Úvod
Denormalizace databáze je technika používaná ke zlepšení výkonu přístupu k datům. Když je databáze normalizována a metody jako indexování nestačí, denormalizace slouží jako jedna z posledních možností, jak urychlit načítání dat.
Tento článek vysvětluje, co je denormalizace databáze a různé techniky používané k urychlení databáze.

Co je denormalizace databáze?
Denormalizace databáze je proces systematického kombinování dat za účelem rychlého získání informací. Tento proces snižuje vztahy na nižší normální formy, čímž snižuje celkovou integritu dat.
Na druhou stranu se zvyšuje výkon při získávání dat. Místo provádění více nákladných JOINů na mnoha tabulkách pomáhá normalizace databáze shromáždit informace, které jsou běžně nebo logicky kombinovány.
Databázové anomálie se objevují kvůli nižším normálním formám. Problém redundance nachází řešení v přidání omezení na úrovni softwaru při zadávání dat do databáze.
Normalizace databáze vs. denormalizace
Normalizace databáze a denormalizace jsou dva různé způsoby, jak změnit strukturu databáze. Tabulka popisuje hlavní rozdíly mezi těmito dvěma metodami:
| Normalizace | Denormalizace | |
|---|---|---|
| Funkčnost | Odebírá nadbytečné informace a zvyšuje rychlost změny dat. | Kombinuje více informací do jedné jednotky a zvyšuje rychlost načítání dat. |
| Zaměření | Čištění databáze za účelem odstranění nadbytečnosti. | Zavedena redundance pro rychlejší provádění dotazu. |
| Paměť | Optimalizovaný a vylepšený obecný výkon. | Neefektivní paměť kvůli redundanci. |
| Integrita | Odstranění anomálií databáze zlepšuje integritu databáze. | Žádná udržovaná integrita dat. Existují anomálie databáze. |
| Případ použití | Databáze, kde dochází často k vkládání, aktualizaci a odstraňování změn a spojení nejsou drahá. | Databáze, které jsou často dotazovány, jako jsou datové sklady. |
| Typ zpracování | Zpracování online transakcí – OLTP | Online analytické zpracování – OLAP |
Normalizace databáze přebírá nenormalizovanou databázi přes normální formy, aby se zlepšila struktura dat. Na druhou stranu denormalizace začíná normalizovanou databází a kombinuje data pro rychlejší provádění běžně používaných dotazů.
Proč a kdy byste měli denormalizovat databázi?
Denormalizace databáze je životaschopnou technikou, když je rychlost získávání dat zásadním faktorem. Metoda však mění celkovou strukturu databáze. Denormalizace je užitečná v následujících scénářích:
- Vylepšení výkonu dotazů. Skládání informací zvyšuje nadbytečnost. Počet JOINů se však snižuje, což zvyšuje výkon dotazů.
- Pohodlí při správě . Normalizovanou databázi je obtížné spravovat kvůli vysoké granularitě. Místo výpočtu hodnot nebo jejich spojování podle potřeby pomáhá denormalizace poskytovat snadno dostupná data.
- Urychlené vytváření přehledů . Analytická data vyžadují mnoho rychlých výpočtů. Denormalizovaná databáze pro generování zpráv je perfektním řešením pro rychlé poskytování analytických informací.
Pokud má databáze nízký výkon, denormalizace není vždy tou správnou cestou. Protože proces mění strukturu databáze, hrozí selhání stávajících funkcí.
Mít referenční bod je důležitý koncept při změně struktury databáze. Nakonec normalizace databáze slouží jako poslední možnost místo rychlého řešení.
Denormalizační techniky
V závislosti na případu použití se používají různé techniky denormalizace databáze. Každá metoda má vhodné místo použití, výhody a nevýhody.
Předběžné spojení tabulek
Předem spojené tabulky ukládají často používané informace společně do jedné tabulky. Tento proces se hodí, když:
- Dotazy se často spouštějí v tabulkách společně.
- Operace spojení je nákladná.
Metoda vytváří masivní redundanci, takže je nezbytné používat minimální počet sloupců a pravidelně aktualizovat informace.
Příklad předpřipojení stolů
Obchod uchovává informace o položkách a kategoriích, do kterých položky patří. Cizí klíč slouží jako odkaz na typ položky. Předpřipojením tabulek se do tabulky položek přidá název kategorie.
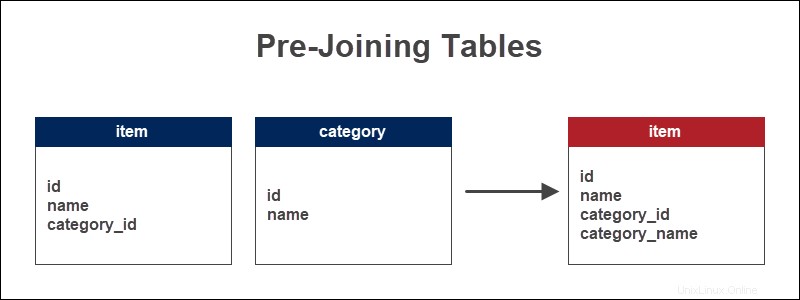
Přidání názvu kategorie přímo do tabulky položek umožňuje rychlé prohlížení položek podle kategorií. U delších dotazů tato metoda šetří čas a snižuje počet JOINů.
Zrcadlené tabulky
Zrcadlená tabulka je kopií existující tabulky. Tabulka je buď:
- Částečná kopie.
- Úplná kopie.
Cílem je reprodukovat data z originálu do nové tabulky. Vytváření duplikátů je dobrá technika pro vytvoření zálohy pro zachování počátečního stavu databáze.
Příklad zrcadlených tabulek
Zrcadlení tabulek je metoda často používaná pro přípravu dat v systémech pro podporu rozhodování. Vzhledem k tomu, že dotazy se obvykle agregují přes mnoho datových bodů, úloha by výrazně snížila výkon systému.
Systémy pro podporu rozhodování velmi těží z použití zrcadlených tabulek. Aplikace transakcí na původní tabulku probíhá bez přerušení, zatímco v duplicitní tabulce probíhají náročné zprávy.
Rozdělení tabulky
Rozdělení tabulek znamená rozdělení normalizovaných tabulek do dvou nebo více vztahů. Rozdělení tabulek probíhá ve dvou dimenzích:
- Vodorovně . Tabulky jsou rozděleny do podmnožin řádků pomocí
UNIONoperátor. - Svisle . Tabulky se rozdělí na podmnožiny sloupců pomocí
INNER JOINoperátor.
Cílem metody je rozdělit tabulky na menší jednotky pro rychlejší a pohodlnější manipulaci s daty. Pokud databáze obsahuje také původní tabulku, je tato metoda považována za konkrétní případ zrcadlených tabulek.
Příklady rozdělení tabulky
Příklady použití závisí na kritériích rozdělení tabulky. Nejčastější důvody pro rozdělení tabulek jsou:
- Administrativní . Jeden stůl pro každý sektor namísto jednoho stolu pro celou společnost.
- Prostorové . Jedna tabulka pro každý region namísto jedné tabulky pro celou zemi.
- Na základě času . Jeden stůl za každý měsíc místo jednoho stolu za celý rok.
- Fyzické . Jedna tabulka pro každé umístění namísto jedné tabulky pro všechny weby.
- Procedurální . Jedna tabulka pro každý krok v úloze namísto jedné tabulky pro celou úlohu.
Ukládání odvozených hodnot
Ukládání často prováděných výpočtů se vyplatí v situacích, kdy:
- Časté je použití odvozené hodnoty.
- Zdrojové hodnoty se nemění.
Přímé ukládání odvoditelných dat zajišťuje, že výpočty jsou prováděny již při generování sestavy, a eliminuje potřebu vyhledávat zdrojové hodnoty pro každý dotaz.
Příklad uložení odvozených hodnot
Pokud máme databázovou tabulku, která eviduje informace o lidech, je věk osoby vypočítaná hodnota na základě data narození. Odvoďte věk nalezením rozdílu mezi aktuálním datem pomocí funkce data MySQL CURDATE() a datum narození.
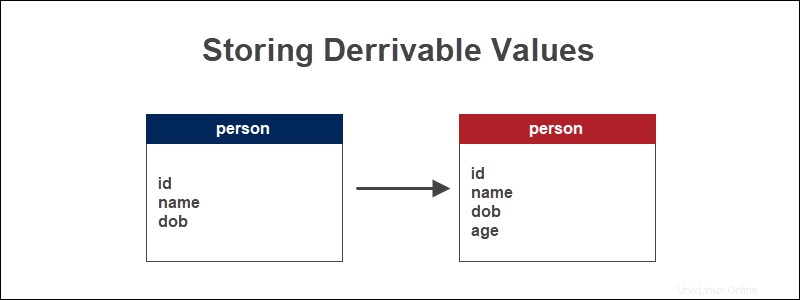
Věk je základní údaj při analýze jakýchkoli demografických informací. Zdrojová hodnota, kterou je datum narození, se nemění.
Tabulky hierarchie
Tabulka hierarchie je stromová struktura se vztahem jedna k mnoha. Jeden rodičovský stůl má mnoho dětí. Děti však mají pouze jeden rodičovský stůl. Hierarchické tabulky se používají v případech, kdy:
- Struktura dat je hierarchická.
- Nadřazené tabulky jsou statické a nemění se.
Pevně zakódované hodnoty
Pevně zakódované hodnoty odstraňují odkaz na běžně používanou entitu. Tuto metodu použijte v situacích, kdy:
- Hodnoty jsou považovány za statické.
- Počet hodnot je malý.
Namísto použití malé vyhledávací tabulky jsou hodnoty pevně zakódovány přímo do aplikace. Proces se také vyhne nutnosti provádět spojení ve vyhledávací tabulce.
Příklad pevně zakódovaných hodnot
Tabulka s informacemi o lidech by mohla využít malou vyhledávací tabulku k uložení informací o pohlaví jednotlivců. Protože informace ve vyhledávací tabulce mají omezený počet hodnot, zvažte pevné zakódování dat přímo do tabulky osob.
Pevně zakódované hodnoty eliminují potřebu vyhledávací tabulky a operace JOIN s touto tabulkou. Jakékoli změny provedené ve vyhledávací tabulce nebo záznam nových hodnot vyžadují přidání kontrolního omezení.
Ukládání podrobností pomocí Master
Hlavní tabulka obsahuje hlavní tabulku informací, zatímco ostatní tabulky obsahují specifické podrobnosti. Uložte podrobnosti s hlavní tabulkou, když:
- Podrobný přehled hlavní tabulky je nezbytný.
- Analytické zprávy na hlavní tabulce jsou časté.
Uchování všech detailů pomocí hlavní tabulky je praktické při výběru dat. Metoda funguje nejlépe, když je méně detailů. Jinak se proces načítání dat výrazně zpomalí.
Příklad ukládání podrobností pomocí Master
Hlavní tabulka s informacemi o zákaznících obvykle ukládá konkrétní podrobnosti o osobě v samostatné tabulce. Informace o konkrétním umístění se například obvykle nacházejí v řadě menších tabulek.
Každá sestava, která zvažuje polohu zákazníků, těží z přidání podrobností o umístění do hlavní tabulky.
Opakování jednoho detailu s předlohou
Dotazy často potřebují pouze jeden detail přidaný do hlavní tabulky namísto předběžného spojování více hodnot. Tuto metodu použijte, když:
- JOINy jsou nákladné na jeden detail.
- Hlavní tabulka vyžaduje informace často.
Přidání jednoho detailu do hlavní tabulky je nejběžnější, když databáze obsahuje historická data. Opakovaná entita je obvykle nejnovější informace.
Příklad jednotlivého detailu s předlohou
Databáze obchodu má obvykle hlavní tabulku informací o položkách, které prodává. Další tabulka s podrobnostmi o historických změnách cen také obsahuje informace o aktuální ceně.
Vzhledem k tomu, že tento jediný detail pomáhá analyzovat aktuální ceny položek, je užitečné zopakovat nejnovější informace o ceně v hlavní tabulce.
Jakékoli změny nákladů je třeba řešit a aktualizovat do hlavní tabulky, aby byla zajištěna konzistence.
Zkratové klávesy
V databázi se třemi nebo více tabulkami souvisejících informací metoda zkratovacích klíčů přeskočí prostřední tabulky a "zkratuje" tabulky prarodičů a vnuků.
Použijte techniku zkratu v situacích, kdy:
- Databáze má více než tři úrovně master-detail.
- Hodnoty od prarodiče a vnuka jsou často potřebné a informace o rodičích nejsou tak cenné.
Pokud se dva vztahy týkají prostřední tabulky, vynechejte JOIN na mezilehlém vztahu a připojte první a poslední tabulku přímo.
Příklad zkratovacích kláves
Informační systém by mohl uchovávat informace o lidech v jedné tabulce, jejich adresu na jiném místě a geografickou oblast této adresy ve třetí tabulce. U žádné demografické zprávy není přesná adresa kritickou informací.
Pro analýzu je však podstatná poloha osoby. Zkratování tabulky lidí s oblastí vynechá JOIN na prostřední tabulce.
Výhody denormalizace
Výhody denormalizace databáze jsou:
- Rychlost . Vzhledem k tomu, že dotazy JOIN jsou v normalizované databázi nákladné, načítání dat je rychlejší.
- Jednoduchost . Načítání dat je díky menšímu počtu tabulek jednodušší.
- Méně chyb . Práce s menším počtem tabulek znamená méně chyb při získávání informací z databáze.
Nevýhody denormalizace
Nevýhody Při denormalizaci databáze je třeba zvážit:
- Složitost . Aktualizace a vkládání do databáze je složitější a nákladnější.
- Nekonzistence . Nalezení správné hodnoty pro určitou informaci je náročnější, protože data se obtížně aktualizují.
- Úložiště . Větší úložný prostor je nezbytný kvůli zavedeným redundancím.