Apache Hadoop se skládá z několika softwarových balíků s otevřeným zdrojovým kódem, které spolupracují pro distribuované úložiště a distribuované zpracování velkých dat. Hadoop má čtyři hlavní součásti:
- Hadoop Common – různé softwarové knihovny, na jejichž spuštění je Hadoop závislý
- Hadoop Distributed File System (HDFS) – souborový systém, který umožňuje efektivní distribuci a ukládání velkých dat napříč shlukem počítačů
- Hadoop MapReduce – používané pro zpracování údajů
- Hadoop PŘÍZE – API, které spravuje alokaci výpočetních zdrojů pro celý cluster
V tomto tutoriálu projdeme kroky k instalaci Hadoop verze 3 na Ubuntu 20.04. To bude zahrnovat instalaci HDFS (Namenode a Datanode), YARN a MapReduce do jednoho clusteru uzlu nakonfigurovaného v Pseudo Distributed Mode, což je distribuovaná simulace na jednom počítači. Každá součást Hadoopu (HDFS, YARN, MapReduce) poběží na našem uzlu jako samostatný proces Java.
V tomto tutoriálu se naučíte:
- Jak přidat uživatele pro prostředí Hadoop
- Předpoklad instalace Java
- Jak nakonfigurovat SSH bez hesla
- Jak nainstalovat Hadoop a nakonfigurovat potřebné související soubory XML
- Jak spustit Hadoop Cluster
- Jak získat přístup k webovému uživatelskému rozhraní NameNode a ResourceManager
 Apache Hadoop na Ubuntu 20.04 Focal Fossa
Apache Hadoop na Ubuntu 20.04 Focal Fossa| Kategorie | Požadavky, konvence nebo použitá verze softwaru |
|---|---|
| Systém | Nainstalováno Ubuntu 20.04 nebo upgradované Ubuntu 20.04 Focal Fossa |
| Software | Apache Hadoop, Java |
| Jiné | Privilegovaný přístup k vašemu systému Linux jako root nebo prostřednictvím sudo příkaz. |
| Konvence | # – vyžaduje, aby dané linuxové příkazy byly spouštěny s právy root buď přímo jako uživatel root, nebo pomocí sudo příkaz$ – vyžaduje, aby dané linuxové příkazy byly spouštěny jako běžný neprivilegovaný uživatel |
Vytvořit uživatele pro prostředí Hadoop
Hadoop by měl mít ve vašem systému svůj vlastní vyhrazený uživatelský účet. Chcete-li jej vytvořit, otevřete terminál a zadejte následující příkaz. Budete také vyzváni k vytvoření hesla pro účet.
$ sudo adduser hadoop
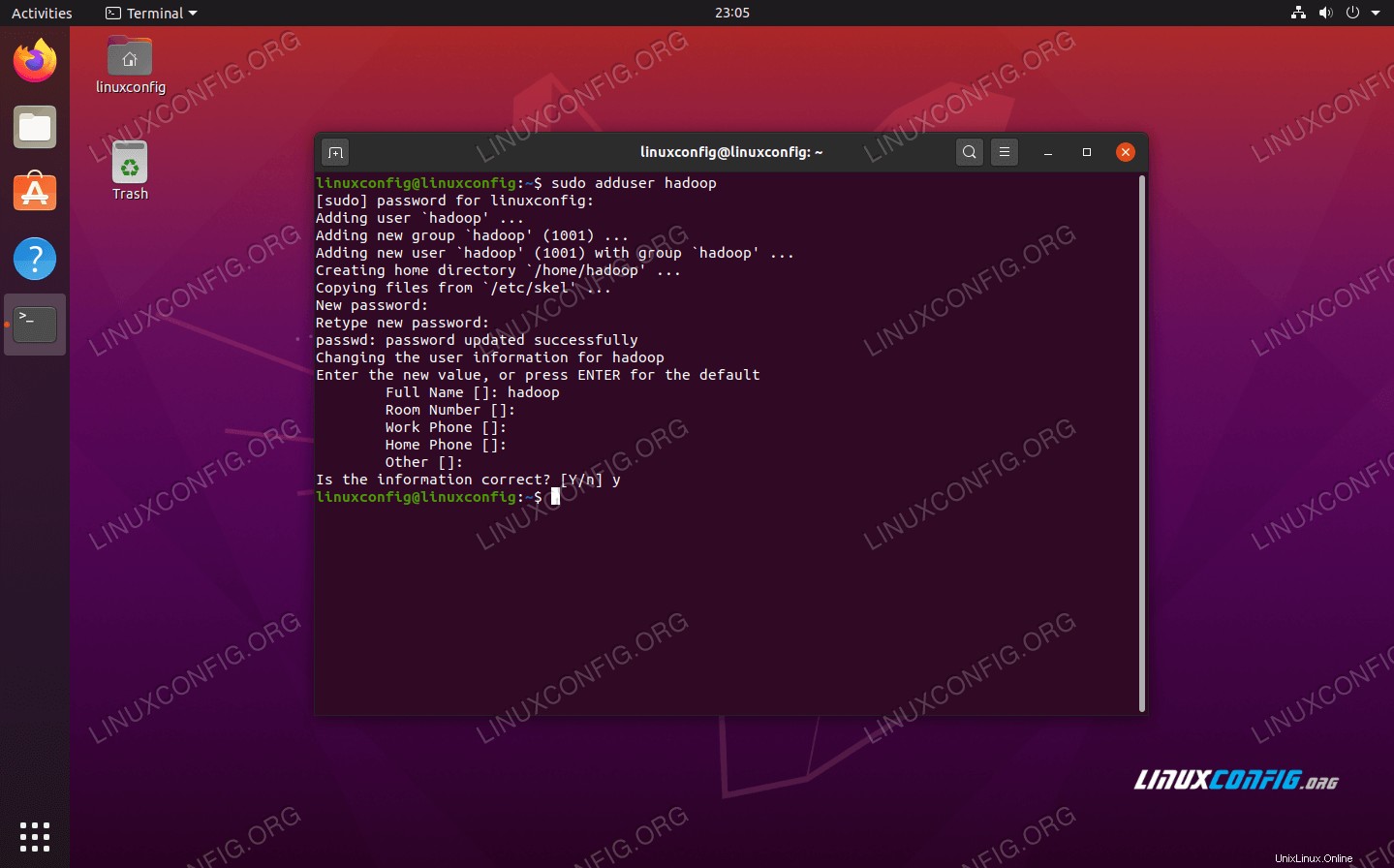 Vytvořit nového uživatele Hadoop
Vytvořit nového uživatele Hadoop Nainstalujte předpoklad Java
Hadoop je založen na Javě, takže jej budete muset nainstalovat do svého systému, než budete moci používat Hadoop. V době psaní tohoto článku vyžaduje aktuální Hadoop verze 3.1.3 Java 8, takže to je to, co budeme instalovat do našeho systému.
Pomocí následujících dvou příkazů načtete nejnovější seznamy balíčků v apt a nainstalujte Java 8:
$ sudo apt update $ sudo apt install openjdk-8-jdk openjdk-8-jre
Konfigurace SSH bez hesla
Hadoop se při přístupu ke svým uzlům spoléhá na SSH. Připojí se ke vzdáleným počítačům prostřednictvím SSH a také k vašemu místnímu počítači, pokud na něm běží Hadoop. Takže i když v tomto tutoriálu nastavujeme Hadoop pouze na našem místním počítači, stále potřebujeme mít nainstalované SSH. Musíme také nakonfigurovat SSH bez hesla
tak, aby Hadoop mohl tiše navazovat připojení na pozadí.
- Budeme potřebovat OpenSSH Server i OpenSSH Client balíček. Nainstalujte je pomocí tohoto příkazu:
$ sudo apt install openssh-server openssh-client
- Než budete pokračovat, je nejlepší být přihlášen do
hadoopuživatelský účet, který jsme vytvořili dříve. Chcete-li změnit uživatele ve svém aktuálním terminálu, použijte následující příkaz:$ su hadoop
- S těmito nainstalovanými balíčky je čas vygenerovat páry veřejného a soukromého klíče pomocí následujícího příkazu. Všimněte si, že terminál vás vyzve několikrát, ale vše, co musíte udělat, je stále mačkat
ENTERpokračovat.$ ssh-keygen -t rsa
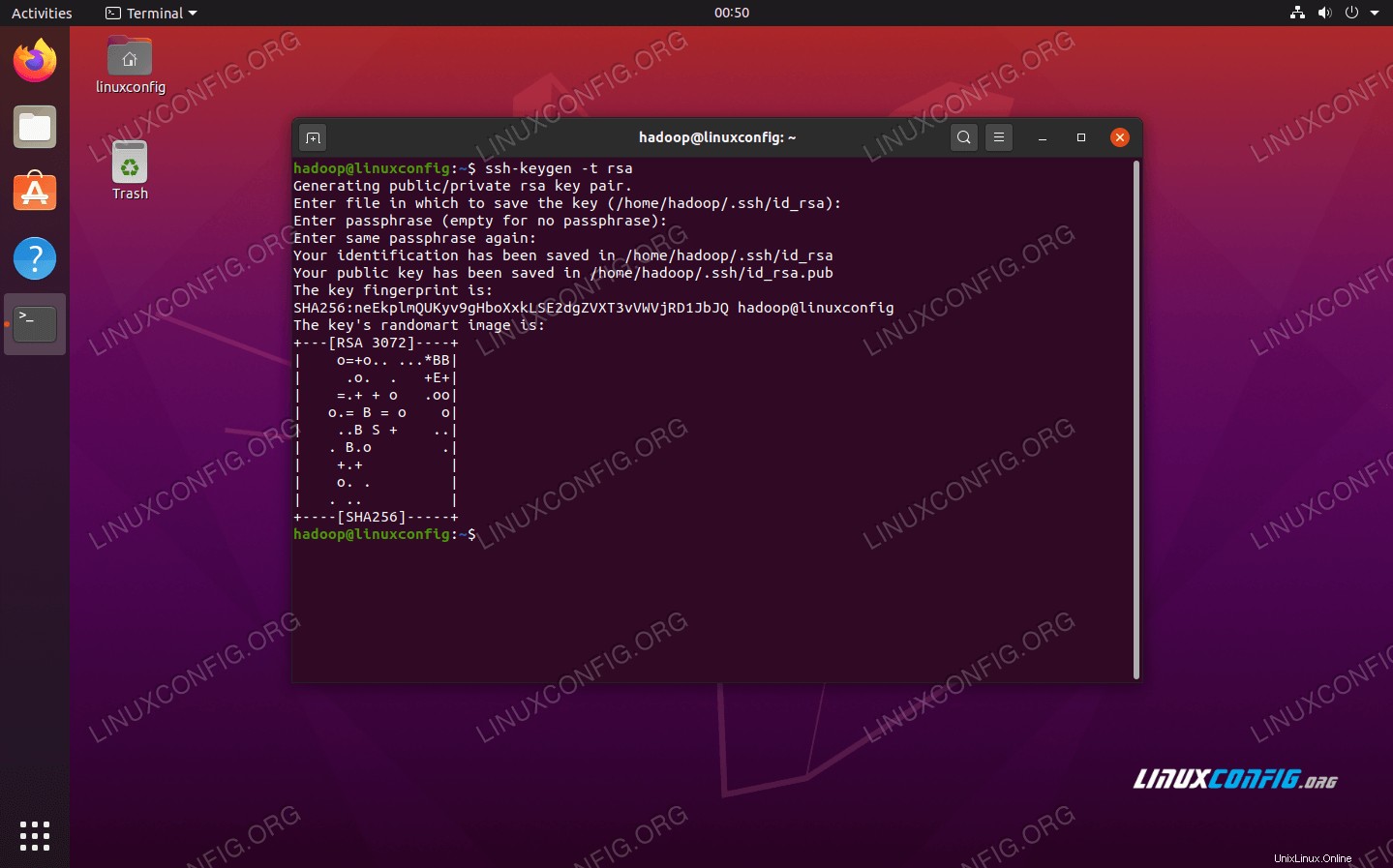 Generování klíčů RSA pro SSH bez hesla
Generování klíčů RSA pro SSH bez hesla - Dále zkopírujte nově vygenerovaný klíč RSA do
id_rsa.pubpřesauthorized_keys:$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- Můžete se ujistit, že konfigurace byla úspěšná, pomocí SSHing do localhost. Pokud to dokážete, aniž byste byli vyzváni k zadání hesla, můžete jít.
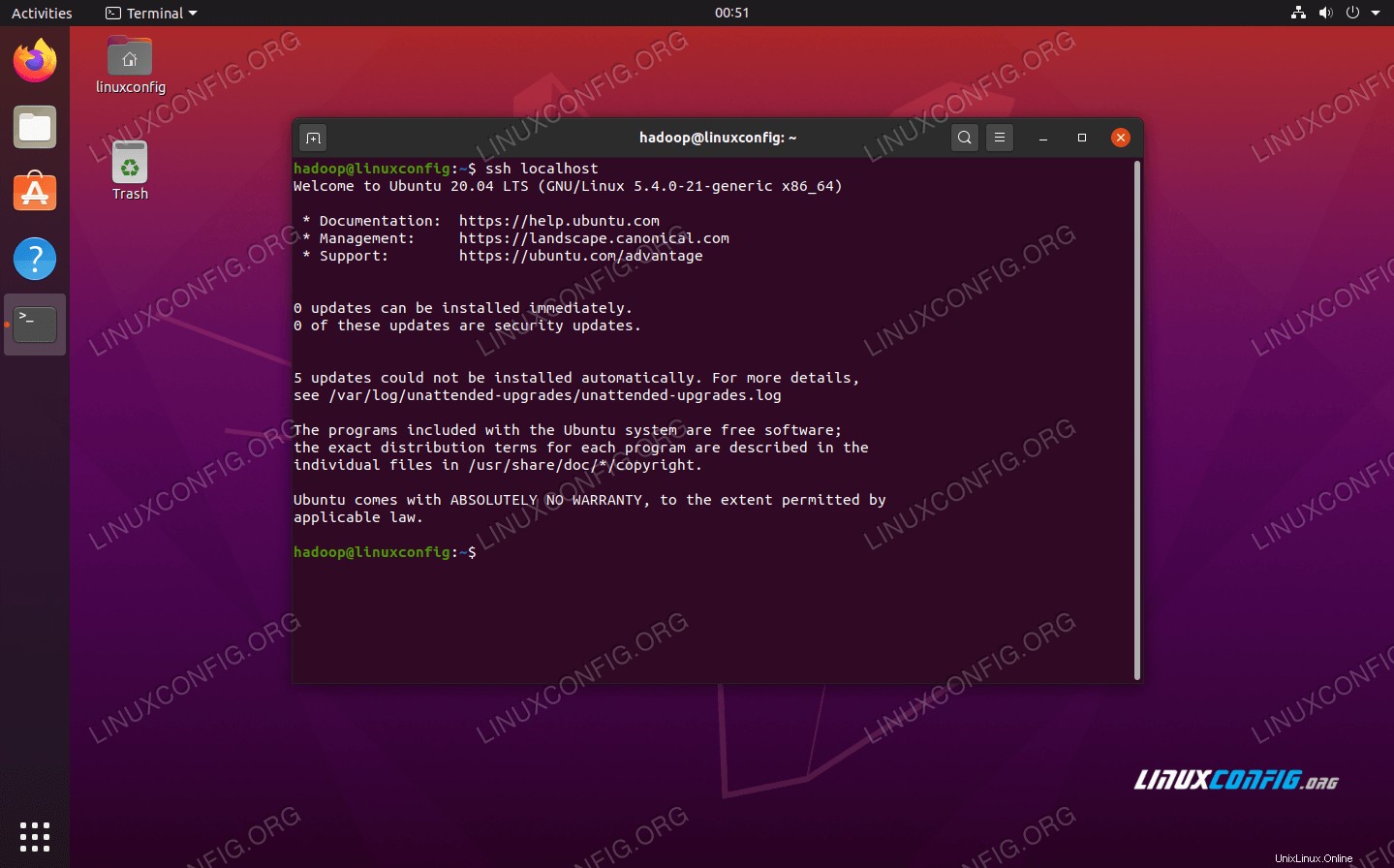 SSH do systému bez výzvy k zadání hesla znamená, že to fungovalo
SSH do systému bez výzvy k zadání hesla znamená, že to fungovalo
Nainstalujte Hadoop a nakonfigurujte související soubory XML
Přejděte na web Apache a stáhněte si Hadoop. Tento příkaz můžete také použít, pokud si chcete přímo stáhnout binární soubor Hadoop verze 3.1.3:
$ wget https://downloads.apache.org/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
Extrahujte stahování do hadoop domovský adresář uživatele pomocí tohoto příkazu:
$ tar -xzvf hadoop-3.1.3.tar.gz -C /home/hadoop
Nastavení proměnné prostředí
Následující export příkazy nakonfigurují požadované proměnné prostředí Hadoop v našem systému. Všechny tyto můžete zkopírovat a vložit do svého terminálu (možná budete muset změnit řádek 1, pokud máte jinou verzi Hadoop):
export HADOOP_HOME=/home/hadoop/hadoop-3.1.3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Zdrojový kód .bashrc soubor v aktuální relaci přihlášení:
$ source ~/.bashrc
Dále provedeme nějaké změny v hadoop-env.sh soubor, který lze nalézt v instalačním adresáři Hadoop pod /etc/hadoop . K otevření použijte nano nebo svůj oblíbený textový editor:
$ nano ~/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
Změňte JAVA_HOME proměnná na místo, kde je nainstalována Java. V našem systému (a pravděpodobně také ve vašem, pokud používáte Ubuntu 20.04 a doposud jste nás sledovali), změníme tento řádek na:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
 Změňte proměnnou prostředí JAVA_HOME
Změňte proměnnou prostředí JAVA_HOME To bude jediná změna, kterou tady musíme udělat. Změny můžete uložit do souboru a zavřít jej.
Změny konfigurace v souboru core-site.xml
Další změna, kterou musíme provést, je uvnitř core-site.xml soubor. Otevřete jej pomocí tohoto příkazu:
$ nano ~/hadoop-3.1.3/etc/hadoop/core-site.xml
Zadejte následující konfiguraci, která dá pokyn HDFS ke spuštění na portu localhost 9000 a nastaví adresář pro dočasná data.
fs.defaultFS
hdfs://localhost:9000
hadoop.tmp.dir
/home/hadoop/hadooptmpdata
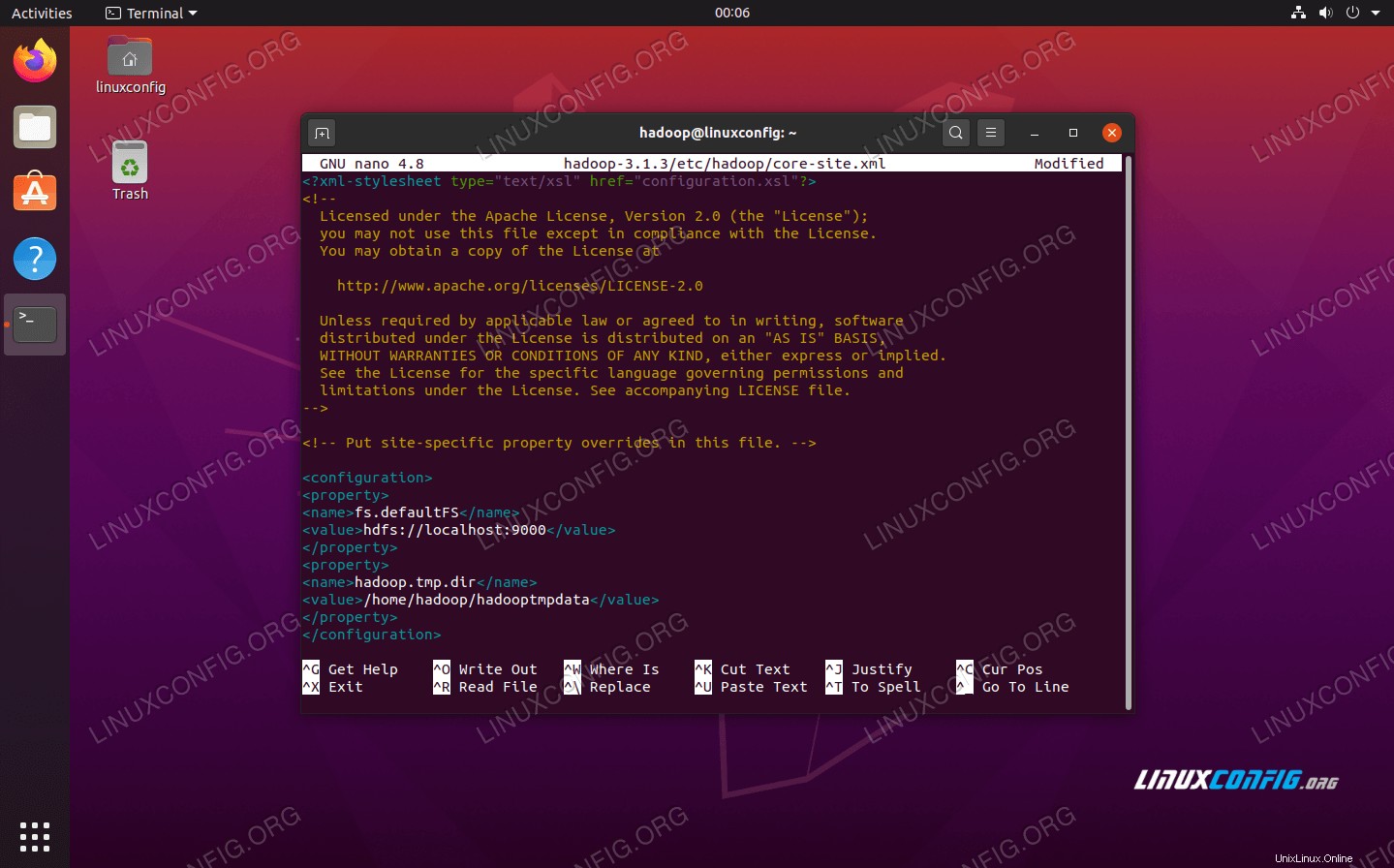 změny konfiguračního souboru core-site.xml
změny konfiguračního souboru core-site.xml Uložte změny a zavřete tento soubor. Poté vytvořte adresář, ve kterém budou uložena dočasná data:
$ mkdir ~/hadooptmpdata
Změny konfigurace v souboru hdfs-site.xml
Vytvořte dva nové adresáře pro Hadoop pro uložení informací Namenode a Datanode.
$ mkdir -p ~/hdfs/namenode ~/hdfs/datanode
Poté upravte následující soubor a sdělte Hadoopu, kde tyto adresáře najde:
$ nano ~/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
Proveďte následující změny v hdfs-site.xml před uložením a zavřením:
dfs.replication
1
dfs.name.dir
file:///home/hadoop/hdfs/namenode
dfs.data.dir
file:///home/hadoop/hdfs/datanode
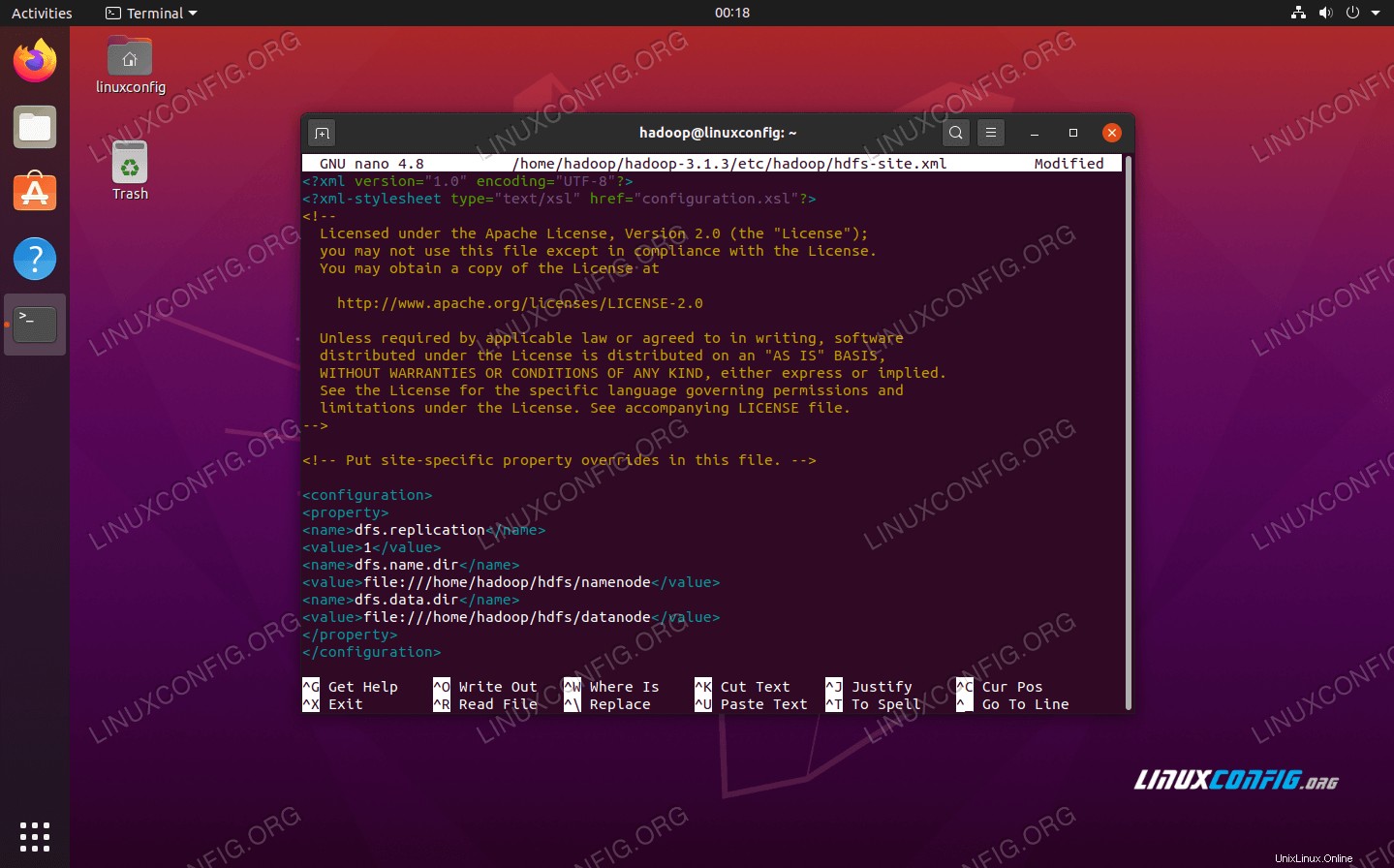 změny konfiguračního souboru hdfs-site.xml
změny konfiguračního souboru hdfs-site.xml Změny konfigurace v souboru mapred-site.xml
Otevřete konfigurační soubor MapReduce XML pomocí následujícího příkazu:
$ nano ~/hadoop-3.1.3/etc/hadoop/mapred-site.xml
A před uložením a zavřením souboru proveďte následující změny:
mapreduce.framework.name
yarn
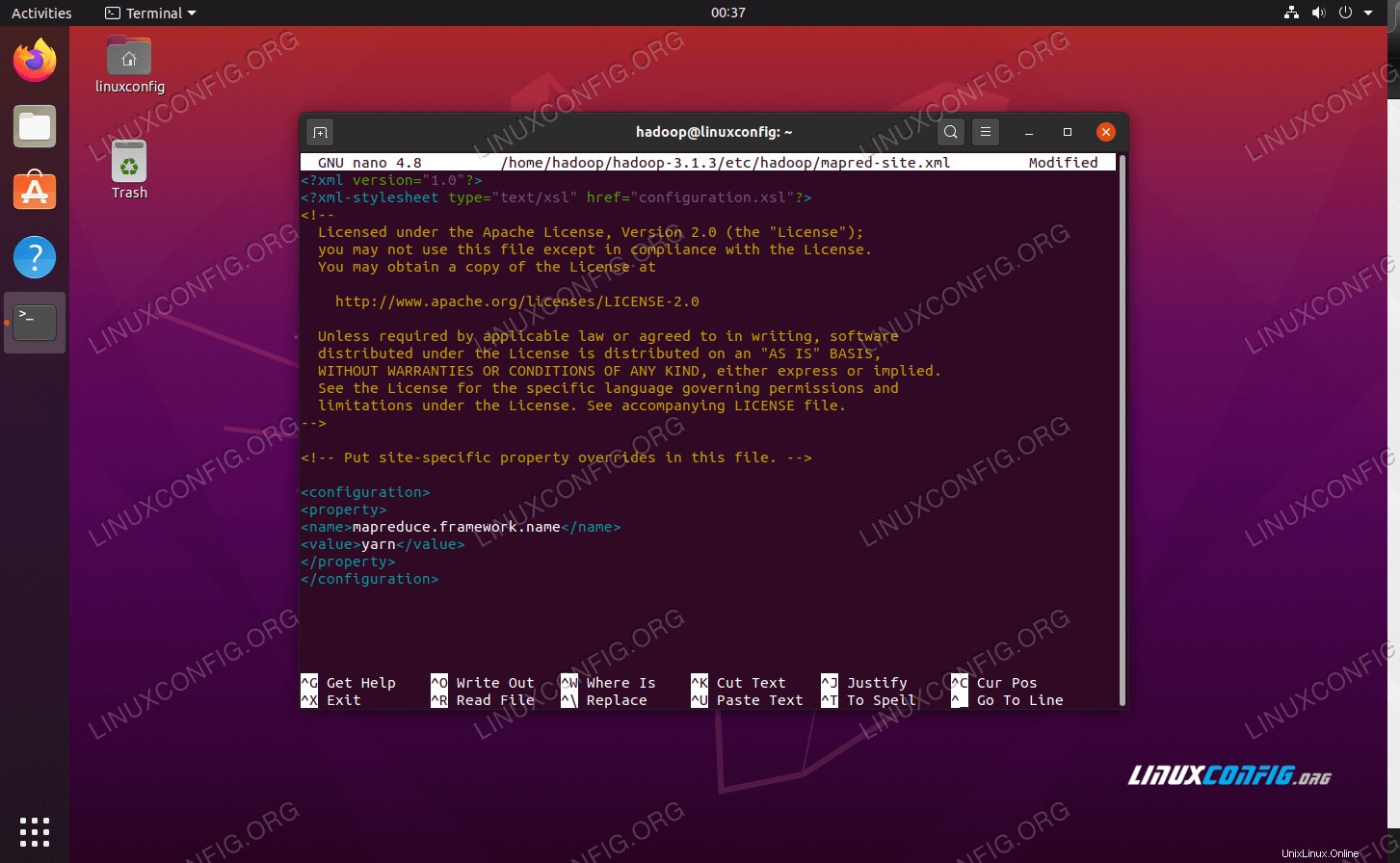 změny konfiguračního souboru mapred-site.xml
změny konfiguračního souboru mapred-site.xml Změny konfigurace v souboru yarn-site.xml
Otevřete konfigurační soubor YARN pomocí následujícího příkazu:
$ nano ~/hadoop-3.1.3/etc/hadoop/yarn-site.xml
Před uložením změn a jeho zavřením přidejte do tohoto souboru následující položky:
mapreduceyarn.nodemanager.aux-services
mapreduce_shuffle
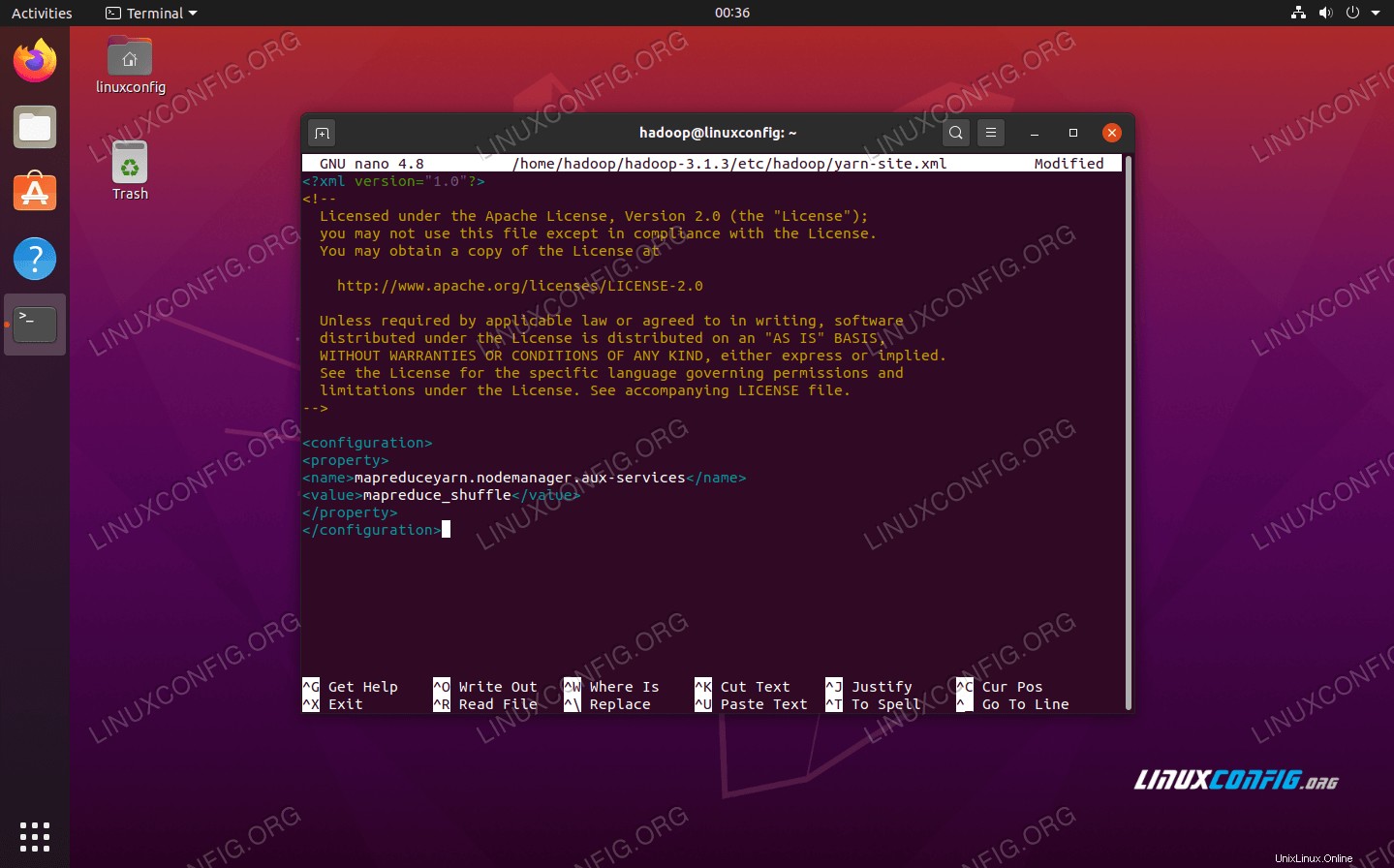 změny konfiguračního souboru yarn-site
změny konfiguračního souboru yarn-site Spuštění clusteru Hadoop
Před prvním použitím clusteru musíme jmenný uzel naformátovat. Můžete to udělat pomocí následujícího příkazu:
$ hdfs namenode -format
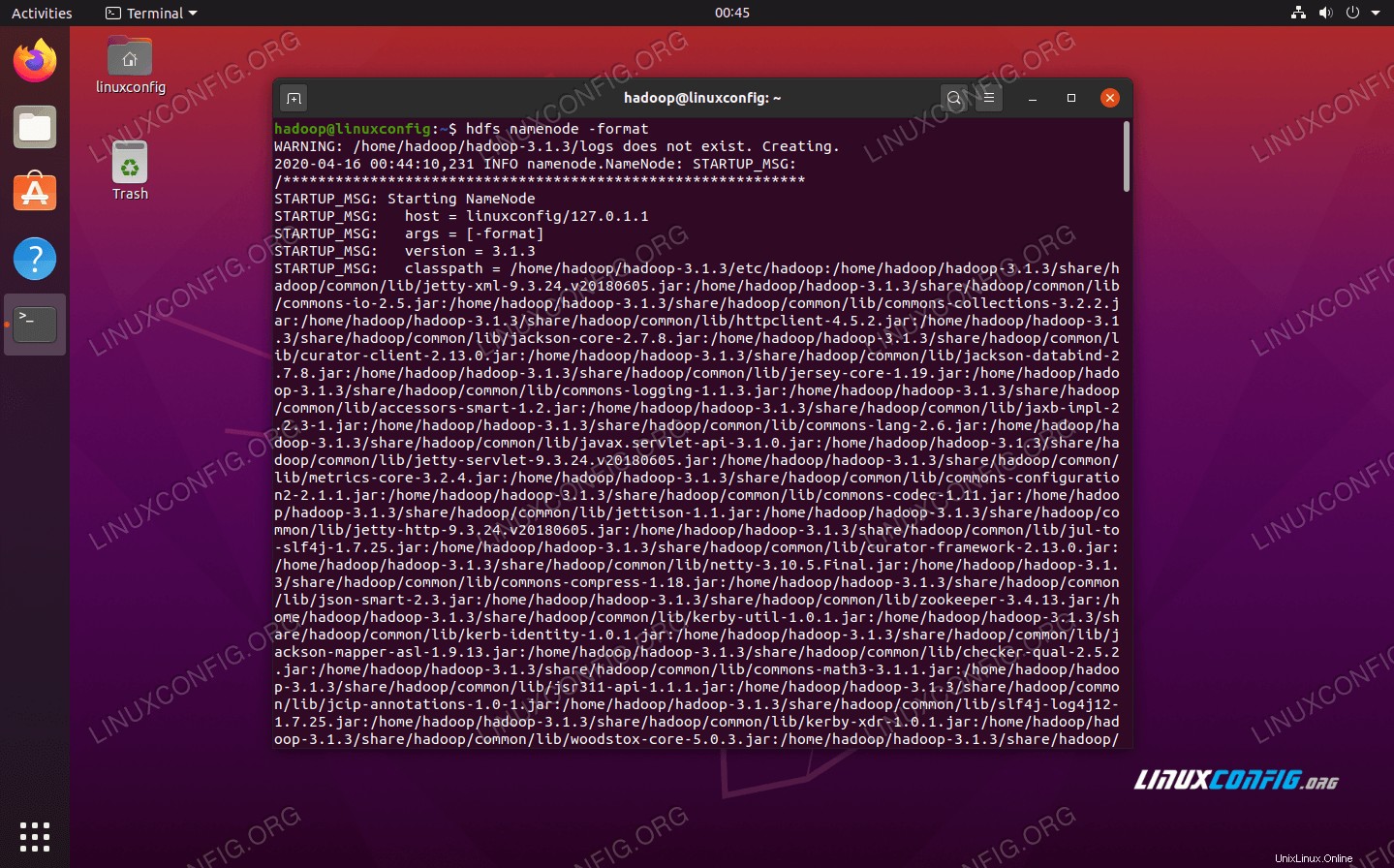 Formátování HDFS NameNode
Formátování HDFS NameNode Váš terminál vyplivne spoustu informací. Dokud neuvidíte žádné chybové zprávy, můžete předpokládat, že to fungovalo.
Dále spusťte HDFS pomocí start-dfs.sh skript:
$ start-dfs.sh
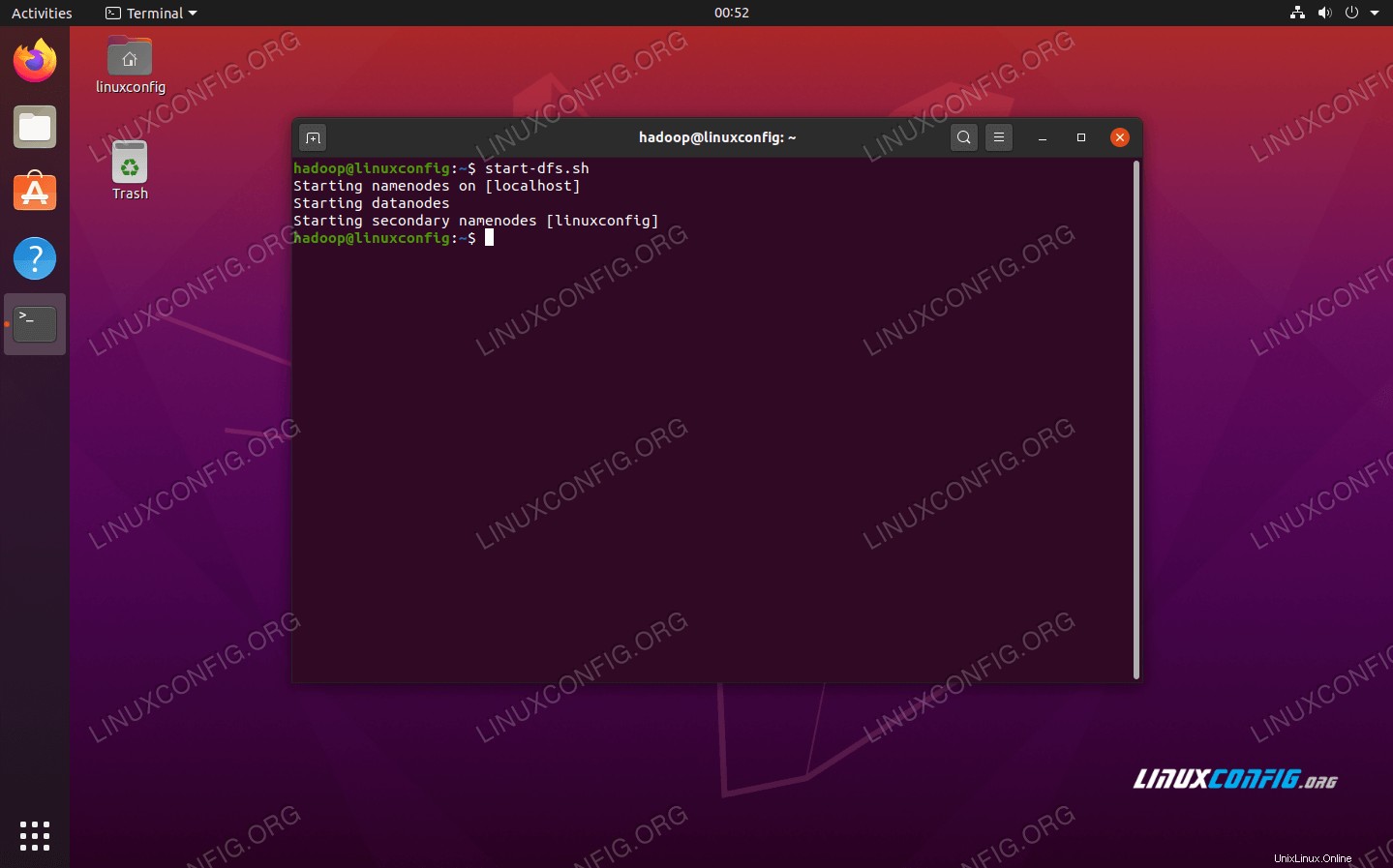 Spusťte skript start-dfs.sh
Spusťte skript start-dfs.sh
Nyní spusťte služby YARN pomocí start-yarn.sh skript:
$ start-yarn.sh
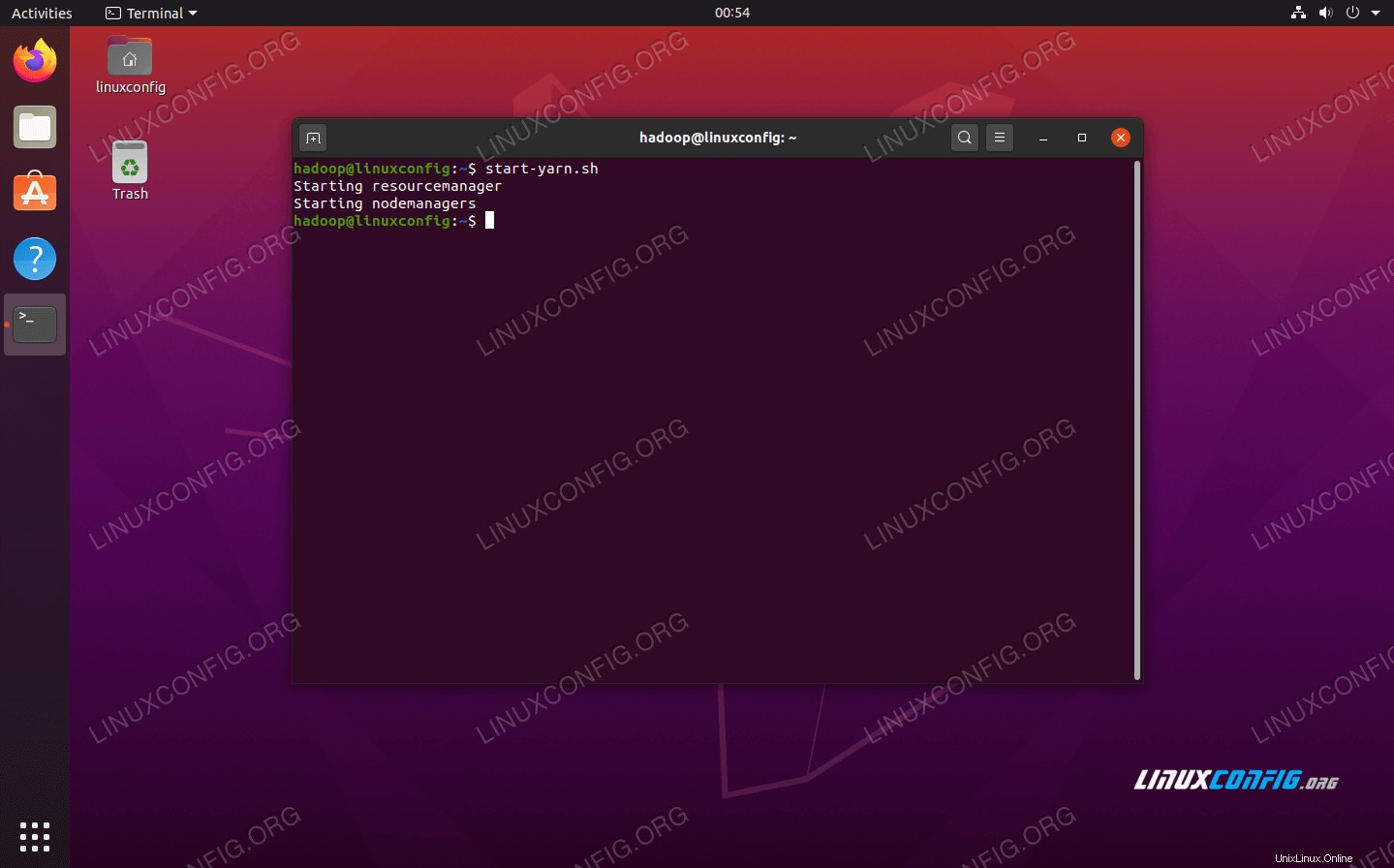 Spusťte skript start-yarn.sh
Spusťte skript start-yarn.sh
Chcete-li ověřit, zda jsou všechny služby/démony Hadoop úspěšně spuštěny, můžete použít jps příkaz. Zobrazí se všechny procesy, které aktuálně používají Javu a které běží na vašem systému.
$ jps
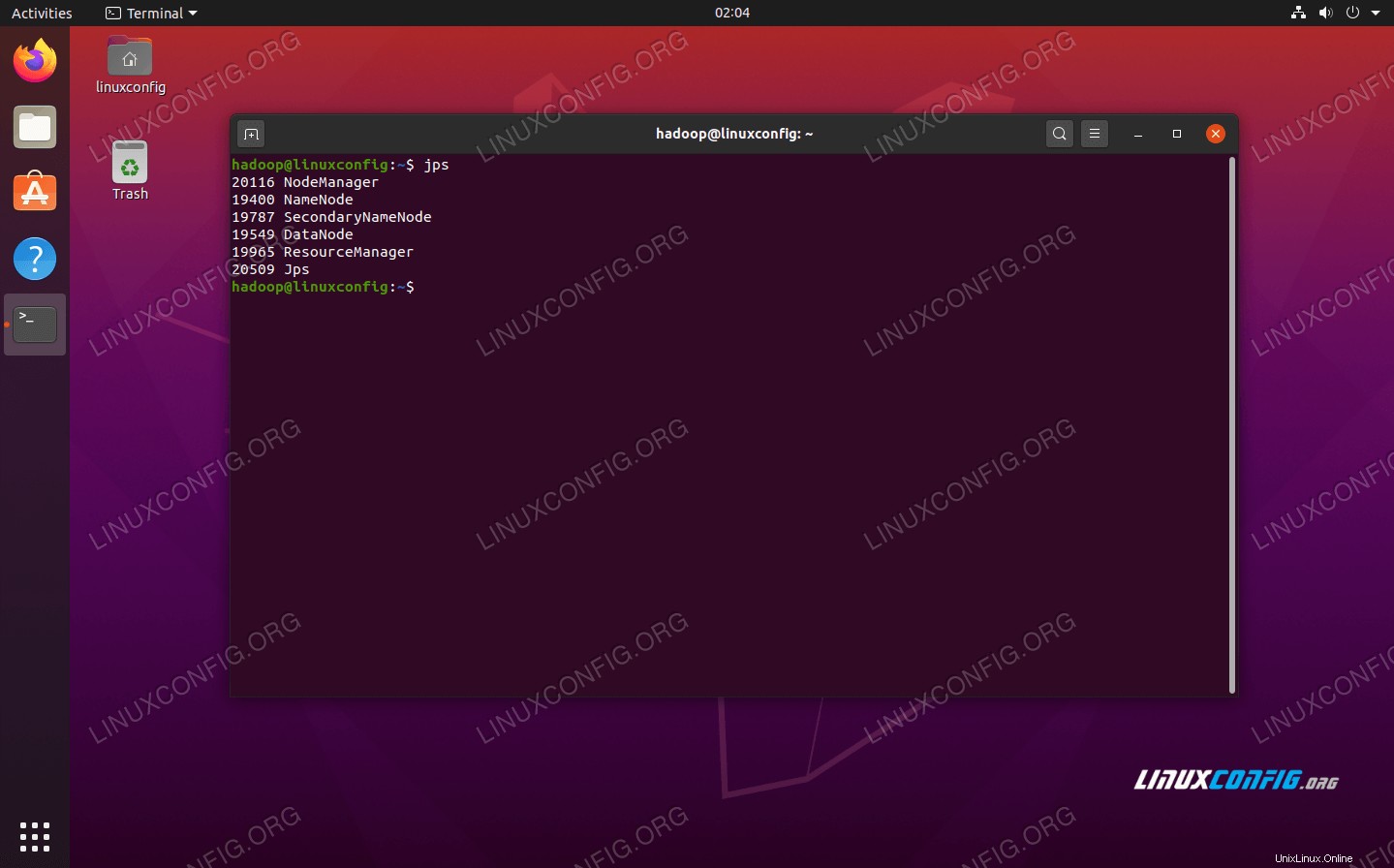 Spusťte jps, abyste viděli všechny procesy závislé na Javě a ověřili, že komponenty Hadoop běží
Spusťte jps, abyste viděli všechny procesy závislé na Javě a ověřili, že komponenty Hadoop běží Nyní můžeme zkontrolovat aktuální verzi Hadoop pomocí některého z následujících příkazů:
$ hadoop version
nebo
$ hdfs version
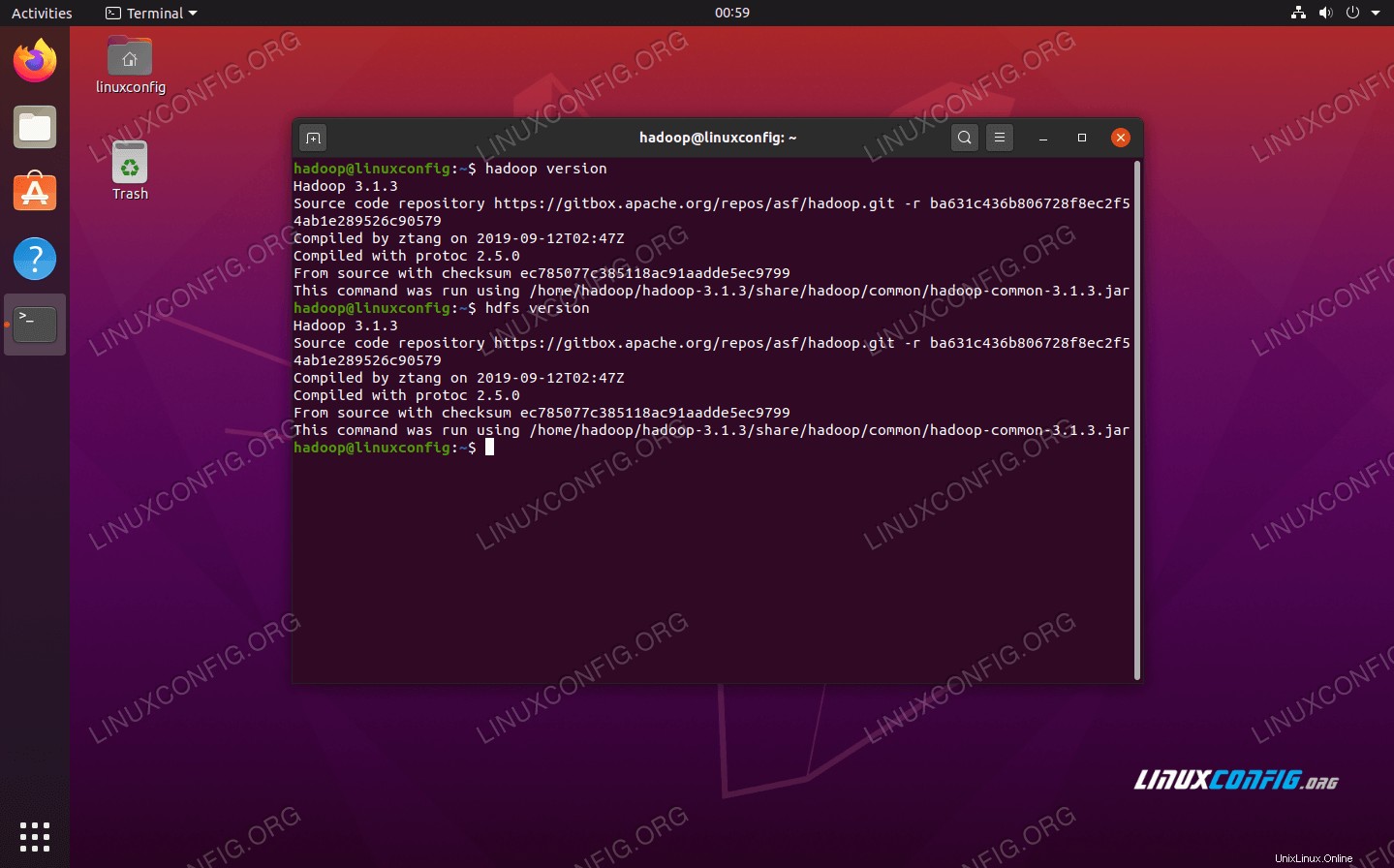 Ověření instalace Hadoop a aktuální verze
Ověření instalace Hadoop a aktuální verze Rozhraní příkazového řádku HDFS
Příkazový řádek HDFS se používá pro přístup k HDFS a pro vytváření adresářů nebo vydávání dalších příkazů pro manipulaci se soubory a adresáři. Pomocí následující syntaxe příkazu vytvořte některé adresáře a vypište je:
$ hdfs dfs -mkdir /test $ hdfs dfs -mkdir /hadooponubuntu $ hdfs dfs -ls /
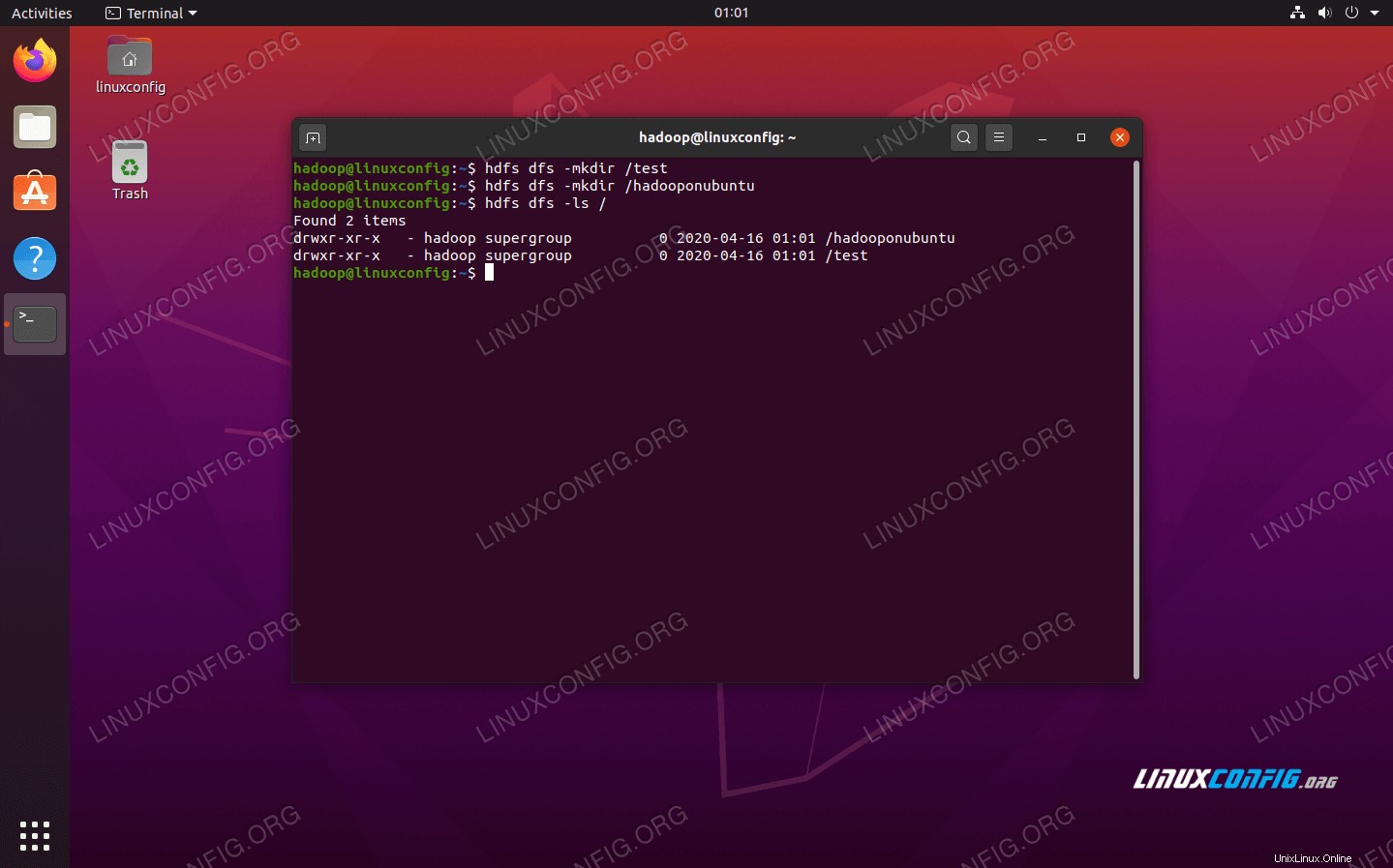 Interakce s příkazovým řádkem HDFS
Interakce s příkazovým řádkem HDFS Přístup k Namenode a YARN z prohlížeče
K webovému uživatelskému rozhraní pro NameNode a YARN Resource Manager můžete přistupovat prostřednictvím libovolného prohlížeče podle vašeho výběru, jako je Mozilla Firefox nebo Google Chrome.
Pro webové uživatelské rozhraní NameNode přejděte na http://HADOOP-HOSTNAME-OR-IP:50070
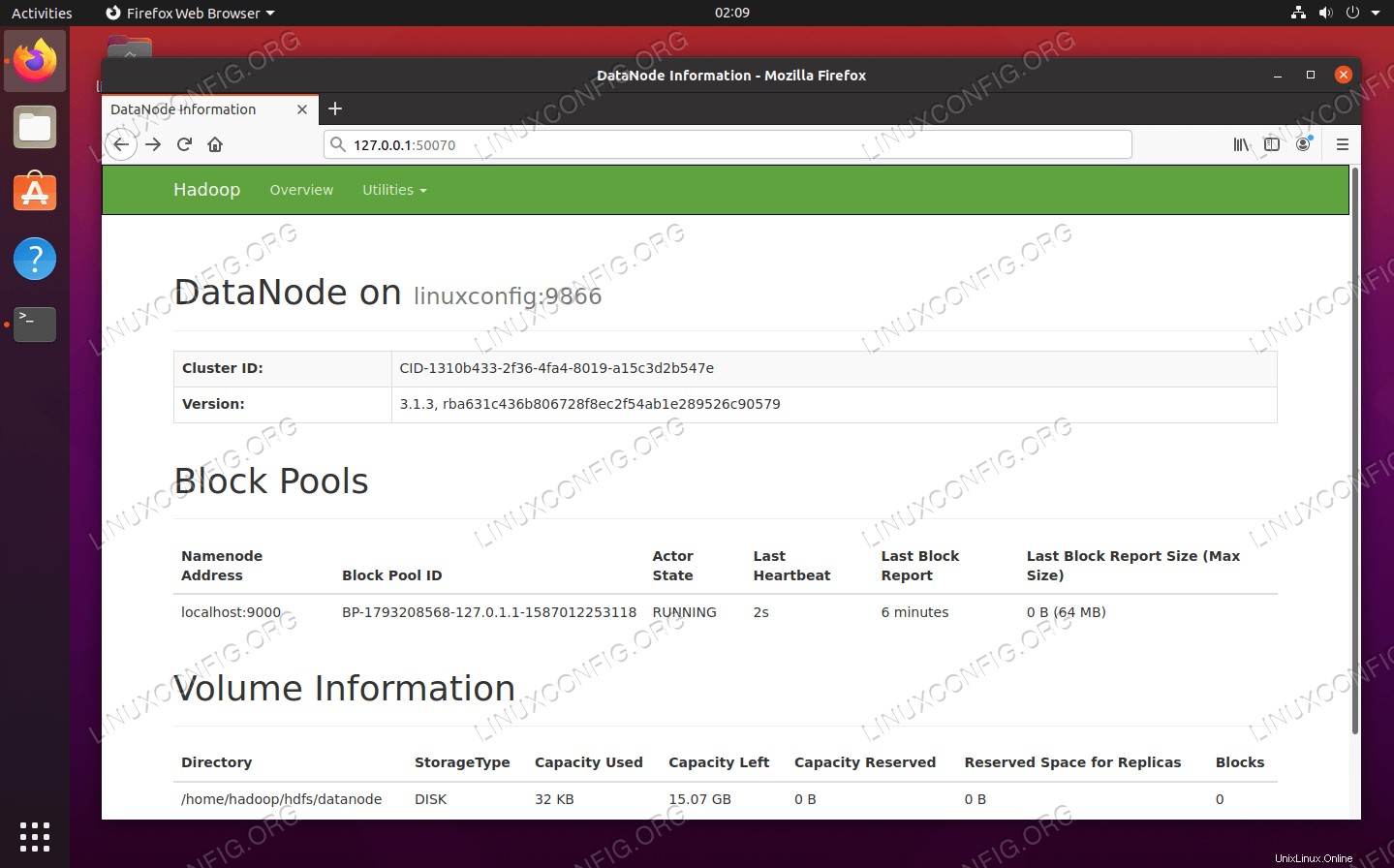 Webové rozhraní DataNode pro Hadoop
Webové rozhraní DataNode pro Hadoop
Pro přístup k webovému rozhraní YARN Resource Manager, které zobrazí všechny aktuálně spuštěné úlohy v clusteru Hadoop, přejděte na http://HADOOP-HOSTNAME-OR-IP:8088
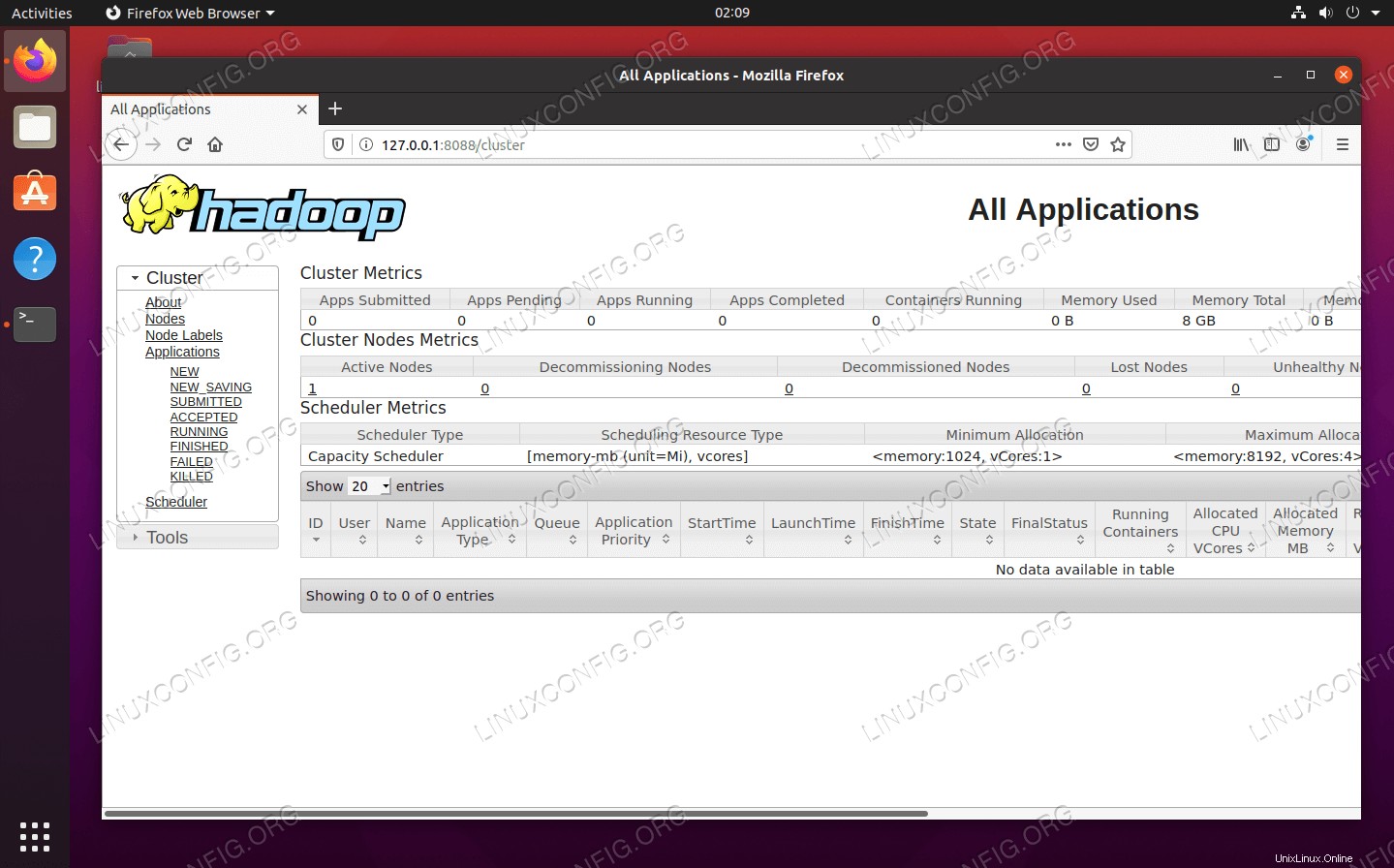 Webové rozhraní YARN Resource Manager pro Hadoop
Webové rozhraní YARN Resource Manager pro Hadoop Závěr
V tomto článku jsme viděli, jak nainstalovat Hadoop na cluster s jedním uzlem v Ubuntu 20.04 Focal Fossa. Hadoop nám poskytuje šikovné řešení pro práci s velkými daty, které nám umožňuje využívat clustery pro ukládání a zpracování našich dat. Díky flexibilní konfiguraci a pohodlnému webovému rozhraní nám usnadňuje život při práci s velkými sadami dat.