Tesseract je jedním z nejvýkonnějších open source OCR enginů, které jsou dnes k dispozici. OCR je zkratka pro optické rozpoznávání znaků. Jedná se o proces extrahování textů z obrázků. Vezměme si například následující obrázek, který obsahuje nějaký text, který je třeba extrahovat:

Výstup z enginu OCR bude po provedení nějakého zpracování vypadat nějak takto:
Open Access Button
Takto funguje OCR. Je užitečný v mnoha aplikacích, jako je rozpoznávání SPZ vozidla, převod naskenovaných kopií dokumentů do formátu Word, automatické vyjímání podrobností z účtenek atd. Tvoří také první krok v mnoha úlohách zpracování přirozeného jazyka. V tomto tutoriálu se podíváme na to, jak rychle nainstalovat a nastavit Tesseract, imagemagick a jak je používat k dosažení nejlepších možných výsledků s předzpracováním obrázků.
Předzpracování obrazu je důležitou součástí provádění OCR pomocí Tesseract. To zajišťuje vysokou přesnost extrahovaného textu a snižuje chyby. Projdeme si některé základní operace, které s obrázkem pomocí něj provedeme. Imagemagick je nástroj pro zpracování obrazu založený na příkazovém řádku, který nám pomáhá provádět operace, jako je oříznutí, změna velikosti, změna barevných schémat atd.
1 Nainstalujte Tesseract
Instalace tesseractu je velmi jednoduchá, spusťte následující příkazy:
sudo apt update sudo apt install tesseract-ocr
Tím se nainstaluje stroj Tesseract. Obrázek níže ukazuje výstup, když je správně nainstalován:
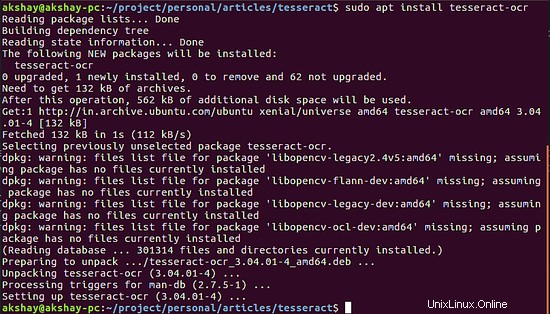
Další věcí, kterou musíte udělat, je nainstalovat jazykové balíčky. Tesseract je velmi robustní a dokáže extrahovat více než 100 různých jazyků za předpokladu, že jsou staženy jazykové balíčky. Konkrétní jazykový balíček si můžete stáhnout pomocí obecného příkazu níže:
sudo apt-get install tesseract-ocr-[lang]
Ve výše uvedeném příkazu nahraďte „[lang]“ jazykem, který chcete stáhnout. Příklady angličtiny a francouzštiny jsou uvedeny níže:
sudo apt-get install tesseract-ocr-eng sudo apt-get install tesseract-ocr-fra
Obvykle je tesseract standardně dodáván s anglickým balíčkem. Obrázek níže ukazuje, že angličtina již byla nainstalována a francouzština musela být stažena a nainstalována:
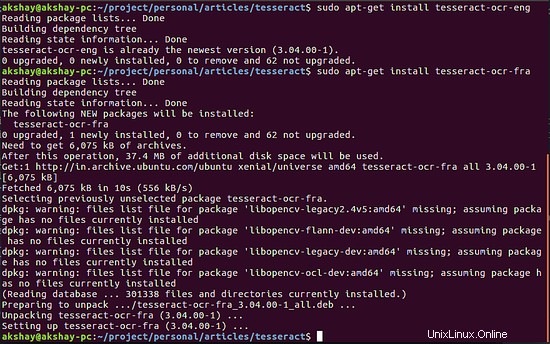
Případně, pokud chcete, aby byly staženy všechny jazykové balíčky, můžete spustit následující příkaz:
sudo apt-get install tesseract-ocr-all
Tím je instalace Tesseractu dokončena.
2 Instalace Imagemagick Spuštěním následujícího příkazu nainstalujte imagemagick
sudo apt install imagemagick
Tento nástroj se používá z příkazového řádku pomocí příkazu convert. Chcete-li zkontrolovat správnou instalaci, spusťte následující příkaz a výstup by měl být podobný obrázku níže:
convert -h
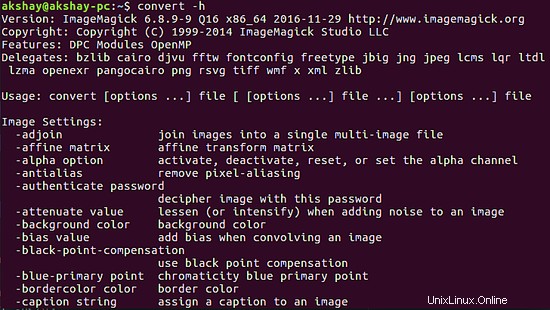
3 využití Tesseract
Tesseract je schopen pořizovat obrázky mnoha různých formátů, jako je jpg, png, tiff atd., a extrahovat z nich text. Tato část se zaměřuje na spuštění tesseractu a v další části uvidíme, jak můžeme zlepšit přesnost. Zde je několik základních příkazů pro spuštění tesseract:
Chcete-li získat výstup v terminálu, spusťte obecný příkaz s cestou k obrázku
tesseract [cesta k obrázku] stdout
Chcete-li uložit výstup OCR do souboru, spusťte následující obecný příkaz:
tesseract [image_path] [file_name]
Po dvou obrázcích ukažte použitý obrázek a výstup spouštění výše uvedených příkazů na tomto obrázku

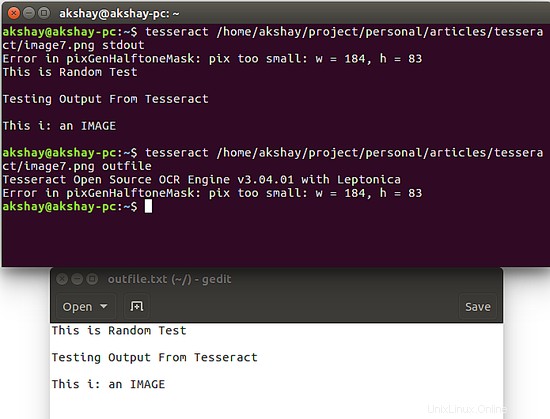
Jak můžete pozorovat, spuštění druhého příkazu vedlo k vytvoření souboru s názvem "outfile.txt", ve kterém lze nalézt výstup.
4 Předzpracování obrázku
Z předchozího výstupu jste si mohli všimnout, že ve výstupu je chyba a také chyba, že velikost pixelů je malá. To je jedna z nevýhod Tesseractu, očekává, že poskytnete zpracovaný obrázek, na kterém může provádět OCR. V této části si projdeme některé taktiky, které můžete použít s pomocí imagemagick ke zlepšení kvality obrazu a tím i ke zvýšení přesnosti výstupu.
4.1 změna velikosti
Změna velikosti je jedním z nejužitečnějších triků pro zlepšení přesnosti OCR. Je to proto, že obrázky mají většinou velmi malou velikost písma, které nemůže Tesseract správně přečíst. Velikost obrázku můžete změnit pomocí následujícího příkazu. Procentuální částka označuje limit změny velikosti. Protože chceme zvětšit velikost, musíme zadat hodnotu větší než 100. Zde jsme dali hodnotu 150 % (použijte metodu pokusu a omylu k určení dokonalého procenta změny velikosti pro váš případ použití).
convert -resize 150% [input_file_path] [output_file_path]
ve výše uvedeném příkazu nahraďte [cesta_vstupního_souboru] cestou k obrázku, jehož velikost má být změněna, a [cesta_výstupního_souboru] cestou k obrázku, kam má být výstup uložen. Následující obrázek je výstupem při spuštění příkazu:convert -resize 150% image7.png image7_resize.png
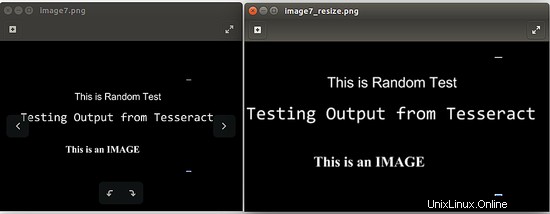
4.2 Použití obrázků ve stupních šedi
Pokud máte barevný obrázek, doporučujeme jej nejprve převést na stupně šedi. Je velká šance, že právě toto bude stačit k dosažení požadované přesnosti OCR. V opačném případě můžete pro další zpracování použít obrázky ve stupních šedi k binarizaci obrázku. Pomocí následujícího příkazu převeďte obrázek do odstínů šedi
convert [input_file_path] -type Grayscale [output_file_path]
Následující obrázek ukazuje výstup pro spuštění příkazu convert image6_resize.png -type Grayscale image6_gray.png
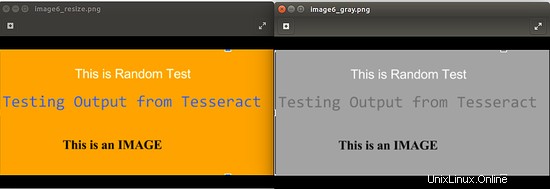
4.3 Binarizace obrázku
Binarizace neboli prahování zahrnuje převod obrazu pouze na hodnoty černé a bílé. Každý pixel na tomto obrázku má pouze jednu ze dvou hodnot, buď černou nebo bílou. To drasticky snižuje složitost obrázků. Pokud máte obrázky se šumem nebo obrázky se stíny nebo velkým množstvím textu, můžete použít tuto metodu předběžného zpracování. Chcete-li tento obrázek binarizovat, ujistěte se, že máte nejprve obrázek ve stupních šedi, a poté použijte následující příkaz:
convert [input_file_path] -threshold 55% [output_file_path]
Prahová hodnota % se může měnit, abyste dosáhli nejlepšího výsledku pro váš případ použití. Obrázek níže ukazuje příklad. Je důležité poznamenat, že pro daný obrázek není binarizace tou nejlepší možností, protože dochází ke ztrátě některých dat.
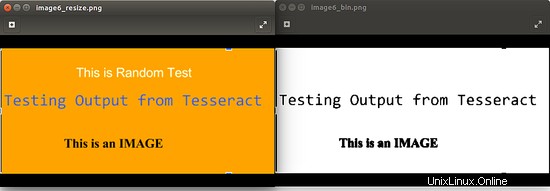
Před použitím některé nebo všech výše uvedených technik předběžného zpracování je třeba mít na paměti následující body:
- V závislosti na případu použití bude užitečný jeden z kroků předběžného zpracování nebo jejich kombinace.
- když krok předběžného zpracování vede ke snížení přesnosti, měl by být z kroků předběžného zpracování ignorován.
- Procenta při změně velikosti nebo prahování se liší obrázek od obrázku, a proto je třeba použít metodu pokusu a omylu, abyste získali nejlepší možnou procentuální hodnotu, která poskytne nejvyšší přesnost při spuštění Tesseract
Jakmile dokončíte předběžné zpracování, spusťte Tesseract se zpracovaným obrázkem a zkontrolujte přesnost. Tesseract je velmi výkonný, ale má určitá omezení, pokud jde o typ obrázku, který je zadán jako vstup. Doufám, že vám tento návod pomohl.