Hadoop je open-source framework, který se široce používá pro práci s Bigdata . Většina Bigdata/Data Analytics projekty jsou budovány nad ekosystémem Hadoop . Skládá se ze dvou vrstev, jedna je pro Ukládání dat a další je pro Zpracování dat .
Úložiště bude se starat o vlastní souborový systém nazvaný HDFS (Distribuovaný souborový systém Hadoop ) a Zpracování postará se o YARN (Ještě další vyjednavač zdrojů ). Mapreduce je výchozím procesorem Hadoop Eco-System .
Tento článek popisuje postup instalace Pseudonode instalace Hadoop , kde jsou všichni démoni (JVM ) poběží Single Node Cluster na CentOS 7 .
Toto je hlavně pro začátečníky, aby se naučili Hadoop. V reálném čase, Hadoop bude nainstalován jako multiuzlový cluster, kde budou data distribuována mezi servery jako bloky a úloha bude prováděna paralelně.
Předpoklady
- Minimální instalace serveru CentOS 7.
- Vydání Java v1.8.
- Stabilní vydání Hadoop 2.x.
Na této stránce
- Jak nainstalovat Java na CentOS 7
- Nastavit přihlašování bez hesla na CentOS 7
- Jak nainstalovat Hadoop Single Node v CentOS 7
- Jak nakonfigurovat Hadoop v CentOS 7
- Formátování systému souborů HDFS prostřednictvím NameNode
Instalace Javy na CentOS 7
1. Hadoop je Ekosystém, který se skládá z Java . Potřebujeme Java nainstalované v našem systému povinně k instalaci Hadoop .
# yum install java-1.8.0-openjdk
2. Dále ověřte nainstalovanou verzi Java v systému.
# java -version
Nakonfigurujte přihlášení bez hesla na CentOS 7
V našem počítači Hadoop potřebujeme nakonfigurovat ssh bude spravovat uzly pomocí SSH . Hlavní uzel používá SSH připojení pro připojení jeho podřízených uzlů a provádění operací jako start a stop.
Musíme nastavit ssh bez hesla, aby mohl master komunikovat s podřízenými pomocí ssh bez hesla. Jinak pro každé navázání připojení je nutné zadat heslo.
3. Nastavte přihlášení SSH bez hesla pomocí následujících příkazů na serveru.
# ssh-keygen# ssh-copy-id -i localhost
4. Po konfiguraci přihlášení SSH bez hesla se zkuste znovu přihlásit, budete připojeni bez hesla.
# ssh localhost
Instalace Hadoop v CentOS 7
5. Přejděte na web Apache Hadoop a stáhněte si stabilní vydání Hadoop pomocí následujícího příkazu wget.
# wget https://archive.apache.org/dist/hadoop/core/hadoop-2.10.1/hadoop-2.10.1.tar.gz# tar xvpzf hadoop-2.10.1.tar.gz6. Dále přidejte Hadoop proměnné prostředí v
~/.bashrcsoubor podle obrázku.HADOOP_PREFIX=/root/hadoop-2.10.1PATH=$PATH:$HADOOP_PREFIX/binexport PATH JAVA_HOME HADOOP_PREFIX7. Po přidání proměnných prostředí do
~/.bashrcsoubor, zdrojový soubor a ověřte Hadoop spuštěním následujících příkazů.# source ~/.bashrc# cd $HADOOP_PREFIX# verze bin/hadoop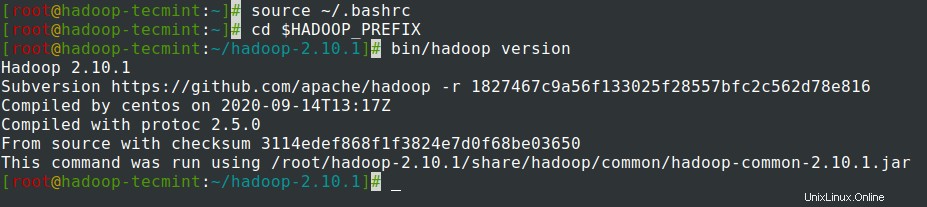
Konfigurace Hadoop v CentOS 7
Potřebujeme nakonfigurovat níže uvedené konfigurační soubory Hadoop, aby se vešly do vašeho počítače. V Hadoop každá služba má své vlastní číslo portu a svůj vlastní adresář pro ukládání dat.
- Konfigurační soubory Hadoop – core-site.xml, hdfs-site.xml, mapred-site.xml &yarn-site.xml
8. Nejprve musíme aktualizovat JAVA_HOME a Hadoop cestu v hadoop-env.sh soubor podle obrázku.
# cd $HADOOP_PREFIX/etc/hadoop# vi hadoop-env.sh
Na začátek souboru zadejte následující řádek.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0/jreexport HADOOP_PREFIX=/root/hadoop-2.10.1
9. Dále upravte core-site.xml soubor.
# cd $HADOOP_PREFIX/etc/hadoop# vi core-site.xml
Následující text vložte mezi <configuration> tagy, jak je znázorněno.
fs.defaultFS hdfs://localhost:9000
10. Vytvořte níže uvedené adresáře pod tecmint domovský adresář uživatele, který bude použit pro NN a DN úložiště.
# mkdir -p /home/tecmint/hdata/# mkdir -p /home/tecmint/hdata/data# mkdir -p /home/tecmint/hdata/name
10. Dále upravte hdfs-site.xml soubor.
# cd $HADOOP_PREFIX/etc/hadoop# vi hdfs-site.xml
Následující text vložte mezi <configuration> tagy, jak je znázorněno.
dfs.replication 1 dfs.namenode.name.dir /home/tecmint/ hdata/name dfs .datanode.data.dir home/tecmint/hdata/data
11. Znovu upravte mapred-site.xml soubor.
# cd $HADOOP_PREFIX/etc/hadoop# cp mapred-site.xml.template mapred-site.xml# vi mapred-site.xml
Následující text vložte mezi <configuration> tagy, jak je znázorněno.
mapreduce.framework.name příze
12. Nakonec upravte yarn-site.xml soubor.
# cd $HADOOP_PREFIX/etc/hadoop# vi yarn-site.xml
Následující text vložte mezi <configuration> tagy, jak je znázorněno.
yarn.nodemanager.aux-services mapreduce_shuffle
Formátování systému souborů HDFS prostřednictvím NameNode
13. Před spuštěním Clusteru , musíme naformátovat Hadoop NN v našem místním systému, kde byl nainstalován. Obvykle se to provede v počáteční fázi před prvním spuštěním clusteru.
Formátování NN způsobí ztrátu dat v metaúložišti NN, takže musíme být opatrnější, neměli bychom formátovat NN zatímco cluster běží, pokud to není vyžadováno záměrně.
# cd $HADOOP_PREFIX# bin/hadoop namenode -format
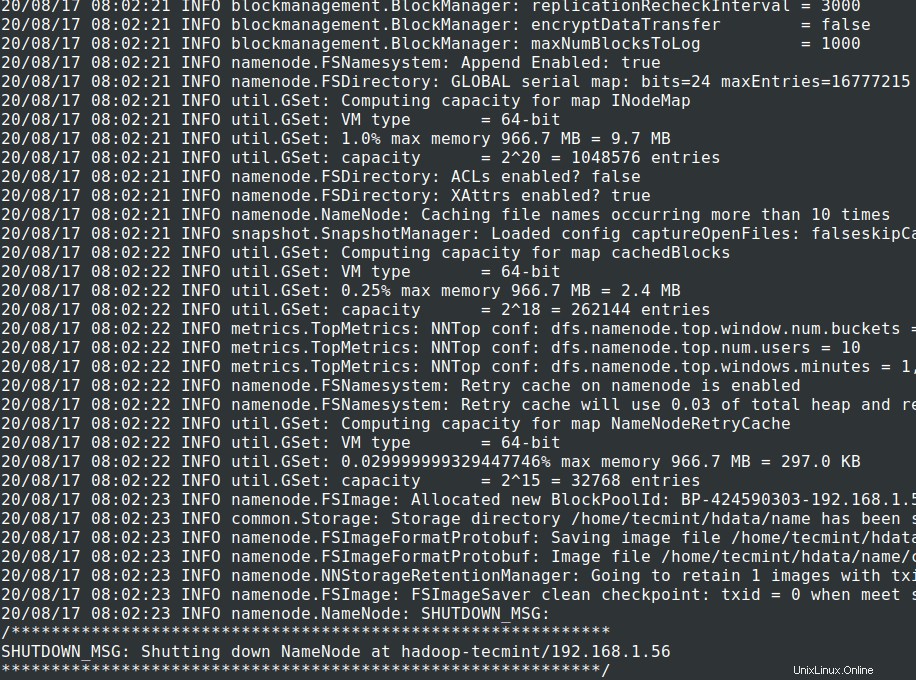
14. Spusťte NameNode démon a DataNode démon:(port 50070 ).
# cd $HADOOP_PREFIX# sbin/start-dfs.sh
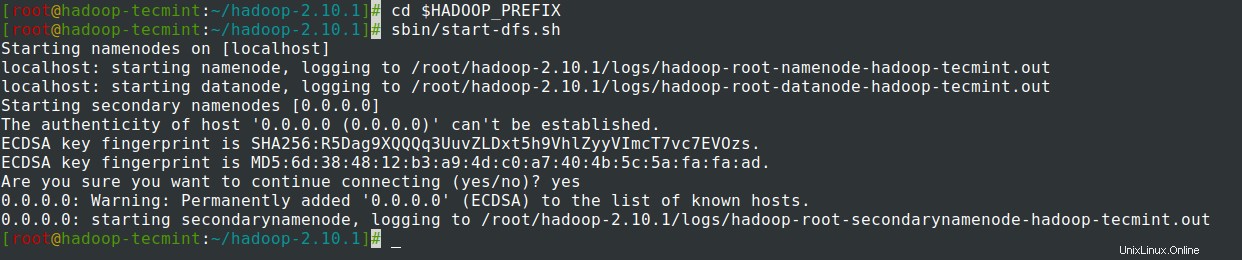
15. Spusťte ResourceManager démon a NodeManager démon:(port 8088 ).
# sbin/start-yarn.sh

16. Chcete-li zastavit všechny služby.
# sbin/stop-dfs.sh# sbin/stop-dfs.sh
Shrnutí
Shrnutí
V tomto článku jsme krok za krokem prošli procesem nastavení Hadoop Pseudonode (Jeden uzel ) Shluk . Pokud máte základní znalosti Linuxu a budete postupovat podle těchto kroků, cluster bude UP za 40 minut.
To může být pro začátečníka velmi užitečné, když se začne učit a cvičit Hadoop nebo tato vanilková verze Hadoop lze použít pro účely vývoje. Pokud chceme mít cluster v reálném čase, potřebujeme buď alespoň 3 fyzické servery, nebo musíme zajistit cloud pro více serverů.