V tomto tutoriálu se naučíme, jak nastavit víceuzlový hadoop cluster na Ubuntu 16.04. Hadoop cluster, který má více než 1 datový uzel, je víceuzlový hadoop cluster, proto je cílem tohoto tutoriálu zprovoznit a spustit 2 datové uzly.
1) Předpoklady
- Ubuntu 16.04
- Hadoop-2.7.3
- Java 7
- SSH
Pro tento tutoriál mám dvě ubuntu 16.04 systémy, říkám jim mistr a otrok na každém systému poběží jeden datový uzel.
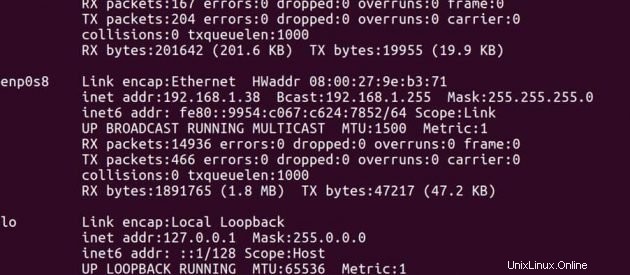
IP adresa Hlavního -> 192.168.1.37
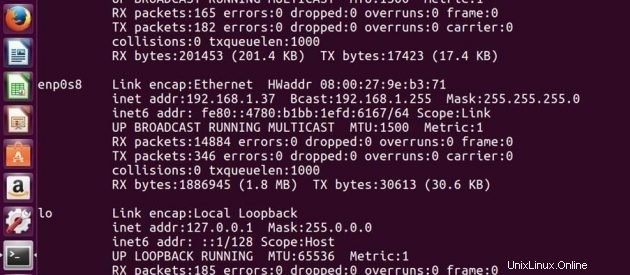
IP adresa Slave -> 192.168.1.38
Na hlavní
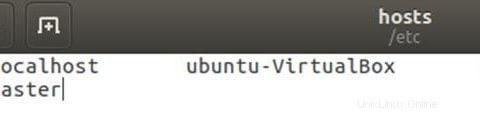
Upravte soubor hostitelů s hlavní a podřízenou IP adresou.
sudo gedit /etc/hostsUpravte soubor, jak je uvedeno níže, můžete odstranit další řádky v souboru. Po úpravě soubor uložte a zavřete.

Na Slave
Upravte soubor hostitelů s hlavní a podřízenou IP adresou.
sudo gedit /etc/hostsUpravte soubor, jak je uvedeno níže, můžete odstranit další řádky v souboru. Po úpravě soubor uložte a zavřete.
2) Instalace Java
Před nastavením hadoopu musíte mít na svých systémech nainstalovanou javu. Nainstalujte otevřený JDK 7 na oba počítače ubuntu pomocí níže uvedených příkazů.
sudo add-apt-repository ppa:openjdk-r/ppasudo apt-get updatedo apt-get install openjdk-7-jdk
Spusťte níže uvedený příkaz a zjistěte, zda je Java ve vašem systému nainstalována.
java -version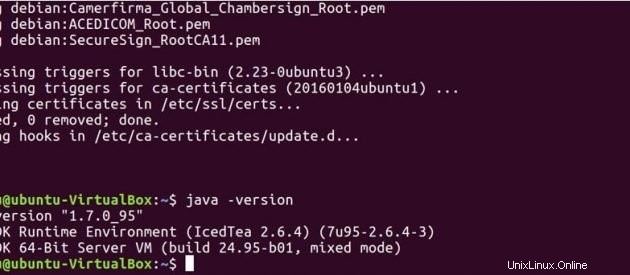
Ve výchozím nastavení se java ukládá na /usr/lib/jvm/ adresář.
ls /usr/lib/jvm
Nastavte cestu Java v .bashrc soubor.
sudo gedit .bashrcexport JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
exportovat PATH=$PATH:/usr/lib/jvm/java-7-openjdk-amd64/bin
Spusťte příkaz níže a aktualizujte změny provedené v souboru .bashrc.
source .bashrc3) SSH
Hadoop vyžaduje přístup SSH ke správě svých uzlů, proto musíme nainstalovat ssh na hlavní i podřízené systémy.
sudo apt-get install openssh-server</pre
Now, we have to generate an SSH key on master machine. When it asks you to enter a file name to save the key, do not give any name, just press enter.
ssh-keygen -t rsa -P ""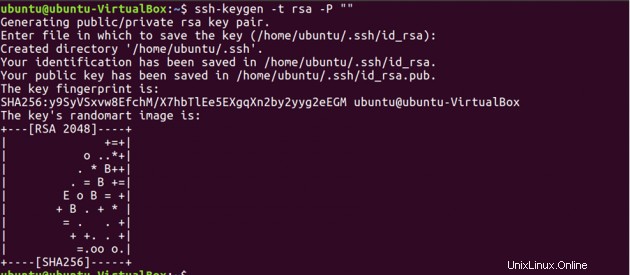
Za druhé, musíte povolit SSH přístup k vašemu hlavnímu počítači pomocí tohoto nově vytvořeného klíče.
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
Nyní otestujte nastavení SSH připojením k místnímu počítači.
ssh localhost
Nyní spusťte níže uvedený příkaz a odešlete veřejný klíč vygenerovaný na master na slave.
ssh-copy-id -i $HOME/.ssh/id_rsa.pub ubuntu@slave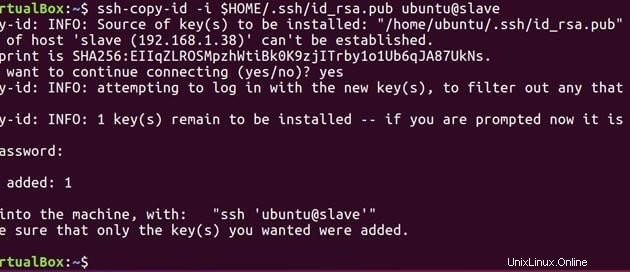
Nyní, když mají master i slave veřejný klíč, můžete připojit master k master a master k slave také.
ssh master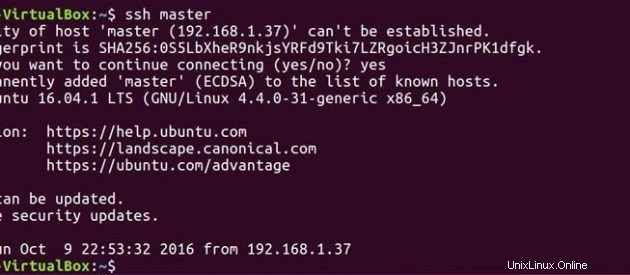
ssh slave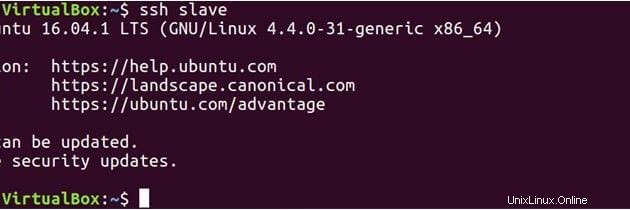
Na hlavní
Upravte hlavní soubor, jak je uvedeno níže.
sudo gedit hadoop-2.7.3/etc/hadoop/masters
Upravte soubor slaves, jak je uvedeno níže.
sudo gedit hadoop-2.7.3/etc/hadoop/slaves
Na Slave
Upravte hlavní soubor, jak je uvedeno níže.
sudo gedit hadoop-2.7.3/etc/hadoop/masters4) Instalace Hadoop
Nyní, když máme připravené nastavení java a ssh. Je dobré jít a nainstalovat hadoop na oba systémy. Ke stažení balíčku hadoop použijte níže uvedený odkaz. Používám nejnovější stabilní verzi hadoop 2.7.3
http://hadoop.apache.org/releases.html
Na hlavní
Níže uvedený příkaz stáhnehadoop-2.7.3 soubor tar.
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gz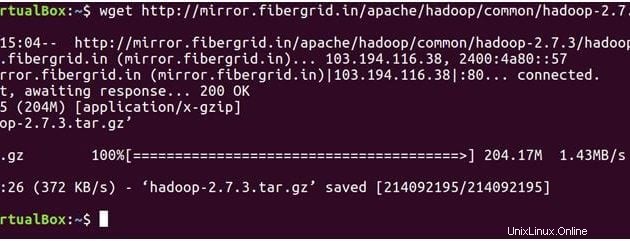
lsRozbalte soubor
tar -xvf hadoop-2.7.3.tar.gz
ls
Potvrďte, že hadoop je nainstalován ve vašem systému.
cd hadoop-2.7.3/
bin/hadoop-2.7.3/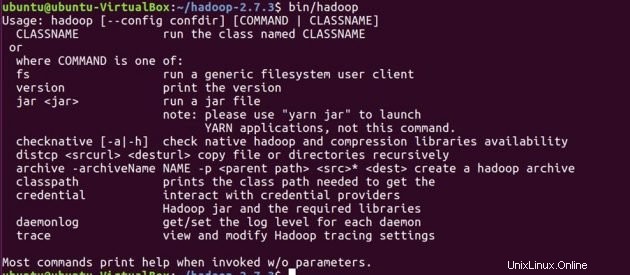
Před nastavením konfigurací pro hadoop nastavíme níže proměnné prostředí v souboru .bashrc.
cd
sudo gedit .bashrcProměnné prostředí Hadoop
# Set Hadoop-related environment variables
export HADOOP_HOME=$HOME/hadoop-2.7.3
export HADOOP_CONF_DIR=$HOME/hadoop-2.7.3/etc/hadoop
export HADOOP_MAPRED_HOME=$HOME/hadoop-2.7.3
export HADOOP_COMMON_HOME=$HOME/hadoop-2.7.3
export HADOOP_HDFS_HOME=$HOME/hadoop-2.7.3
export YARN_HOME=$HOME/hadoop-2.7.3
# Add Hadoop bin/ directory to PATH
export PATH=$PATH:$HOME/hadoop-2.7.3/bin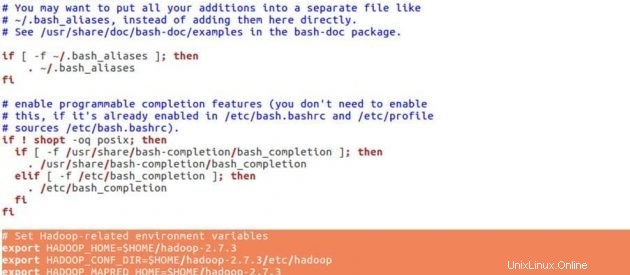
Umístěte pod řádky na konec .bashrc soubor, uložte soubor a zavřete jej.
source .bashrcNakonfigurujte JAVA_HOME v ‘hadoop-env.sh‘ . Tento soubor specifikuje proměnné prostředí, které ovlivňují JDK používané démony Apache Hadoop 2.7.3 spouštěnými spouštěcími skripty Hadoop:
cd hadoop-2.7.3/etc/hadoop/sudo gedit hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64

Nastavte cestu Java, jak je uvedeno výše, uložte soubor a zavřete jej.
Nyní vytvoříme NameNode a DataNode adresáře.
cd
mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/namenode
mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/datanode
Hadoop má mnoho konfiguračních souborů, které je třeba nakonfigurovat podle požadavků vaší infrastruktury hadoop. Pojďme nakonfigurovat konfigurační soubory hadoop jeden po druhém.
cd hadoop-2.7.3/etc/hadoop/
sudo gedit core-site.xmlCore-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>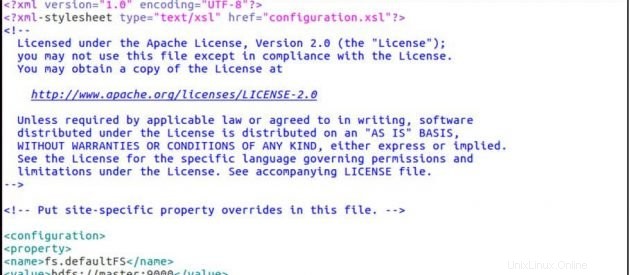
sudo gedit hdfs-site.xmlhdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/datanode</value>
</property>
</configuration>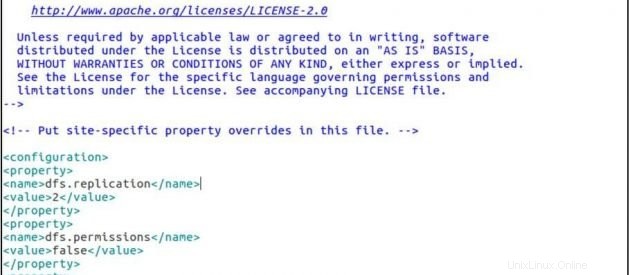
sudo gedit yarn-site.xmlyarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
cp mapred-site.xml.template mapred-site.xml
sudo gedit mapred-site.xmlmapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>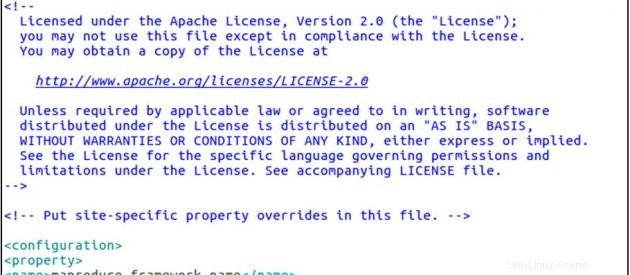
Nyní postupujte podle stejných kroků instalace hadoop a konfigurace na podřízeném počítači. Po instalaci a konfiguraci hadoop na obou systémech je první věcí při spuštění clusteru hadoop formátování hadoop souborový systém , který je implementován nad lokálními souborovými systémy vašeho clusteru. To je vyžadováno při první instalaci hadoop. Neformátujte běžící souborový systém hadoop, vymažete tím všechna vaše data HDFS.
Na hlavní
cd
cd hadoop-2.7.3/bin
hadoop namenode -format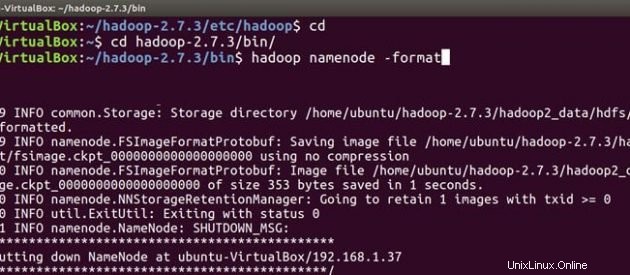
Nyní jsme připraveni spustit hadoop démony, tj. NameNode, DataNode, ResourceManager a NodeManager na našem Apache Hadoop Cluster.
cd ..Nyní spusťte níže uvedený příkaz a spusťte NameNode na hlavním počítači a DataNodes na hlavním a podřízeném.
sbin/start-dfs.sh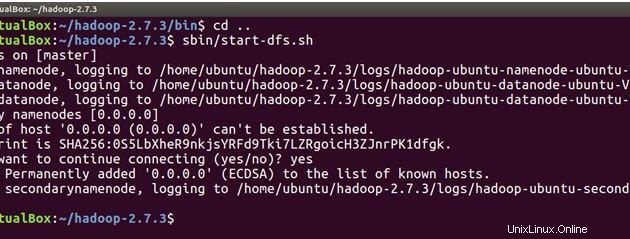
Níže uvedený příkaz spustí démony YARN, ResourceManager poběží na hlavním a NodeManager na hlavním a podřízeném.
sbin/start-yarn.sh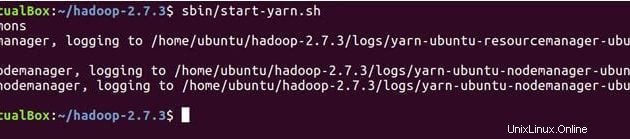
Křížově zkontrolujte, zda se všechny služby spustily správně pomocí nástroje JPS (Java Process Monitoring Tool). na hlavním i podřízeném stroji.
Níže jsou démoni běžící na hlavním počítači.
jps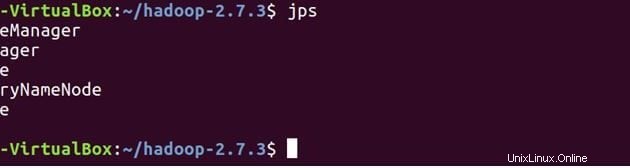
Na Slave
Uvidíte, že DataNode a NodeManager poběží také na podřízeném počítači.
jps
Nyní otevřete prohlížeč mozilla na hlavním počítači a přejděte na níže uvedenou adresu URL
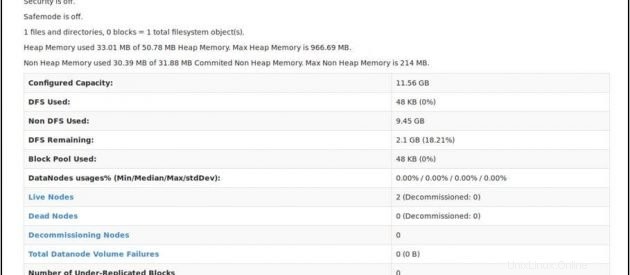
Zkontrolujte stav NameNode:http://master:50070/dfshealth.html
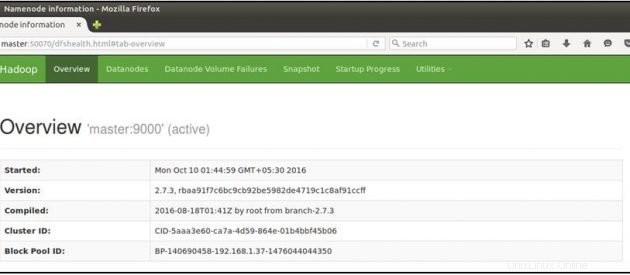
Pokud vidíte '2' v živých uzlech , to znamená 2 DataNodes jsou v provozu a úspěšně jste nastavili víceuzlový hadoop culster.
Závěr
Do svého hadoop clusteru můžete přidat více uzlů, vše, co musíte udělat, je přidat ip nového slave uzlu do slave souboru na master, zkopírovat ssh klíč do nového slave uzlu, vložit master ip do masters souboru na nový slave uzel a poté restartovat hadoop služby. Gratulujeme!! Úspěšně jste nastavili víceuzlový hadoop cluster.