Sysadmins mají mnoho nástrojů pro zobrazení a správu běžících procesů. Tyhle pro mě bývaly primárně top , nahoře a htop . Před pár lety jsem našel Glances, nástroj, který zobrazuje informace, které žádný z mých oblíbených nedělá. Všechny tyto nástroje monitorují využití CPU a paměti a většina z nich uvádí informace o běžících procesech (přinejmenším). Glances však také monitoruje I/O souborového systému, síťové I/O a údaje ze senzorů, které mohou zobrazovat teploty CPU a dalšího hardwaru, stejně jako rychlosti ventilátorů a využití disku podle hardwarového zařízení a logického svazku.
Pohledy
Glances jsem zmínil ve svém článku 4 open source nástroje pro monitorování systému Linux , ale hlouběji se tomu budu věnovat v tomto článku. Pokud jste četli můj předchozí článek, některé z těchto informací vám mohou být známé, ale také byste zde měli najít nějaké nové věci.
Glances je multiplatformní, protože je napsán v Pythonu. Lze jej nainstalovat na Windows a další hostitele s nainstalovanými aktuálními verzemi Pythonu. Většina linuxových distribucí (v mém případě Fedora) má Glances ve svých repozitářích. Pokud ne, nebo pokud používáte jiný operační systém (např. Windows), nebo jej jen chcete získat přímo ze zdroje, najdete pokyny ke stažení a instalaci v repozitáři GitHub Glances.
Doporučuji spustit Glances na testovacím počítači, zatímco budete zkoušet příkazy v tomto článku. Pokud nemáte fyzického hostitele k dispozici pro testování, můžete prozkoumat Glances na virtuálním počítači (VM), ale neuvidíte sekci hardwarových senzorů; koneckonců, virtuální počítač nemá žádný skutečný hardware.
Chcete-li spustit Glances na hostiteli Linuxu, otevřete relaci terminálu a zadejte příkaz glances .
Glances má tři hlavní části – Souhrn, Proces a Upozornění – a také postranní panel. Nyní je prozkoumám a další podrobnosti pro používání Glances.
Souhrnná sekce
V několika horních řádcích obsahuje část Souhrn Glances většinu stejných informací, jaké najdete v souhrnných částech jiných monitorů. Máte-li ve svém terminálu dostatek horizontálního prostoru, může Glances zobrazit využití CPU pomocí sloupcového grafu i číselného indikátoru; jinak zobrazí pouze číslo.
Sekce Souhrn Glances se mi líbí lépe než ty na jiných monitorech (jako top ); Myslím, že poskytuje správné informace ve snadno srozumitelném formátu.
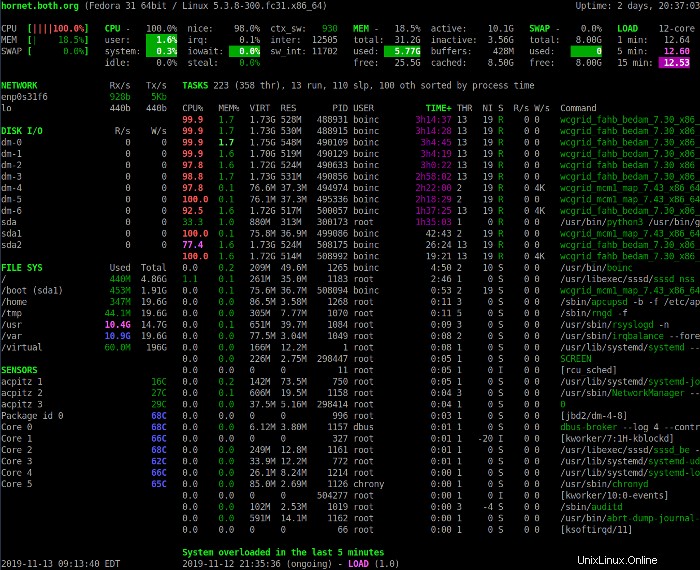
Část Souhrn výše poskytuje přehled o stavu systému. První řádek zobrazuje název hostitele, distribuci Linuxu, verzi jádra a dobu provozuschopnosti systému.
Další čtyři řádky zobrazují CPU, využití paměti, swap a statistiky zatížení. Levý sloupec zobrazuje procenta CPU, paměti a odkládacího prostoru, které se používají. Zobrazuje také kombinované statistiky pro všechny CPU přítomné v systému.
Stiskněte 1 pro přepínání mezi zobrazením konsolidovaného využití CPU a zobrazením jednotlivých CPU. Následující obrázek ukazuje zobrazení Glances s jednotlivými statistikami CPU.
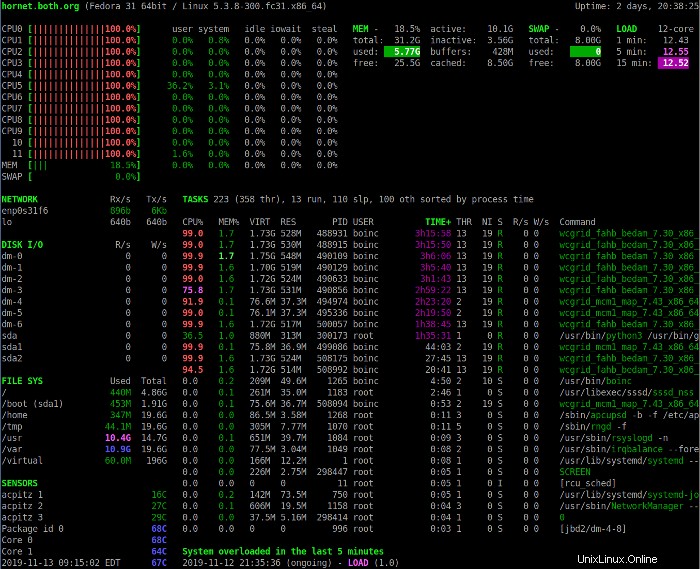
Toto zobrazení obsahuje některé další statistiky CPU. V obou režimech zobrazení vám popisy polí využití CPU mohou pomoci interpretovat data zobrazená v sekci CPU. Všimněte si, že CPU jsou číslována od 0 (nula).
| CPU | Toto je aktuální využití CPU jako procento z celkového dostupného počtu. |
| uživatel | Toto jsou aplikace a další programy běžící v uživatelském prostoru, tj. nikoli v jádře. |
| systém | Toto jsou funkce na úrovni jádra. Nezahrnuje čas CPU, který zabírá samotné jádro, pouze systémová volání jádra. |
| nečinný | Toto je doba nečinnosti, tj. doba, kterou nevyužívá žádný běžící proces. |
| pěkné | Toto je čas, který využívají procesy, které běží na pozitivní, pěkné úrovni. |
| irq | Toto jsou požadavky na přerušení, které zabírají čas CPU. |
| iwait | Toto jsou cykly CPU, které se stráví čekáním na vstup/výstup – to je plýtvání časem CPU. |
| ukrást | Procento cyklů CPU, po které virtuální CPU čeká na skutečný CPU, zatímco hypervizor obsluhuje jiný virtuální procesor. |
| ctx-sw | Toto je počet přepnutí kontextu za sekundu; představuje, kolikrát za sekundu CPU přepne z jednoho procesu na druhý. |
| inter | Toto je počet hardwarových přerušení za sekundu. K hardwarovému přerušení dochází, když hardwarové zařízení, jako je pevný disk, oznámí CPU, že dokončilo přenos dat nebo že karta síťového rozhraní je připravena přijmout další data. |
| sw_int | Softwarová přerušení informují CPU, že některá požadovaná úloha byla dokončena nebo že je software na něco připraven. Ty bývají běžnější v softwaru na úrovni jádra. |
O pěkných číslech
Hezká čísla jsou mechanismem, který správci používají k ovlivnění priority procesu. Není možné přímo změnit prioritu procesu, ale změna pěkného čísla může změnit výsledky algoritmu nastavení priority plánovače jádra. Pěkná čísla se pohybují od -20 do +19, kde vyšší čísla jsou hezčí. Výchozí pěkné číslo je 0 a výchozí priorita je 20. Nastavením pěkného čísla vyššího než nula se poněkud zvýší číslo priority, čímž je proces hezčí a tudíž méně náročný na cykly CPU. Nastavení pěkného čísla na zápornější číslo má za následek nižší prioritu, což způsobí, že proces bude méně pěkný. Pěkná čísla lze změnit pomocí příkazu renice nebo zevnitř top, atop a htop.
Paměť
Část Paměť v sekci Souhrn obsahuje statistiky o využití paměti.
| MEM | Ukazuje využití paměti jako procento z celkového dostupného množství. |
| celkem | Toto je celkové množství paměti RAM nainstalované v hostiteli, snížené o množství přiřazené grafickému adaptéru. |
| použité | Toto je celkové množství paměti využívané systémem a aplikačními programy, ale bez mezipaměti a vyrovnávacích pamětí. |
| zdarma | Toto je množství volné paměti. |
| aktivní | Toto je množství aktivně využívané paměti – neaktivní paměť se v případě potřeby vymění na disk. |
| neaktivní | Toto je paměť, která se používá, ale nebyla nějakou dobu přístupná. |
| vyrovnávací paměti | Toto je paměť, která se používá pro vyrovnávací paměť; obvykle se používá při komunikaci a I/O, jako je síť. Data jsou přijímána a ukládána, dokud je software nemůže získat pro použití nebo je nelze odeslat do úložného zařízení nebo odeslat do sítě. |
| uloženo do mezipaměti | Toto je paměť používaná k ukládání dat pro přenos na disk, dokud je nelze použít programem nebo uložit na disk. |
Část Swap je samovysvětlující, pokud trochu rozumíte swapovacímu prostoru a jak to funguje. To ukazuje, kolik celkového odkládacího prostoru je k dispozici, kolik je využito a kolik zbývá.
Část Load v sekci Summary zobrazuje jedno-, pěti- a 15minutové průměry zatížení.
Můžete použít číselné klávesy 1 , 3 , 4 a 5 změnit svůj pohled na data v této sekci. 2 zapíná a vypíná levý boční panel.
Další informace o průměrech zatížení
Průměry zatížení jsou běžně nepochopeny, i když jsou klíčovým kritériem pro měření využití CPU. Co ale doopravdy znamená, když řeknu, že průměr jedné (nebo pěti nebo desetiminutové zátěže) je například 4,04? Průměrná zátěž může být považována za míru poptávky po CPU; je to číslo, které představuje průměrný počet instrukcí čekajících na čas CPU, takže je skutečným měřítkem výkonu CPU.
Více o sysadmins
- Povolit blog Sysadmin
- Automatizovaný podnik:průvodce řízením IT pomocí automatizace
- eKniha:Ansible Automation for SysAdmins
- Příběhy z terénu:Průvodce správcem systému pro automatizaci IT
- eKniha:Průvodce Kubernetes pro SRE a správce systému
- Nejnovější články správce systému
Například plně využitý jednoprocesorový systém CPU by měl průměrnou zátěž 1. To znamená, že CPU přesně drží krok s poptávkou; jinými slovy, má dokonalé využití. Průměrná zátěž menší než 1 znamená, že CPU je nevyužitý, a průměrná zátěž větší než 1 znamená, že CPU je přetížené a že existuje zadržovaná, neuspokojená poptávka. Například průměrná hodnota zatížení 1,5 v systému s jedním CPU znamená, že jedna třetina instrukcí CPU musí čekat na provedení, dokud nebude dokončena předchozí.
To platí i pro více procesorů. Pokud má systém se čtyřmi CPU průměrnou zátěž 4, pak má dokonalé využití. Pokud má průměr zátěže například 3,24, pak jsou tři jeho procesory plně vytíženy a jeden je vytížen asi na 24 %. Ve výše uvedeném příkladu má systém se čtyřmi CPU průměrnou jednominutovou zátěž 4,04, což znamená, že mezi čtyřmi CPU nezbývá žádná zbývající kapacita a několik instrukcí je nuceno čekat. Perfektně využitý systém se čtyřmi CPU by vykazoval průměrnou zátěž 4,00, což znamená, že systém je plně zatížen, ale není přetížen.
Optimální podmínka průměrného zatížení je, aby se průměr zatížení rovnal celkovému počtu CPU v systému. To by znamenalo, že každý CPU je plně vytížen a žádná instrukce nesmí být nucena čekat. Ale realita je chaotická a optimální podmínky jsou splněny jen zřídka. Pokud by hostitel běžel na 100% využití, neumožňovalo by to skoky v požadavcích na zatížení CPU.
Dlouhodobé průměry zatížení ukazují celkové trendy využití.
Linux Journal publikoval ve svém vydání z 1. prosince 2006 vynikající článek o průměrech zatížení, teorii, matematice za nimi a jak je interpretovat. Bohužel Linux Journal přestala být publikována a její archivy již nejsou přímo dostupné, takže odkaz je na archiv třetí strany.
Hledání prasat CPU
Jedním z důvodů, proč používat nástroj, jako je Glances, je najít procesy, které zabírají příliš mnoho času CPU. Otevřete novou relaci terminálu (odlišnou od té, na které běží Glances) a zadejte a spusťte následující program Bash, který zatěžuje CPU.
X=0;while [ 1 ];do echo $X;X=$((X+1));doneTento program je CPU prase a využije každý dostupný cyklus CPU. Po dokončení tohoto článku jej nechte běžet a experimentujte s Glances. Poskytne vám představu o tom, jak vypadá program, který prase s cykly CPU. Nezapomeňte sledovat účinky na průměry zatížení v průběhu času a také kumulativní čas v TIME+ sloupec pro tento proces.
Sekce zpracování
Sekce Proces zobrazuje standardní informace o každém běžícím procesu. V závislosti na režimu zobrazení a velikosti obrazovky terminálu se pro běžící procesy zobrazí různé sloupce informací. Výchozí režim s dostatečně širokým terminálem zobrazuje níže uvedené sloupce. Sloupce, které se zobrazují, se automaticky změní, pokud se změní velikost obrazovky terminálu. Následující sloupce se obvykle zobrazují pro každý proces zleva doprava.
| CPU % | Toto je množství času CPU jako procento jednoho jádra. Například 98 % představuje 98 % dostupných cyklů CPU pro jedno jádro. Více procesů může ukázat až 100% využití CPU. |
| MEM % | Toto je množství paměti RAM použité procesem jako procento celkové virtuální paměti v hostiteli. |
| VIRT | Toto je množství virtuální paměti použité procesem ve formátu čitelném pro člověka, jako je 12 milionů na 12 megabajtů. |
| RES | To se týká množství fyzické (rezidentní) paměti používané procesem. Opět je to ve formátu čitelném pro člověka s indikátorem K , M nebo G , chcete-li zadat kilobajty, megabajty nebo gigabajty. |
| PID | Každý proces má identifikační číslo, které se nazývá PID. Toto číslo lze použít v příkazech, jako je renice a zabít , k řízení procesu. Pamatujte, že zabití utility může posílat signály jinému procesu kromě signálu „kill“. |
| UŽIVATEL | Toto je jméno uživatele, který vlastní proces. |
| TIME+ | Toto označuje kumulativní množství času CPU nashromážděného procesem od jeho spuštění. |
| THR | Toto je celkový počet vláken aktuálně spuštěných pro tento proces. |
| NI | Toto je pěkné číslo procesu. |
| S | Toto je aktuální stav; může být (R )unning, (S )spí, (já )dle, T nebo t když je proces zastaven během trasování ladění, nebo (Z )ombie. Zombie je proces, který byl zabit, ale nezemřel úplně, takže nadále spotřebovává některé systémové prostředky, jako je RAM. |
| R/s a W/s | Toto jsou čtení a zápisy disku za sekundu. |
| Příkaz | Toto je příkaz používaný ke spuštění procesu. |
Glances obvykle určuje výchozí sloupec řazení automaticky. Procesy lze třídit automaticky (a ), nebo podle CPU (c ), paměť (m ), jméno (p ), uživatel (u ), rychlost I/O (i ), nebo čas (t ). Procesy jsou automaticky seřazeny podle nejpoužívanějšího zdroje. Na obrázcích výše TIME+ sloupec je zvýrazněn.
Sekce upozornění
Glances také zobrazuje varování a kritická upozornění, včetně času a trvání události, ve spodní části obrazovky. To může být užitečné, když se pokoušíte diagnostikovat problémy a nemůžete hodiny v kuse zírat na obrazovku. Tyto protokoly výstrah lze zapnout nebo vypnout pomocí l (malé L), varování lze vymazat pomocí w zatímco výstrahy a varování lze všechna vymazat pomocí x .
Postranní panel
Glances má velmi pěkný postranní panel vlevo, který zobrazuje informace, které nejsou dostupné nahoře nebo htop . Zatímco nahoře zobrazuje některá z těchto dat, Glances je jediný monitor, který zobrazuje data o senzorech. Koneckonců, někdy je hezké vidět teploty uvnitř vašeho počítače.
Jednotlivé moduly, disk, souborový systém, síť a senzory lze zapínat a vypínat pomocí d , f , n a s klíče, resp. Celý postranní panel lze přepínat pomocí 2 . Statistiky dockeru lze zobrazit na postranním panelu pomocí D .
Všimněte si, že hardwarové senzory se nezobrazují, když Glances běží na virtuálním počítači.
Získání nápovědy
Nápovědu získáte stisknutím h klíč; zavřete stránku nápovědy stisknutím h znovu. Stránka nápovědy je poměrně stručná, ale ukazuje dostupné interaktivní možnosti a jak je zapnout a vypnout. Manuová stránka obsahuje stručné vysvětlení možností, které lze použít při spouštění Glances.
Můžete stisknout q nebo Esc pro ukončení Glances.
Konfigurace
Glances ke správnému fungování nevyžaduje konfigurační soubor. Pokud se rozhodnete jej mít, bude celosystémová instance konfiguračního souboru umístěna v /etc/glances/glances.conf . Jednotliví uživatelé mohou mít místní instanci na adrese ~/.config/glances/glances.conf , která přepíše globální konfiguraci. Primárním účelem těchto konfiguračních souborů je nastavit prahové hodnoty pro varování a kritická varování. Můžete také určit, zda se určité moduly zobrazují ve výchozím nastavení nebo ne.
Soubor /usr/local/share/doc/glances/README.rst obsahuje další užitečné informace, včetně volitelných modulů Pythonu, které si můžete nainstalovat pro podporu některých volitelných funkcí Glances.
Možnosti příkazového řádku
Glances poskytuje možnosti příkazového řádku, které umožňují spouštění v určitých režimech zobrazení. Například příkaz pohledy -2 spustí program s deaktivovaným levým postranním panelem.
Dálkové ovládání a další
Když jej spustíte v režimu serveru, můžete použít Glances ke sledování vzdálených hostitelů:
[root@testvm1 ~]# glances -sPoté se můžete připojit k serveru z klienta pomocí:
[root@testvm2 ~]# glances -c @testvm1Glances může zobrazit seznam serverů Glances spolu se souhrnem jejich aktivity. Má také webové rozhraní, takže můžete sledovat vzdálené servery Glances z prohlížeče. Nejnovější verze Glances mohou také zobrazovat statistiky Docker.
Existují také zásuvné moduly pro Glances, které poskytují data měření, která nejsou k dispozici v základním programu.
Omezení
Přestože Glances může monitorovat mnoho aspektů hostitele, nemůže řídit procesy. Nemůže změnit pěkné číslo procesu ani zabít jeden, jako top a htop umět. Glances není interaktivní nástroj. Používá se výhradně pro monitorování. Externí nástroje jako zabít a renice lze použít ke správě procesů.
Pohledy mohou zobrazit pouze procesy, které zabírají většinu zadaného prostředku, jako je čas CPU, v dostupném prostoru. Pokud je prostor pro vypsání pouze 10 procesů, je to vše, co budete moci vidět. Glances neposkytuje možnosti posouvání nebo zpětného řazení, které by vám umožnily vidět jiné procesy než X nejlepších.
Vliv měření
Efekt pozorovatele je fyzikální teorie, která říká, "prosté pozorování situace nebo jevu nutně změní tento jev." To platí také při měření výkonu systému Linux.
Pouhé použití monitorovacího nástroje mění využití zdrojů systému, včetně paměti a času CPU. nahoře utility a většina ostatních monitorů využívá možná 2 % až 3 % systémového CPU času. Nástroj Glances má mnohem větší dopad než ostatní; obvykle využívá 10 % až 20 % CPU času a viděl jsem, že využívá až 40 % jednoho CPU ve velmi velkém a aktivním systému s 32 CPU. To je hodně, takže při přemýšlení o použití Glances jako monitoru zvažte jeho dopad.
Můj osobní názor je, že je to malá cena, kterou musíte zaplatit, když potřebujete schopnosti Glances.
Přehled
Navzdory nedostatku interaktivních schopností, jako je schopnost renice nebo zabít Process a jeho vysoké zatížení CPU považuji Glances za velmi užitečný nástroj. Kompletní dokumentace Glances je dostupná na internetu a manuálová stránka Glances obsahuje možnosti spuštění a interaktivní informace o příkazech.
Části tohoto článku jsou založeny na nové knize Davida Botha Using and Administering Linux:Volume 2 – Zero to SysAdmin:Advanced Topics.