Úvod
Každé velké odvětví implementuje Apache Hadoop jako standardní rámec pro zpracování a ukládání velkých dat. Hadoop je navržen pro nasazení v síti stovek nebo dokonce tisíců dedikovaných serverů. Všechny tyto stroje spolupracují, aby se vypořádaly s obrovským objemem a rozmanitostí příchozích datových sad.
Nasazení služeb Hadoop na jeden uzel je skvělý způsob, jak se seznámit se základními příkazy a koncepty Hadoop.
Tento jednoduchý průvodce vám pomůže nainstalovat Hadoop na Ubuntu 18.04 nebo Ubuntu 20.04.

Předpoklady
- Přístup k oknu terminálu/příkazovému řádku
- Sudo nebo root oprávnění na místních /vzdálených počítačích
Nainstalujte OpenJDK na Ubuntu
Rámec Hadoop je napsán v Javě a jeho služby vyžadují kompatibilní Java Runtime Environment (JRE) a Java Development Kit (JDK). K aktualizaci systému před zahájením nové instalace použijte následující příkaz:
sudo apt updateV současné době Apache Hadoop 3.x plně podporuje Java 8 . Balíček OpenJDK 8 v Ubuntu obsahuje běhové prostředí i vývojovou sadu.
Chcete-li nainstalovat OpenJDK 8, zadejte do svého terminálu následující příkaz:
sudo apt install openjdk-8-jdk -yVerze OpenJDK nebo Oracle Java může ovlivnit interakci prvků ekosystému Hadoop. Chcete-li nainstalovat konkrétní verzi Java, podívejte se na našeho podrobného průvodce, jak nainstalovat Java na Ubuntu.
Po dokončení procesu instalace ověřte aktuální verzi Java:
java -version; javac -versionVýstup vás informuje, která edice Java se používá.

Nastavení uživatele bez oprávnění root pro prostředí Hadoop
Je vhodné vytvořit uživatele bez oprávnění root, konkrétně pro prostředí Hadoop. Jednotlivý uživatel zlepšuje zabezpečení a pomáhá vám efektivněji spravovat váš cluster. Aby bylo zajištěno hladké fungování služeb Hadoop, měl by mít uživatel možnost vytvořit připojení SSH bez hesla s místním hostitelem.
Nainstalujte OpenSSH na Ubuntu
Nainstalujte server a klienta OpenSSH pomocí následujícího příkazu:
sudo apt install openssh-server openssh-client -yV níže uvedeném příkladu výstup potvrzuje, že nejnovější verze je již nainstalována.

Pokud jste OpenSSH nainstalovali poprvé, využijte tuto příležitost k implementaci těchto zásadních bezpečnostních doporučení SSH.
Vytvořit uživatele Hadoop
Použijte adduser příkaz k vytvoření nového uživatele Hadoop:
sudo adduser hdoopUživatelské jméno je v tomto příkladu hdoop . Můžete použít libovolné uživatelské jméno a heslo, které uznáte za vhodné. Přepněte na nově vytvořeného uživatele a zadejte odpovídající heslo:
su - hdoopUživatel nyní potřebuje mít možnost SSH na localhost, aniž by byl vyzván k zadání hesla.
Povolte Passwordless SSH pro uživatele Hadoop
Vygenerujte pár klíčů SSH a definujte umístění, které má být uloženo v:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsaSystém pokračuje ve vygenerování a uložení páru klíčů SSH.
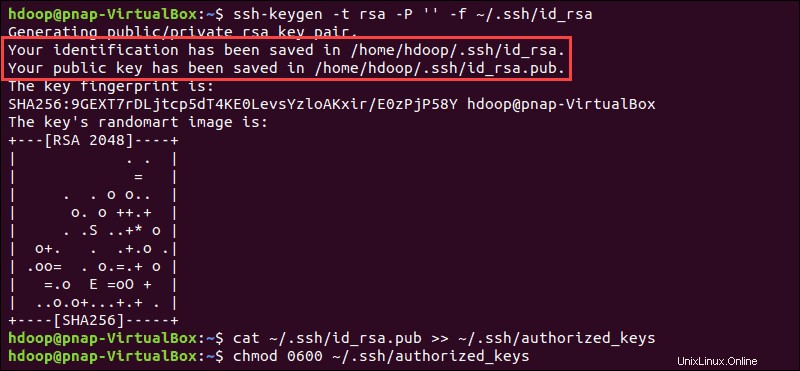
Použijte cat příkaz k uložení veřejného klíče jako autorizované_klíče v ssh adresář:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Nastavte oprávnění pro svého uživatele pomocí chmod příkaz:
chmod 0600 ~/.ssh/authorized_keysNový uživatel je nyní schopen SSH, aniž by musel pokaždé zadávat heslo. Ověřte, že je vše správně nastaveno pomocí hdoop uživatele na SSH na localhost:
ssh localhostPo úvodní výzvě je nyní uživatel Hadoop schopen bezproblémově navázat připojení SSH k místnímu hostiteli.
Stáhněte si a nainstalujte Hadoop na Ubuntu
Navštivte oficiální stránku projektu Apache Hadoop a vyberte verzi Hadoop, kterou chcete implementovat.
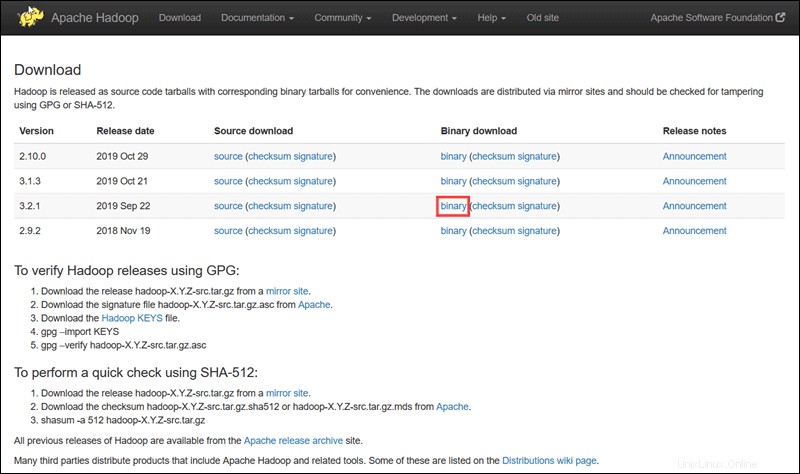
Kroky popsané v tomto tutoriálu používají binární stažení pro Hadoop verze 3.2.1 .
Vyberte preferovanou možnost a zobrazí se vám zrcadlový odkaz, který vám umožní stáhnout balíček Hadoop tar .
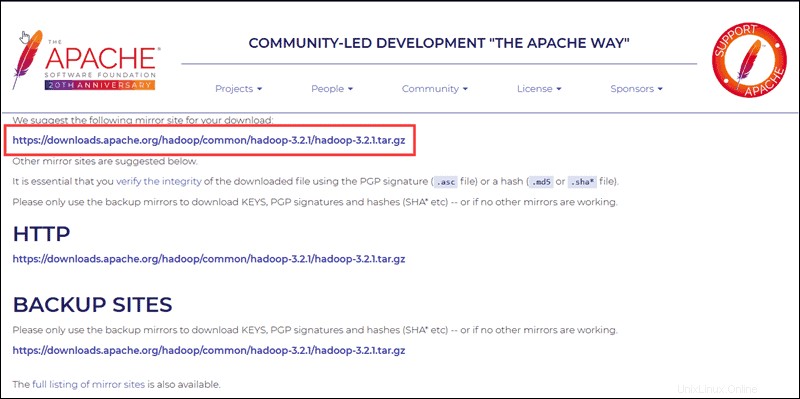
Použijte poskytnutý zrcadlový odkaz a stáhněte si balíček Hadoop pomocí wget příkaz:
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz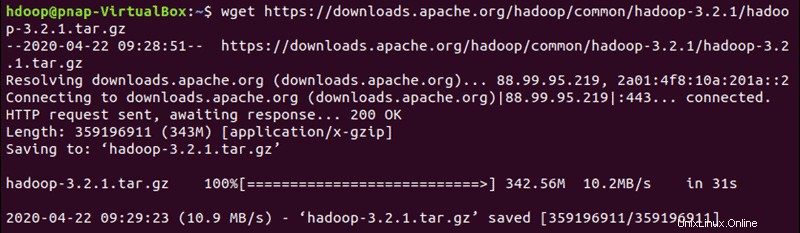
Po dokončení stahování rozbalte soubory, abyste zahájili instalaci Hadoop:
tar xzf hadoop-3.2.1.tar.gzBinární soubory Hadoop jsou nyní umístěny v hadoop-3.2.1 adresář.
Nasazení jednoho uzlu Hadoop (Pseudo-distribuovaný režim)
Hadoop vyniká při nasazení v plně distribuovaném režimu na velkém clusteru síťových serverů. Pokud však s Hadoopem začínáte a chcete prozkoumat základní příkazy nebo otestovat aplikace, můžete Hadoop nakonfigurovat na jediném uzlu.
Toto nastavení se také nazývá pseudodistribuovaný režim , umožňuje každému démonu Hadoop běžet jako jeden proces Java. Prostředí Hadoop se konfiguruje úpravou sady konfiguračních souborů:
- bashrc
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site-xml
- yarn-site.xml
Konfigurace proměnných prostředí Hadoop (bashrc)
Upravte soubor .bashrc konfigurační soubor shellu pomocí textového editoru dle vašeho výběru (my budeme používat nano):
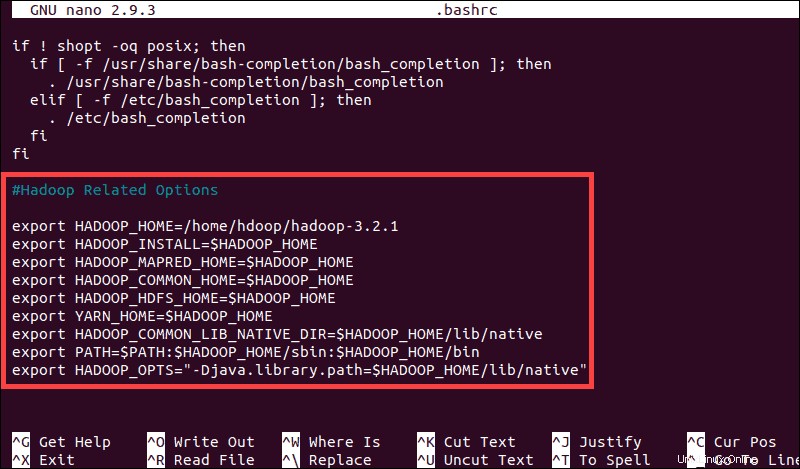
sudo nano .bashrcDefinujte proměnné prostředí Hadoop přidáním následujícího obsahu na konec souboru:
#Hadoop Related Options
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS"-Djava.library.path=$HADOOP_HOME/lib/nativ"
Jakmile přidáte proměnné, uložte a ukončete soubor .bashrc soubor.
Je důležité použít změny na aktuální běžící prostředí pomocí následujícího příkazu:
source ~/.bashrcUpravit soubor hadoop-env.sh
hadoop-env.sh slouží jako hlavní soubor pro konfiguraci nastavení projektu YARN, HDFS, MapReduce a Hadoop.
Při nastavování jednouzlového clusteru Hadoop , musíte definovat, která implementace Java se má použít. Použijte dříve vytvořený $HADOOP_HOME pro přístup k hadoop-env.sh soubor:
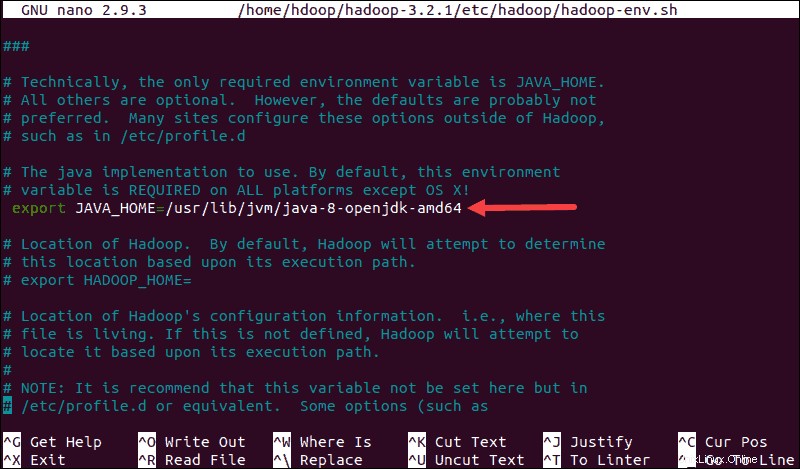
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Odkomentujte $JAVA_HOME proměnnou (tj. odstraňte # sign) a přidejte úplnou cestu k instalaci OpenJDK ve vašem systému. Pokud jste nainstalovali stejnou verzi, jaká je uvedena v první části tohoto kurzu, přidejte následující řádek:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64Cesta musí odpovídat umístění instalace Java ve vašem systému.
Pokud potřebujete pomoc s nalezením správné cesty Java, spusťte v okně terminálu následující příkaz:
which javacVýsledný výstup poskytuje cestu k binárnímu adresáři Java.

Pomocí zadané cesty vyhledejte adresář OpenJDK pomocí následujícího příkazu:
readlink -f /usr/bin/javac
Část cesty těsně před /bin/javac adresář musí být přiřazen k $JAVA_HOME proměnná.

Upravit soubor core-site.xml
Soubor core-site.xml definuje vlastnosti jádra HDFS a Hadoop.
Chcete-li nastavit Hadoop v pseudodistribuovaném režimu, musíte zadat adresu URL pro váš NameNode a dočasný adresář, který Hadoop používá pro proces mapování a redukce.
Otevřete soubor core-site.xml soubor v textovém editoru:
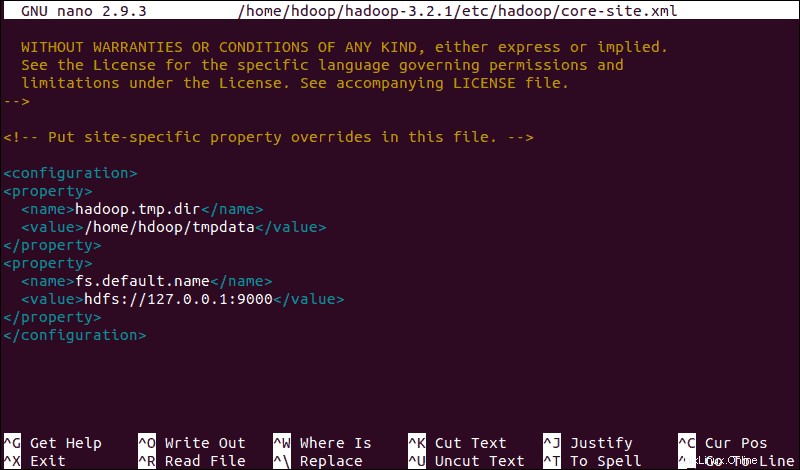
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xmlPřidáním následující konfigurace přepíšete výchozí hodnoty pro dočasný adresář a přidáte adresu URL HDFS, která nahradí výchozí nastavení místního systému souborů:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdoop/tmpdata</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>Tento příklad používá hodnoty specifické pro místní systém. Měli byste použít hodnoty, které odpovídají vašim požadavkům na systém. Data musí být konzistentní během procesu konfigurace.
Nezapomeňte vytvořit adresář Linux v umístění, které jste zadali pro svá dočasná data.
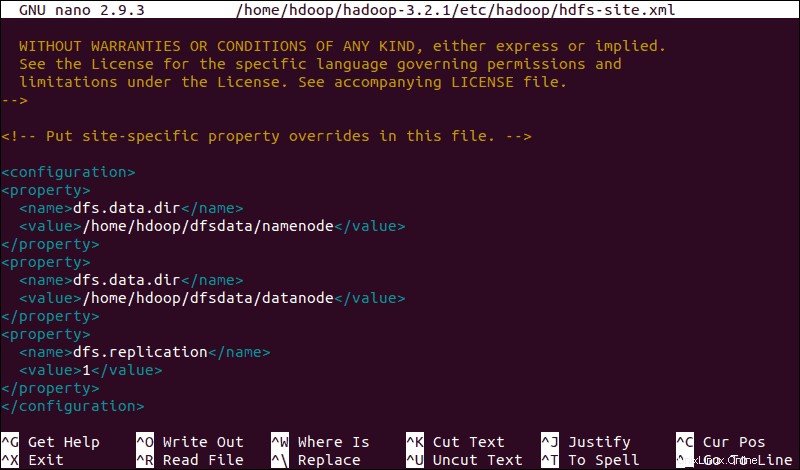
Upravit soubor hdfs-site.xml
Vlastnosti v hdfs-site.xml soubor řídí umístění pro ukládání metadat uzlu, soubor fsimage a soubor protokolu úprav. Nakonfigurujte soubor definováním NameNode aadresáře úložiště DataNode .
Navíc výchozí dfs.replication hodnotu 3 je třeba změnit na 1 aby odpovídaly nastavení jednoho uzlu.
Pomocí následujícího příkazu otevřete soubor hdfs-site.xml soubor pro úpravu:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xmlPřidejte do souboru následující konfiguraci a v případě potřeby upravte adresáře NameNode a DataNode na svá vlastní umístění:
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
V případě potřeby vytvořte konkrétní adresáře, které jste definovali pro dfs.data.dir hodnotu.
Upravit soubor mapred-site.xml
Pro přístup k mapred-site.xml použijte následující příkaz soubor a definujte hodnoty MapReduce :
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Chcete-li změnit výchozí hodnotu názvu rámce MapReduce na yarn, přidejte následující konfiguraci :
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>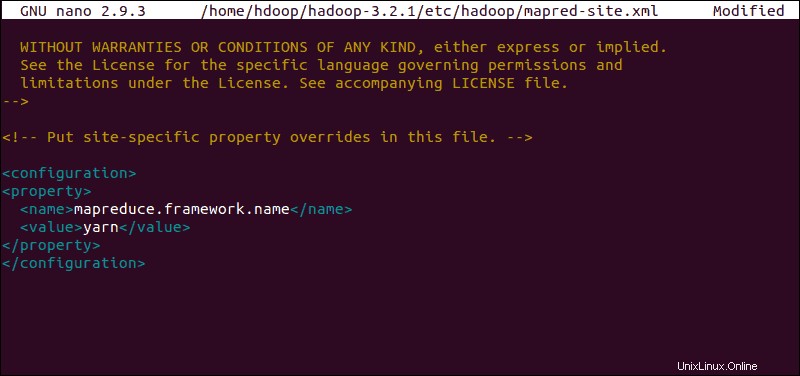
Upravit soubor yarn-site.xml
Soubor yarn-site.xml soubor se používá k definování nastavení relevantních pro YARN . Obsahuje konfigurace pro Správce uzlů, Správce prostředků, Kontejnery a Aplikační hlavní .
Otevřete soubor yarn-site.xml soubor v textovém editoru:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xmlPřipojte k souboru následující konfiguraci:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>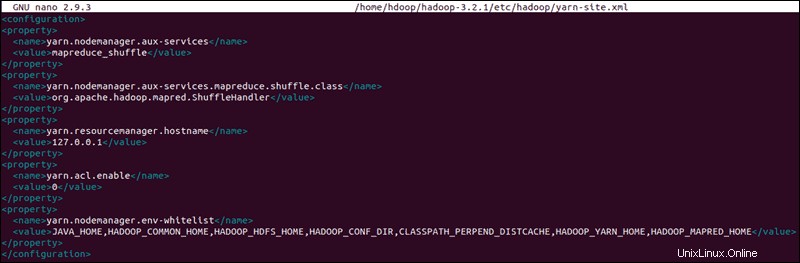
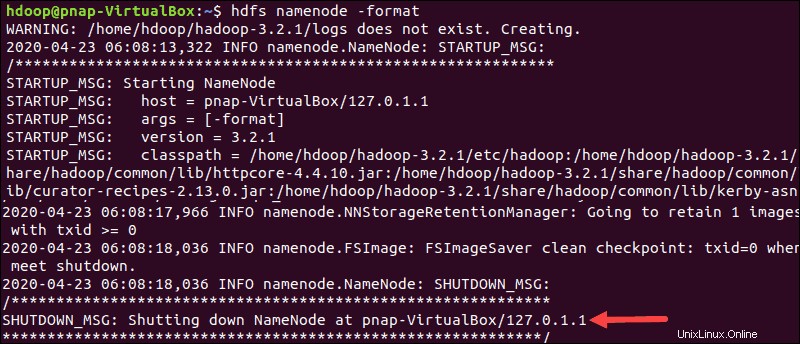
Formátovat HDFS NameNode
Je důležité naformátovat NameNode před prvním spuštěním služeb Hadoop:
hdfs namenode -formatOznámení o vypnutí znamená konec procesu formátování NameNode.
Spustit Hadoop Cluster
Přejděte na hadoop-3.2.1/sbin a spusťte následující příkazy pro spuštění NameNode a DataNode:
./start-dfs.shSystému chvíli trvá, než spustí potřebné uzly.

Jakmile budou jmenný uzel, datové uzly a sekundární jmenný uzel spuštěny, spusťte prostředek YARN a správce uzlů zadáním:
./start-yarn.shStejně jako u předchozího příkazu vás výstup informuje, že procesy začínají.

Zadejte tento jednoduchý příkaz a zkontrolujte, zda jsou všichni démoni aktivní a běží jako procesy Java:
jpsPokud vše funguje tak, jak má, výsledný seznam běžících procesů Java obsahuje všechny démony HDFS a YARN.

Přístup k uživatelskému rozhraní Hadoop z prohlížeče
Použijte preferovaný prohlížeč a přejděte na adresu URL nebo IP místního hostitele. Výchozí číslo portu 9870 vám poskytuje přístup k uživatelskému rozhraní Hadoop NameNode:
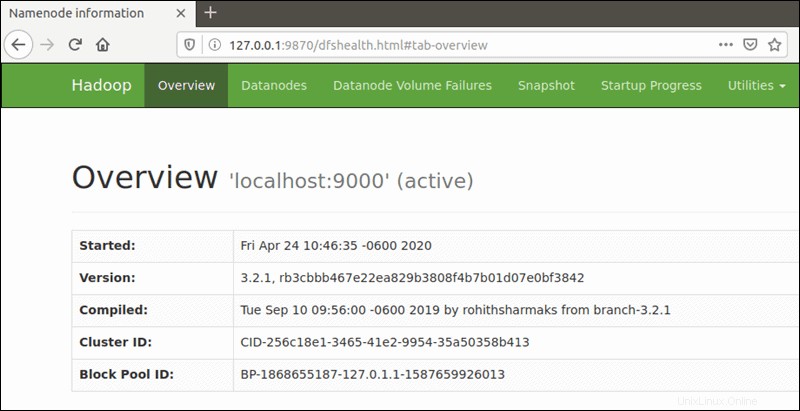
http://localhost:9870Uživatelské rozhraní NameNode poskytuje komplexní přehled o celém clusteru.
Výchozí port 9864 se používá pro přístup k jednotlivým DataNodes přímo z vašeho prohlížeče:
http://localhost:9864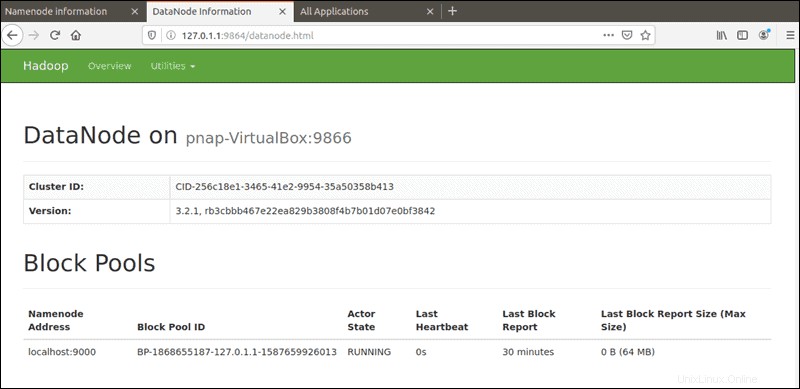
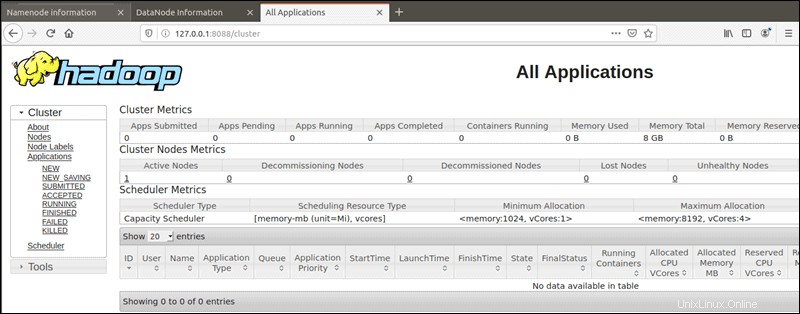
Správce prostředků YARN je přístupný na portu 8088 :
http://localhost:8088Správce zdrojů je neocenitelný nástroj, který vám umožní sledovat všechny běžící procesy ve vašem clusteru Hadoop.