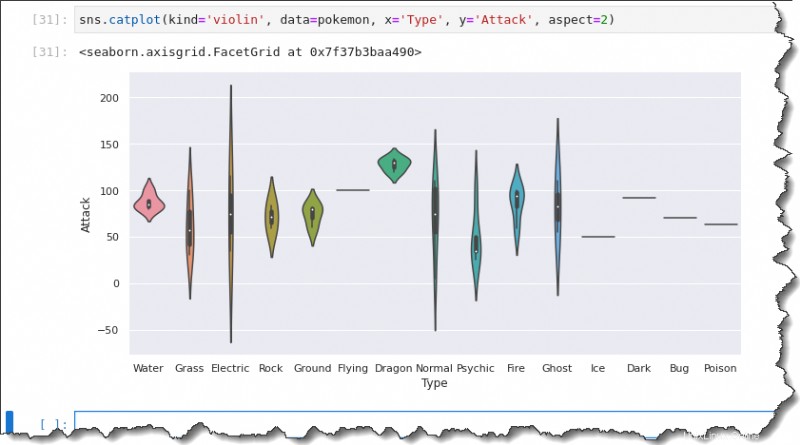
Houslové kreslení
Dalším způsobem vizualizace distribuce je použití houslového grafu. Houslová zápletka je jako krabicová zápletka a mix KDE. Houslové grafy jsou analogické s krabicovými grafy.
Chcete-li vytvořit spiknutí houslí, nahraďte kind hodnotu na violin , zatímco zbytek je stejný, jako když jste spustili příkaz k vykreslení rámečku. Spusťte níže uvedený kód a vytvořte houslový plán.
sns.catplot(kind='violin', data=pokemon, x='Type', y='Attack', aspect=2)V důsledku toho můžete vidět, že spiknutí houslí zahrnuje medián, první a třetí kvartil. Houslový graf poskytuje podobný souhrn dat rozložených jako krabicový graf.
Znovu se vraťte k otázce:Co je distribuce Attack pro každý typ Pokémona?
Krabicový graf ukazuje minimální body útoku ležící mezi 0 a 10, zatímco maximum dosahuje až 110.
Medián útočných bodů pro Pokémona normálního typu je přibližně 75. První a třetí kvartil vypadá na přibližně 55 a 105.
Sloupcové vykreslování
Sloupcový graf je členem skupiny kategorických odhadů společnosti Seaborn, která ukazuje průměrné nebo průměrné hodnoty každé kategorie dat.
Chcete-li vytvořit sloupcový graf, spusťte sns.catplot() funkce v Jupyter a zadejte šest argumentů:kind='bar' , data=pokemon , x='Type' , y='Attack' a aspect=2 , jak je uvedeno níže.
sns.catplot(kind='bar',data=pokemon,x='Type',y='Attack',aspect=2)Černé čáry na každém sloupci jsou chybové sloupce představující nejistotu, jako odlehlé hodnoty v pozorováních. Jak můžete vidět níže, střední hodnoty jsou:
- Asi 90 pro Pokémona vodního typu.
- Přibližně 60 za trávu .
- Elektrický je přibližně na 75.
- Rock možná 70.
- Země do 75.
- A tak dále.
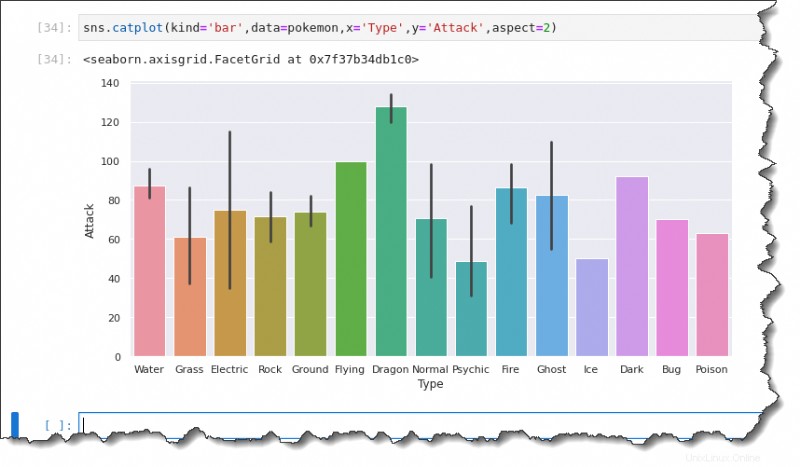
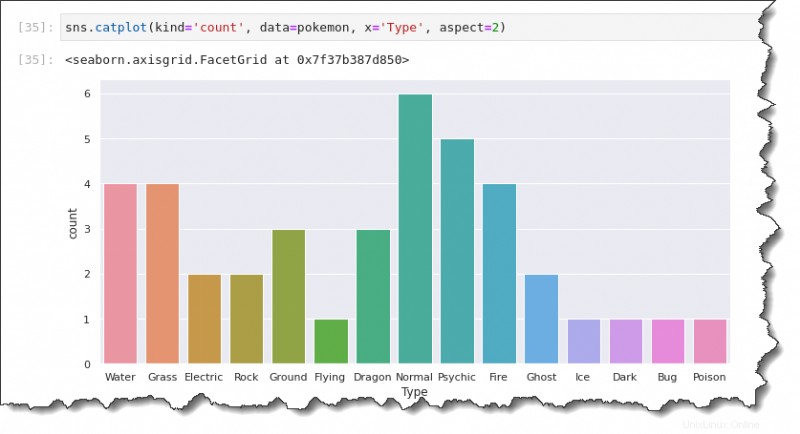
Vykreslování počtu
Co když chcete vykreslit počet Pokémonů místo průměrných/průměrných dat? Graf počtu vám to umožní s knihovnou Seaborn Python.
Chcete-li vygenerovat graf počtu, nahraďte kind hodnotu s count , jak je uvedeno v kódu níže. Na rozdíl od sloupcového grafu potřebuje graf počtu pouze jednu datovou osu. V závislosti na orientaci grafu, kterou chcete vytvořit, zadejte pouze osu x nebo y.
Níže uvedený příkaz vytvoří graf počtu zobrazující proměnnou typu na ose x.
sns.catplot(kind='count', data=pokemon, x='Type', aspect=2)Budete mít zápletku počtu, která vypadá jako ta níže. Jak můžete vidět, nejběžnější typy Pokémonů jsou:
- Normální (6).
- Psychické (5).
- Voda (4).
- Tráva (4).
- A tak dále.
Závěr
V tomto tutoriálu jste se naučili, jak programově vytvářet statistické grafy pomocí knihovny Seaborn Python. Která metoda vykreslování bude podle vás pro vaši datovou sadu nejvhodnější?
Nyní, když jste si prošli příklady a procvičili vytváření zápletek s Seaborn, proč nezačít pracovat na nových zápletkách sami. Možná můžete začít s datovou sadou Iris nebo shromáždit ukázková data?
A když už jste u toho, vyzkoušejte také některé z dalších integrovaných šablon a barevných palet Seaborn! Děkuji za přečtení a bavte se!