Úvod
HDFS (Hadoop Distributed File System) je důležitou součástí projektu Apache Hadoop. Hadoop je ekosystém softwaru, který spolupracuje, aby vám pomohl spravovat velká data. Dva hlavní prvky Hadoopu jsou:
- MapReduce – odpovědný za provádění úkolů
- HDFS – odpovědný za údržbu dat
V tomto článku budeme hovořit o druhém ze dvou modulů. Budete se naučit Co je HDFS, jak funguje a základní terminologie HDFS .

Co je HDFS?
Hadoop Distributed File System je systém souborů úložiště dat odolný proti chybám, který běží na komoditním hardwaru. Byl navržen tak, aby překonal výzvy, které tradiční databáze nedokázaly. Proto je jeho plný potenciál využit pouze při zpracování velkých dat.
Hlavní problémy, které musel souborový systém Hadoop vyřešit, byly rychlost , náklady a spolehlivost .
Jaké jsou výhody HDFS?
Výhody HDFS jsou ve skutečnosti řešení, která souborový systém poskytuje pro dříve zmíněné výzvy:
- Je to rychlé. Díky své clusterové architektuře dokáže dodat více než 2 GB dat za sekundu.
- Je to zdarma. HDFS je software s otevřeným zdrojovým kódem, který je dodáván bez poplatků za licence nebo podporu.
- Je spolehlivý. Systém souborů ukládá více kopií dat v samostatných systémech, aby bylo zajištěno, že budou vždy přístupné.
Tyto výhody jsou zvláště významné při práci s velkými daty a byly umožněny zvláštním způsobem, jakým HDFS zpracovává data.
Jak HDFS ukládá data?
HDFS rozděluje soubory do bloků a každý blok ukládá na DataNode. K hlavnímu uzlu v clusteru, NameNode, je připojeno více datových uzlů. Hlavní uzel distribuuje repliky těchto datových bloků napříč clusterem. Také dává uživateli pokyn, kde najít požadované informace.
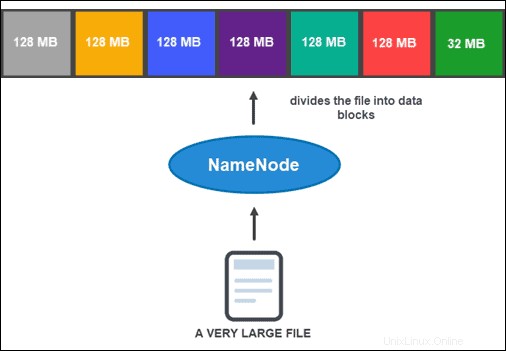
Než vám však NameNode může pomoci ukládat a spravovat data, musí nejprve rozdělit soubor na menší, spravovatelné datové bloky. Tento proces se nazývá rozdělení datových bloků .
Rozdělení datových bloků
Ve výchozím nastavení nemůže být blok větší než 128 MB. Počet bloků závisí na počáteční velikosti souboru. Všechny kromě posledního bloku mají stejnou velikost (128 MB), zatímco poslední je to, co zbývá ze souboru.
Například soubor o velikosti 800 MB je rozdělen do sedmi datových bloků. Šest ze sedmi bloků má 128 MB, zatímco sedmý datový blok má zbývajících 32 MB.
Poté je každý blok replikován do několika kopií.
Replikace dat
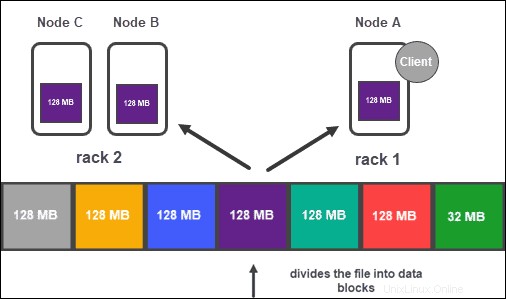
Na základě konfigurace clusteru vytvoří NameNode určitý počet kopií každého datového bloku pomocí metody replikace .
Doporučuje se mít alespoň tři repliky, což je také výchozí nastavení. Hlavní uzel je ukládá do samostatných datových uzlů clusteru. Stav uzlů je pečlivě sledován, aby byla data vždy dostupná.
Aby byla zajištěna vysoká dostupnost, spolehlivost a odolnost proti chybám, vývojáři doporučují nastavit tři repliky pomocí následující topologie:
- Uložte první repliku na uzlu, kde se klient nachází.
- Potom uložte druhou repliku na jiném stojanu.
- Nakonec uložte třetí repliku na stejném stojanu jako druhá replika, ale na jiném uzlu.
Architektura HDFS:NameNodes a DataNodes
HDFS má architekturu master-slave. Hlavní uzel je NameNode , která spravuje více podřízených uzlů v rámci clusteru, známých jako DataNodes .
NameNodes
Hadoop 2.x představil možnost mít více NameNodes na rack. Tato novinka byla poměrně významná, protože jediný hlavní uzel se všemi informacemi v clusteru představoval velkou zranitelnost.
Obvyklý cluster se skládá ze dvou NameNodes:
- aktivní NameNode
- a pohotovostní NameNode
Zatímco první se zabývá všemi klientskými operacemi v rámci clusteru, druhý udržuje synchronizaci s veškerou svou prací, pokud je potřeba převzetí služeb při selhání.
Aktivní NameNode sleduje metadata každého datového bloku a jeho replik. To zahrnuje název souboru, oprávnění, ID, umístění a počet replik. Všechny informace uchovává v fsnímku , obraz jmenného prostoru uložený v místní paměti systému souborů. Kromě toho spravuje protokoly transakcí s názvem EditLogs , které zaznamenávají všechny změny provedené v systému.
Hlavním účelem Stanby NameNode je vyřešit problém jediného bodu selhání. Přečte všechny změny provedené v EditLogs a aplikuje je na svůj NameSpace (soubory a adresáře v datech). Pokud hlavní uzel selže, služba Zookeeper provede převzetí služeb při selhání a umožní pohotovostnímu režimu udržovat aktivní relaci.
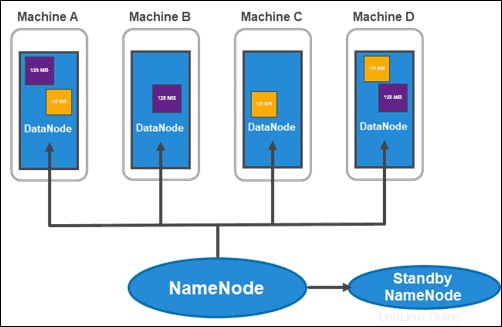
Datové uzly
DataNodes jsou slave démoni, kteří ukládají datové bloky přiřazené NameNode. Jak bylo uvedeno výše, výchozí nastavení zajišťuje, že každý datový blok má tři repliky. Počet replik můžete změnit, ale není vhodné jít pod tři.
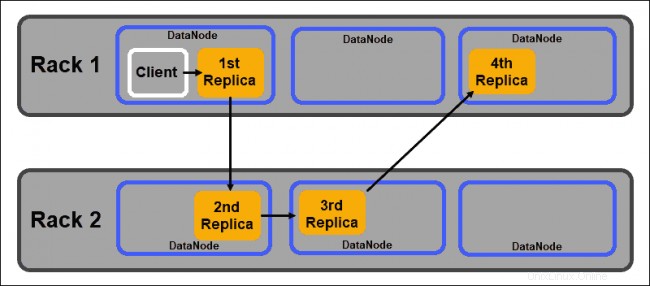
Repliky by měly být distribuovány v souladu s Rack Awareness společnosti Hadoop zásadu, která uvádí, že:
- Počet replik musí být větší než počet stojanů.
- Jeden DataNode může uložit pouze jednu repliku datového bloku.
- Jeden stojan nemůže uložit více než dvě repliky datového bloku.
Dodržováním těchto pokynů můžete:
- Maximalizujte šířku pásma sítě.
- Chraňte před ztrátou dat.
- Zlepšete výkon a spolehlivost.
Klíčové vlastnosti HDFS
Toto jsou hlavní charakteristiky distribuovaného systému souborů Hadoop:
1. Spravuje velká data. HDFS je vynikající při práci s velkými datovými sadami a poskytuje řešení, které tradiční souborové systémy nedokázaly. Dělá to segregací dat do spravovatelných bloků, které umožňují rychlé zpracování.
2. Rack-aware. Řídí se pokyny pro povědomí o stojanech, což zajišťuje, že systém je vysoce dostupný a efektivní.
3. Tolerantní k chybám. Protože jsou data uložena ve více stojanech a uzlech, dochází k jejich replikaci. To znamená, že pokud některý z počítačů v clusteru selže, replika těchto dat bude dostupná z jiného uzlu.
4. Škálovatelné. Prostředky můžete škálovat podle velikosti vašeho systému souborů. HDFS zahrnuje mechanismy vertikální a horizontální škálovatelnosti.
Využití HDFS v reálném životě
Společnosti, které se zabývají velkými objemy dat, již dlouho začaly migrovat na Hadoop, jedno z předních řešení pro zpracování velkých dat, a to kvůli jeho úložným a analytickým schopnostem.
Finanční služby. Hadoop Distributed File System je navržen tak, aby podporoval data, u kterých se očekává exponenciální růst. Systém je škálovatelný bez nebezpečí zpomalení složitého zpracování dat.
Maloobchod. Protože znalost vašich zákazníků je kritickou součástí úspěchu v maloobchodním průmyslu, mnoho společností uchovává velké množství strukturovaných a nestrukturovaných zákaznických dat. Používají Hadoop ke sledování a analýze shromážděných dat, aby jim pomohli plánovat budoucí inventář, ceny, marketingové kampaně a další projekty.
Telekomunikace. Telekomunikační průmysl spravuje obrovské množství dat a musí je zpracovávat v rozsahu petabajtů. Využívá analýzu Hadoop ke správě záznamů dat hovorů, analýzy síťového provozu a dalších procesů souvisejících s telekomunikacemi.
Energetický průmysl. Energetický průmysl neustále hledá způsoby, jak zlepšit energetickou účinnost. Spoléhá na systémy jako Hadoop a jeho souborový systém, který pomáhá analyzovat a porozumět vzorcům a praktikám spotřeby.
Pojištění. Zdravotní pojišťovny jsou závislé na analýze dat. Tyto výsledky slouží jako základ pro to, jak formulují a zavádějí politiky. Pro pojišťovny je náhled do klientské historie neocenitelný. Schopnost udržovat snadno dostupnou databázi při neustálém růstu je důvodem, proč se tolik lidí obrátilo na Apache Hadoop.