Hadoop je bezplatný softwarový framework s otevřeným zdrojovým kódem a založený na Javě, který se používá pro ukládání a zpracování velkých datových sad na klastrech strojů. Používá HDFS k ukládání svých dat a zpracování těchto dat pomocí MapReduce. Jedná se o ekosystém nástrojů Big Data, které se primárně používají pro dolování dat a strojové učení.
Apache Hadoop 3.3 přichází se znatelnými vylepšeními a mnoha opravami chyb oproti předchozím verzím. Má čtyři hlavní komponenty, jako jsou Hadoop Common, HDFS, YARN a MapReduce.
Tento tutoriál vám vysvětlí, jak nainstalovat a nakonfigurovat Apache Hadoop na systému Ubuntu 20.04 LTS Linux.
Krok 1 – Instalace Java
Hadoop je napsán v Javě a podporuje pouze Javu verze 8. Hadoop verze 3.3 a nejnovější také podporují běhové prostředí Java 11 a také Javu 8.
OpenJDK 11 můžete nainstalovat z výchozích repozitářů apt:
sudo apt updatesudo apt install openjdk-11-jdk
Po instalaci ověřte nainstalovanou verzi Java pomocí následujícího příkazu:
java -version
Měli byste získat následující výstup:
openjdk version "11.0.11" 2021-04-20 OpenJDK Runtime Environment (build 11.0.11+9-Ubuntu-0ubuntu2.20.04) OpenJDK 64-Bit Server VM (build 11.0.11+9-Ubuntu-0ubuntu2.20.04, mixed mode, sharing)
Krok 2 – Vytvoření uživatele Hadoop
Z bezpečnostních důvodů je dobré vytvořit samostatného uživatele pro spuštění Hadoopu.
Spusťte následující příkaz k vytvoření nového uživatele s názvem hadoop:
sudo adduser hadoop
Zadejte a potvrďte nové heslo, jak je uvedeno níže:
Adding user `hadoop' ...
Adding new group `hadoop' (1002) ...
Adding new user `hadoop' (1002) with group `hadoop' ...
Creating home directory `/home/hadoop' ...
Copying files from `/etc/skel' ...
New password:
Retype new password:
passwd: password updated successfully
Changing the user information for hadoop
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] y
Krok 3 – Konfigurace ověřování pomocí klíče SSH
Dále budete muset nakonfigurovat ověřování SSH bez hesla pro místní systém.
Nejprve změňte uživatele na hadoop pomocí následujícího příkazu:
su - hadoop
Dále spusťte následující příkaz pro vygenerování párů veřejného a soukromého klíče:
ssh-keygen -t rsa
Budete požádáni o zadání názvu souboru. Pro dokončení procesu stačí stisknout Enter:
Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub The key fingerprint is: SHA256:QSa2syeISwP0hD+UXxxi0j9MSOrjKDGIbkfbM3ejyIk [email protected] The key's randomart image is: +---[RSA 3072]----+ | ..o++=.+ | |..oo++.O | |. oo. B . | |o..+ o * . | |= ++o o S | |.++o+ o | |.+.+ + . o | |o . o * o . | | E + . | +----[SHA256]-----+
Dále připojte vygenerované veřejné klíče z id_rsa.pub k author_keys a nastavte správná oprávnění:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 640 ~/.ssh/authorized_keys
Dále ověřte ověření SSH bez hesla pomocí následujícího příkazu:
ssh localhost
Budete požádáni o ověření hostitelů přidáním klíčů RSA ke známým hostitelům. Napište yes a stiskněte Enter pro ověření localhost:
The authenticity of host 'localhost (127.0.0.1)' can't be established. ECDSA key fingerprint is SHA256:JFqDVbM3zTPhUPgD5oMJ4ClviH6tzIRZ2GD3BdNqGMQ. Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Krok 4 – Instalace Hadoop
Nejprve změňte uživatele na hadoop pomocí následujícího příkazu:
su - hadoop
Dále si stáhněte nejnovější verzi Hadoop pomocí příkazu wget:
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
Po stažení stažený soubor rozbalte:
tar -xvzf hadoop-3.3.0.tar.gz
Dále přejmenujte extrahovaný adresář na hadoop:
mv hadoop-3.3.0 hadoop
Dále budete muset ve vašem systému nakonfigurovat proměnné prostředí Hadoop a Java.
Otevřete soubor ~/.bashrc soubor ve vašem oblíbeném textovém editoru:
nano ~/.bashrc
Připojte níže uvedené řádky k souboru. Umístění JAVA_HOME můžete najít spuštěním dirname $(dirname $(readlink -f $(which java))) command on terminal.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Save and close the file. Then, activate the environment variables with the following command:
source ~/.bashrc
Dále otevřete soubor proměnných prostředí Hadoop:
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Znovu nastavte JAVA_HOME v hadoop prostředí.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
Po dokončení uložte a zavřete soubor.
Krok 5 – Konfigurace Hadoop
Nejprve budete muset vytvořit adresáře namenode a datanode v domovském adresáři Hadoop:
Spuštěním následujícího příkazu vytvořte oba adresáře:
mkdir -p ~/hadoopdata/hdfs/namenodemkdir -p ~/hadoopdata/hdfs/datanode
Dále upravte core-site.xml soubor a aktualizujte pomocí názvu hostitele vašeho systému:
nano $HADOOP_HOME/etc/hadoop/core-site.xml
Změňte následující název podle názvu hostitele vašeho systému:
XHTML
| 123456 |
Uložte a zavřete soubor. Poté upravte hdfs-site.xml soubor:
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Změňte cestu k adresáři NameNode a DataNode, jak je znázorněno níže:
XHTML
| 1234567891011121314151617 |
Uložte a zavřete soubor. Poté upravte mapred-site.xml soubor:
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Proveďte následující změny:
XHTML
| 123456 |
Uložte a zavřete soubor. Poté upravte yarn-site.xml soubor:
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Proveďte následující změny:
XHTML
| 123456 |
Po dokončení uložte a zavřete soubor.
Krok 6 – Spusťte Hadoop Cluster
Před spuštěním clusteru Hadoop. Budete muset naformátovat Namenode jako uživatel hadoop.
Spusťte následující příkaz pro formátování hadoop Namenode:
hdfs namenode -format
Měli byste získat následující výstup:
2020-11-23 10:31:51,318 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2020-11-23 10:31:51,323 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown. 2020-11-23 10:31:51,323 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop.tecadmin.net/127.0.1.1 ************************************************************/
Po naformátování Namenode spusťte následující příkaz pro spuštění clusteru hadoop:
start-dfs.sh
Po úspěšném spuštění HDFS byste měli získat následující výstup:
Starting namenodes on [hadoop.tecadmin.com] hadoop.tecadmin.com: Warning: Permanently added 'hadoop.tecadmin.com,fe80::200:2dff:fe3a:26ca%eth0' (ECDSA) to the list of known hosts. Starting datanodes Starting secondary namenodes [hadoop.tecadmin.com]
Dále spusťte službu YARN, jak je znázorněno níže:
start-yarn.sh
Měli byste získat následující výstup:
Starting resourcemanager Starting nodemanagers
Nyní můžete zkontrolovat stav všech služeb Hadoop pomocí příkazu jps:
jps
V následujícím výstupu byste měli vidět všechny běžící služby:
18194 NameNode 18822 NodeManager 17911 SecondaryNameNode 17720 DataNode 18669 ResourceManager 19151 Jps
Krok 7 – Úprava brány firewall
Hadoop je nyní spuštěn a naslouchá na portech 9870 a 8088. Dále budete muset povolit tyto porty přes firewall.
Spusťte následující příkaz a povolte připojení Hadoop přes bránu firewall:
firewall-cmd --permanent --add-port=9870/tcpfirewall-cmd --permanent --add-port=8088/tcp
Poté znovu načtěte službu firewall, aby se změny projevily:
firewall-cmd --reload
Krok 8 – Přístup k Hadoop Namenode a Resource Manager
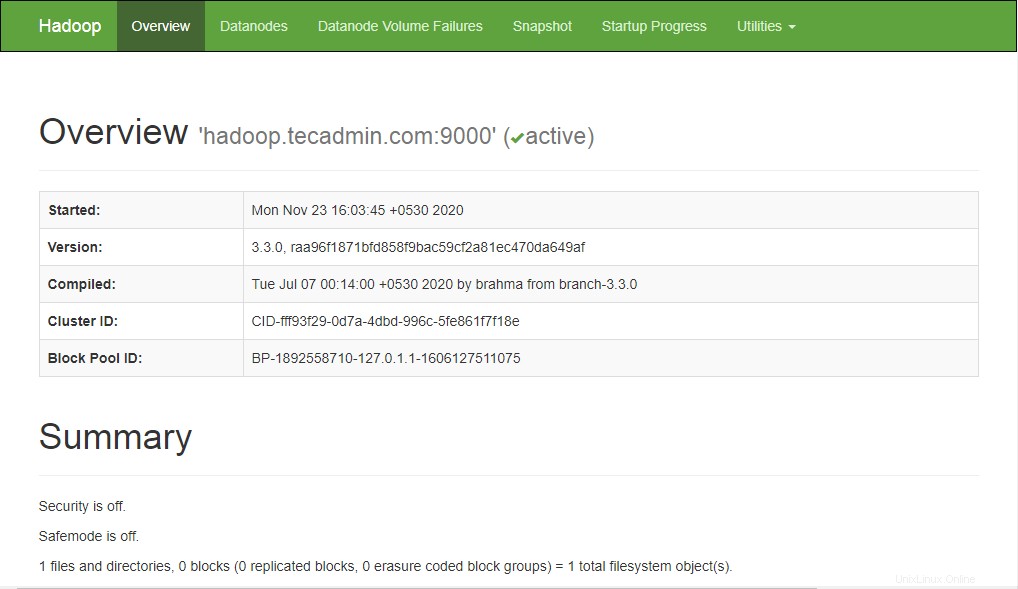
Chcete-li získat přístup k Namenode, otevřete webový prohlížeč a navštivte adresu URL http://ip-ip:9870. Měli byste vidět následující obrazovku:
http://hadoop.tecadmin.net:9870
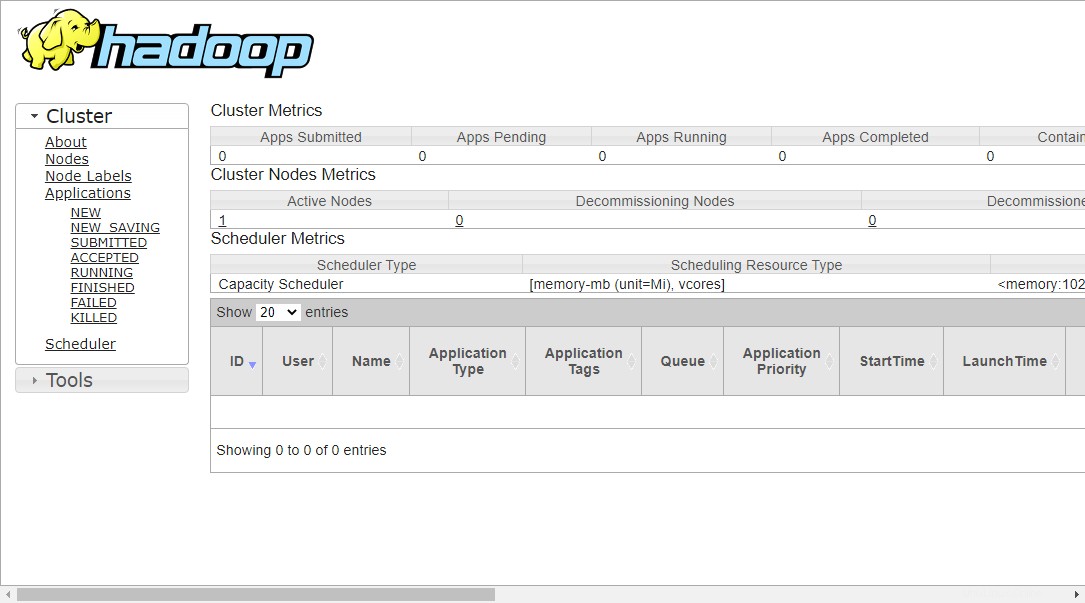
Chcete-li získat přístup ke správě zdrojů, otevřete webový prohlížeč a navštivte adresu URL http://ip-ip-vašeho-serveru:8088. Měli byste vidět následující obrazovku:
http://hadoop.tecadmin.net:8088
Krok 9 – Ověřte klastr Hadoop
V tomto okamžiku je cluster Hadoop nainstalován a nakonfigurován. Dále vytvoříme některé adresáře v souborovém systému HDFS, abychom otestovali Hadoop.
Vytvořme nějaký adresář v systému souborů HDFS pomocí následujícího příkazu:
hdfs dfs -mkdir /test1hdfs dfs -mkdir /logs
Dále spusťte následující příkaz pro zobrazení výše uvedeného adresáře:
hdfs dfs -ls /
Měli byste získat následující výstup:
Found 3 items drwxr-xr-x - hadoop supergroup 0 2020-11-23 10:56 /logs drwxr-xr-x - hadoop supergroup 0 2020-11-23 10:51 /test1
Také vložte některé soubory do systému souborů hadoop. Například umístění souborů protokolu z hostitelského počítače do systému souborů hadoop.
hdfs dfs -put /var/log/* /logs/
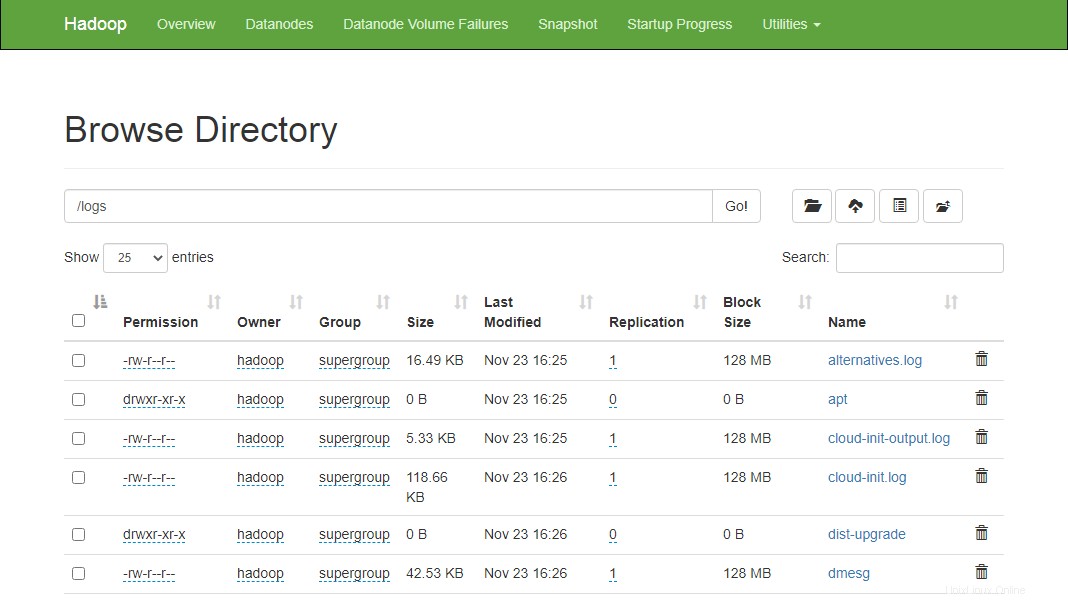
Výše uvedené soubory a adresář můžete také ověřit ve webovém rozhraní Hadoop Namenode.
Přejděte do webového rozhraní Namenode, klikněte na Utilities => Browse the file system. Na následující obrazovce byste měli vidět své adresáře, které jste vytvořili dříve:
http://hadoop.tecadmin.net:9870/explorer.html
Krok 10 – Zastavení clusteru Hadoop
Službu Hadoop Namenode and Yarn můžete také kdykoli zastavit spuštěním stop-dfs.sh a stop-yarn.sh skript jako uživatel Hadoop.
Chcete-li zastavit službu Hadoop Namenode, spusťte následující příkaz jako uživatel hadoop:
stop-dfs.sh
Chcete-li zastavit službu Hadoop Resource Manager, spusťte následující příkaz:
stop-yarn.sh
Závěr
Tento tutoriál vám vysvětlil krok za krokem tutoriál pro instalaci a konfiguraci Hadoop na systému Ubuntu 20.04 Linux.