Úvod
Rámce pro zpracování dat, jako jsou Apache Hadoop a Spark, pohánějí vývoj velkých dat. Jejich schopnost shromažďovat obrovské množství dat z různých datových toků je neuvěřitelná, nicméně k analýze, správě a dotazování všech dat potřebují datový sklad.
Máte zájem dozvědět se více o tom, co jsou datové sklady a z čeho se skládají?
Tento článek vysvětluje architekturu datového skladu a roli každé součásti v systému.
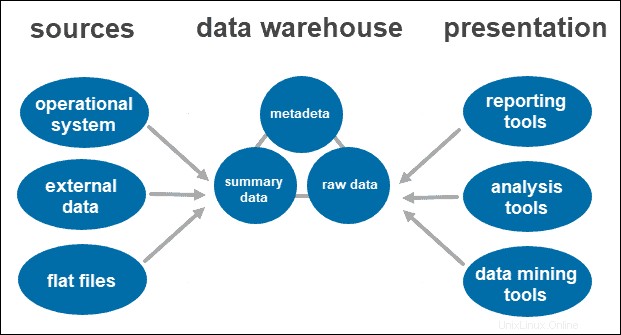
Co je to datový sklad?
Datový sklad (DW nebo DWH) je komplexní systém, který ukládá historická a kumulativní data používaná pro prognózy, reportování a analýzu dat. Zahrnuje shromažďování, čištění a transformaci dat z různých datových toků a jejich načítání do tabulek faktů/rozměrů.
Datový sklad představuje předmětově orientovanou, integrovanou, časově proměnnou a energeticky nezávislou strukturu dat.
DWH se zaměřuje spíše na předmět než na operace a integruje data z více zdrojů a dává uživateli jediný zdroj informací v konzistentním formátu. Protože je energeticky nezávislá, zaznamenává všechny změny dat jako nové položky, aniž by vymazala svůj předchozí stav. Tato funkce úzce souvisí s časovou variantou, protože uchovává záznamy o historických datech, což vám umožňuje zkoumat změny v průběhu času.
Všechny tyto vlastnosti pomáhají podnikům vytvářet analytické zprávy potřebné ke studiu změn a trendů.
Architektura datového skladu
Existují tři způsoby, jak můžete vytvořit systém datového skladu. Tyto přístupy jsou klasifikovány podle počtu vrstev v architektuře. Proto můžete mít:
- Jednovrstvá architektura
- Dvouvrstvá architektura
- Třívrstvá architektura
Jednovrstvá architektura datového skladu
Jednovrstvá architektura není často praktikovaný přístup. Hlavním cílem takové architektury je odstranit redundanci minimalizací množství uložených dat.
Jeho primární nevýhodou je, že nemá komponentu, která odděluje analytické a transakční zpracování.
Dvouvrstvá architektura datového skladu
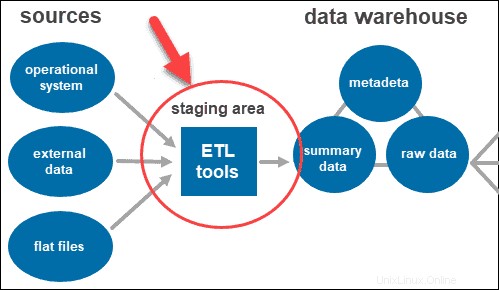
Dvouvrstvá architektura zahrnuje pracovní oblast pro všechny zdroje dat před vrstvou datového skladu. Přidáním pracovní oblasti mezi zdroje a úložiště úložiště zajistíte, že všechna data načtená do skladu budou vyčištěna a ve vhodném formátu.
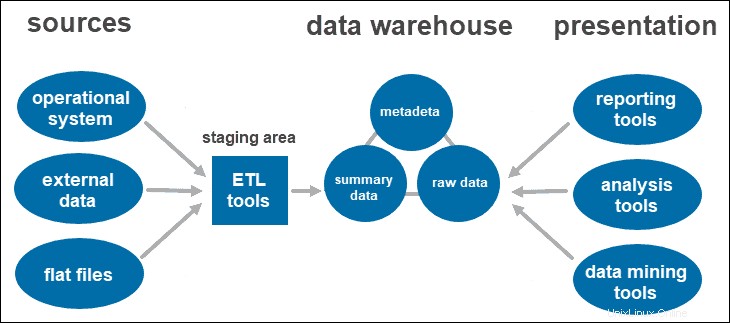
Tento přístup má určitá síťová omezení. Navíc jej nemůžete rozšířit tak, aby podporoval větší počet uživatelů.
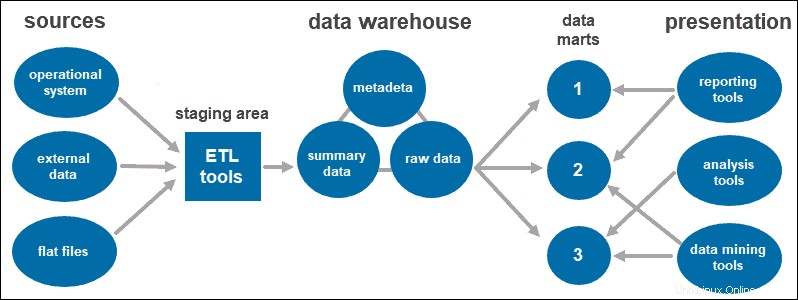
Třívrstvá architektura datového skladu
Třívrstvý přístup je nejrozšířenější architekturou pro systémy datových skladů.
V podstatě se skládá ze tří úrovní:
- Nejnižší úroveň je databáze skladu, kam se načítají vyčištěná a transformovaná data.
- Střední vrstva je aplikační vrstva poskytující abstraktní pohled na databázi. Uspořádá data tak, aby byla vhodnější pro analýzu. To se provádí pomocí serveru OLAP implementovaného pomocí modelu ROLAP nebo MOLAP.
- Nejvyšší úroveň je místo, kde uživatel přistupuje k datům a interaguje s nimi. Představuje vrstvu front-end klienta. Můžete použít nástroje pro vytváření sestav, dotazování, analýzu nebo nástroje pro dolování dat.
Komponenty datového skladu
Z výše uvedených architektur si všimnete, že se některé komponenty překrývají, zatímco jiné jsou jedinečné vzhledem k počtu úrovní.
Níže naleznete některé z nejdůležitějších součástí datového skladu a jejich role v systému.
Nástroje ETL
ETL je zkratka pro Extract , Transformovat a Načíst . Pracovní vrstva používá nástroje ETL extrahovat potřebná data z různých formátů a zkontrolovat kvalitu před jejich načtením do datového skladu.
Data pocházející z vrstvy zdroje dat mohou pocházet v různých formátech. Před sloučením všech dat shromážděných z více zdrojů do jediné databáze musí systém vyčistit a uspořádat informace.
Databáze
Nejdůležitější součástí a srdcem každé architektury je databáze. Sklad je místo, kde jsou data uložena a kde se k nim přistupuje.
Při vytváření systému datového skladu se musíte nejprve rozhodnout, jaký druh databáze chcete použít.
Existují čtyři typy databází, ze kterých si můžete vybrat:
- Relační databáze (databáze zaměřené na řádky).
- Databáze Analytics (vyvinutý pro udržení a správu analytiky).
- Aplikace datového skladu (software pro správu dat a hardware pro ukládání dat nabízený prodejci třetích stran).
- Cloudové databáze (hostované v cloudu).
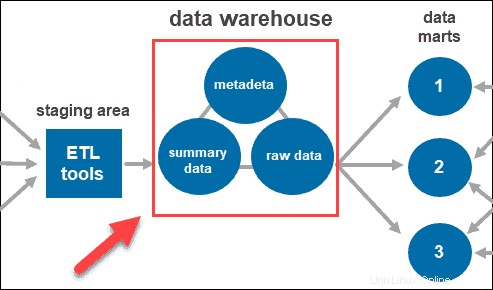
Data
Jakmile systém data vyčistí a uspořádá, uloží je do datového skladu. Datový sklad představuje centrální úložiště, které uchovává metadata, souhrnná data a nezpracovaná data pocházející z každého zdroje.
- Metadata jsou informace, které definují data. Jeho primární úlohou je zjednodušit práci s datovými instancemi. Umožňuje datovým analytikům klasifikovat, lokalizovat a směřovat dotazy na požadovaná data.
- Souhrnná data generuje vedoucí skladu. Aktualizuje se při načítání nových dat do skladu. Tato složka může obsahovat málo nebo vysoce sumarizovaná data. Jeho hlavní úlohou je urychlit výkon dotazů.
- Nezpracovaná data je skutečné načtení dat do úložiště, která nebyla zpracována. Data v nezpracované podobě je zpřístupní pro další zpracování a analýzu.
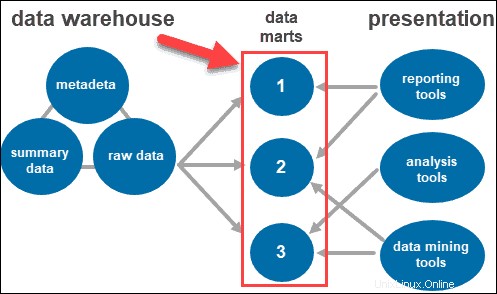
Přístup k nástrojům
Uživatelé interagují se shromážděnými informacemi prostřednictvím různých nástrojů a technologií. Mohou analyzovat data, shromažďovat poznatky a vytvářet zprávy.
Některé z používaných nástrojů zahrnují:
- Nástroje pro vytváření přehledů. Hrají klíčovou roli v pochopení toho, jak si vaše firma vede a co by se mělo dělat dál. Nástroje pro vytváření přehledů zahrnují vizualizace, jako jsou grafy a grafy, které ukazují, jak se data mění v průběhu času.
- Nástroje OLAP. Online nástroje pro analytické zpracování, které uživatelům umožňují analyzovat vícerozměrná data z různých perspektiv. Tyto nástroje poskytují rychlé zpracování a cennou analýzu. Extrahují data z mnoha relačních datových sad a reorganizují je do vícerozměrného formátu.
- Nástroje pro dolování dat. Prozkoumejte datové sady a najděte vzory ve skladu a korelaci mezi nimi. Dolování dat také pomáhá vytvářet vztahy při analýze vícerozměrných dat.
Datové trhy
Datové tržiště vám umožňují mít v systému více skupin rozdělením dat ve skladu do kategorií. Rozděluje data a vytváří je pro konkrétní skupinu uživatelů.
Datové tržiště můžete například použít ke kategorizaci informací podle oddělení v rámci společnosti.
Osvědčené postupy pro datový sklad
Návrh datového skladu závisí na pochopení obchodní logiky vašeho individuálního případu použití.
Požadavky se liší, ale existují osvědčené postupy pro datový sklad, které byste měli dodržovat:
- Vytvořte datový model. Začněte identifikací obchodní logiky organizace. Pochopte, jaká data jsou pro organizaci životně důležitá a jak budou procházet datovým skladem.
- Rozhodněte se pro dobře známý standard architektury datového skladu. Datový model poskytuje rámec a sadu osvědčených postupů, které je třeba dodržovat při navrhování architektury nebo odstraňování problémů. Mezi oblíbené standardy architektury patří 3NF, modelování datového trezoru a hvězdové schéma.
- Vytvořte diagram toku dat. Dokumentujte, jak data procházejí systémem. Zjistěte, jak to souvisí s vašimi požadavky a obchodní logikou.
- Mějte jeden zdroj pravdy. Když organizace pracuje s tolika daty, musí mít jediný zdroj pravdy. Konsolidujte data do jednoho úložiště.
- Používejte automatizaci. Automatizační nástroje pomáhají při práci s obrovským množstvím dat.
- Povolit sdílení metadat. Navrhněte architekturu, která usnadňuje sdílení metadat mezi komponentami datového skladu.
- Prosazování standardů kódování. Normy kódování zajišťují efektivitu systému.