Úvod
Apache Spark je open-source distribuovaný výpočetní rámec, který je_vytvořen tak, aby poskytoval rychlejší výpočetní výsledky.
Jedná se o in-memory výpočetní engine, což znamená, že data budou zpracována v paměti.
Spark podporuje různá API pro streamování, zpracování grafů, SQL, MLLib. Podporuje také Javu, Python, Scala a R jako preferované jazyky. Spark je většinou instalován v clusterech Hadoop, ale můžete také nainstalovat a nakonfigurovat spark v samostatném režimu.
V tomto článku se podíváme na to, jak nainstalovat Apache Spark v Debianu a Ubuntu -založené distribuce.
Nainstalujte Javu v Ubuntu
Chcete-li nainstalovat Apache Spark v Ubuntu musíte mít Java nainstalovaný na vašem počítači. Většina moderních distribucí se dodává s nainstalovanou Javou ve výchozím nastavení a můžete to ověřit pomocí následujícího příkazu.
$ java -version
Pokud žádný výstup, můžete nainstalovat Javu pomocí našeho článku o tom, jak nainstalovat Javu na Ubuntu, nebo jednoduše spustit následující příkazy a nainstalovat Javu na Ubuntu a distribuce založené na Debianu.
$ sudo apt update
$ sudo apt install default-jre
$ java -versionNainstalujte Scala v Ubuntu
Dále můžete nainstalovat Scala z úložiště apt spuštěním následujících příkazů pro vyhledání scala a jeho instalaci.
Vyhledejte balíček
$ sudo apt search scalaNainstalujte balíček
$ sudo apt install scala -yChcete-li ověřit instalaci Scala , spusťte následující příkaz.
$ scala -version 
Nainstalujte Apache Spark v Ubuntu
Nyní přejděte na oficiální stránku stahování Apache Spark a stáhněte si nejnovější verzi (tj. 3.1.2) v době psaní tohoto článku. Případně můžete použít příkaz wget ke stažení souboru přímo v terminálu.
$ wget https://apachemirror.wuchna.com/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Nyní otevřete svůj terminál a přepněte se na místo, kde je umístěn váš stažený soubor, a spusťte následující příkaz pro extrahování souboru tar Apache Spark.
$ tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz 
Nakonec přesuňte extrahovanou Spark do adresáře /opt adresář.
sudo mv spark-3.1.2-bin-hadoop3.2 /opt/sparkKonfigurace proměnných pro Spark
Nyní musíte ve svém .profile nastavit několik proměnných prostředí soubor před spuštěním jiskry.
$ echo "export SPARK_HOME=/opt/spark" >> ~/.profile
$ echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile
$ echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profileAbyste se ujistili, že tyto nové proměnné prostředí jsou dosažitelné v rámci prostředí a dostupné pro Apache Spark, je také povinné spustit následující příkaz, aby se poslední změny projevily.
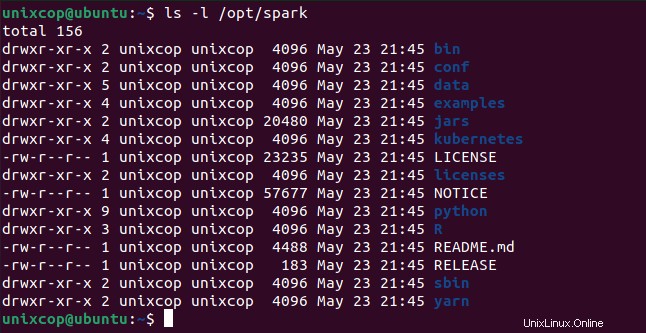
$ source ~/.profileVšechny binární soubory související s jiskrami pro spuštění a zastavení služeb jsou pod sbin složka.
$ ls -l /opt/spark
Spusťte Apache Spark v Ubuntu
Spuštěním následujícího příkazu spustíte Spark hlavní služba a podřízená služba.
$ start-master.sh
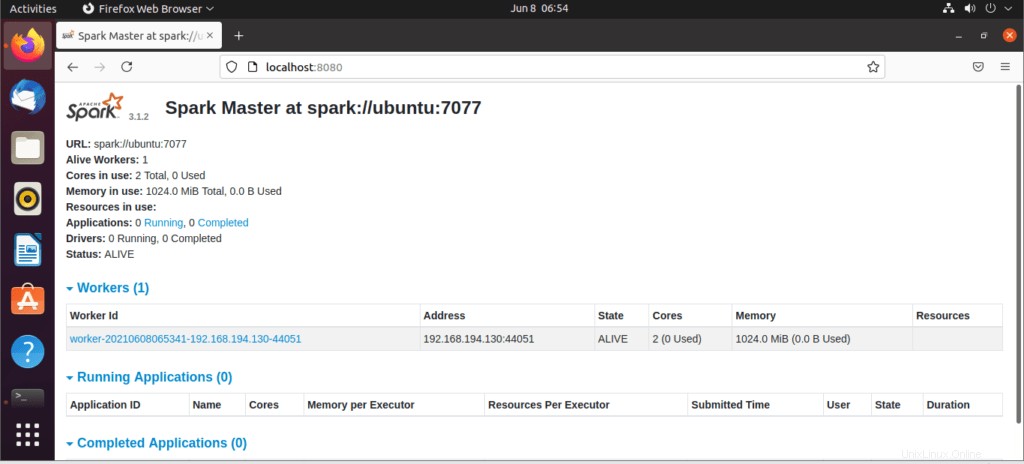
Po spuštění služby přejděte do prohlížeče a zadejte následující spouštěcí stránku pro přístup k URL. Na stránce můžete vidět, že moje hlavní služba je spuštěna.
http://localhost:8080/Poté můžete přidat pracovníka pomocí tohoto příkazu:
$ start-workers.sh spark://localhost:7077
Pracovník bude přidán podle obrázku:
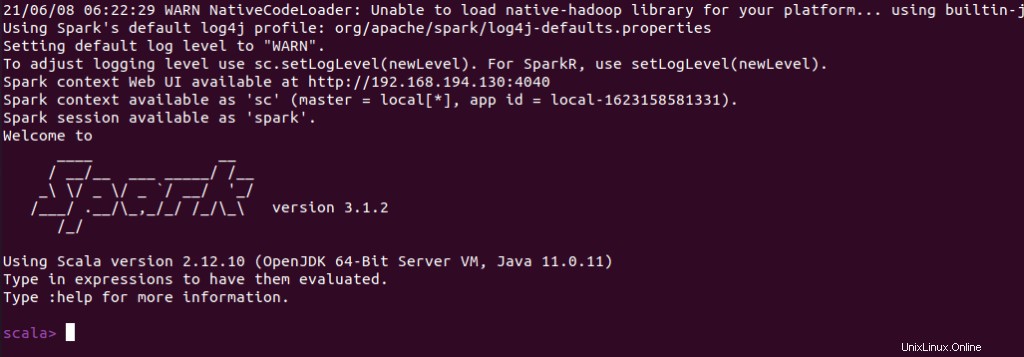
Můžete také zkontrolovat, zda spark-shell funguje dobře po spuštění spark-shell příkaz.
$ spark-shell