Apache Hadoop je bezplatný, open-source softwarový rámec napsaný v Javě pro distribuované ukládání a zpracování velkých dat pomocí MapReduce. Zvládá velmi velkou velikost souborů dat tak, že je rozděluje do velkých bloků a distribuuje je mezi počítače v clusteru.
Namísto spoléhání se na standardní clustery OS jsou moduly Hadoop navrženy tak, aby detekovaly a spravovaly selhání na aplikační vrstvě a poskytují vám vysoce dostupné služby na úrovni softwaru.
Základní rámec Hadoop se skládá z následujících modulů,
- Hadoop Common – Obsahuje běžnou sadu knihoven a utilit pro podporu dalších modulů Hadoop
- Hadoop Distributed File System (HDFS) – Distribuovaný souborový systém založený na Javě, který ukládá data na standardním hardwaru a poskytuje aplikaci velmi vysokou propustnost.
- Hadoop PŘÍZE – Spravuje prostředky ve výpočetních clusterech a využívá je k plánování uživatelských aplikací.
- Hadoop MapReduce – Rámec pro zpracování dat ve velkém měřítku na základě programovacího modelu MapReduce.
V tomto příspěvku uvidíme, jak nainstalovat Apache Hadoop na RHEL 8.
Předpoklady
Přepněte na uživatele root.
su -
NEBO
sudo su -
Apache Hadoop v3.1.2 podporuje pouze Javu verze 8. Nainstalujte tedy buď OpenJDK 8 nebo Oracle JDK 8.
V této ukázce použiji OpenJDK 8.
yum -y install java-1.8.0-openjdk wget
Zkontrolujte verzi Java.
java -version
Výstup:
openjdk version "1.8.0_201" OpenJDK Runtime Environment (build 1.8.0_201-b09) OpenJDK 64-Bit Server VM (build 25.201-b09, mixed mode)
Nainstalujte Apache Hadoop na RHEL 8
Vytvořit uživatele Hadoop
Doporučuje se spouštět Apache Hadoop běžným uživatelem. Zde tedy vytvoříme uživatele s názvem hadoop a nastavíme mu heslo.
useradd -m -d /home/hadoop -s /bin/bash hadoop passwd hadoop
Nyní nakonfigurujte ssh bez hesla do místního systému podle následujících kroků.
# su - hadoop $ ssh-keygen $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 600 ~/.ssh/authorized_keys
Ověřte komunikaci bez hesla s místním systémem.
$ ssh 127.0.0.1
Výstup:
Pokud se připojujete přes ssh poprvé, budete muset zadat yes, abyste přidali RSA klíče ke známým hostitelům.
[hadoop@rhel8 ~]$ ssh 127.0.0.1 The authenticity of host '127.0.0.1 (127.0.0.1)' can't be established. ECDSA key fingerprint is SHA256:85jUAgtJg8RLOqs8T2egxF7U7IWIiYF+CRspO8yatAk. Are you sure you want to continue connecting (yes/no)? Yes Warning: Permanently added '127.0.0.1' (ECDSA) to the list of known hosts. Activate the web console with: systemctl enable --now cockpit.socket Last login: Wed May 8 12:15:04 2019 from 127.0.0.1 [hadoop@rhel8 ~]$
Stáhněte si Hadoop
Navštivte stránku Apache Hadoop a stáhněte si nejnovější verzi Apache Hadoop (vždy vyberte verzi, která je připravena k výrobě, podle dokumentace), nebo můžete použít následující příkaz v terminálu ke stažení Hadoop v3.1.2.
$ wget https://www-us.apache.org/dist/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz $ tar -zxvf hadoop-3.1.2.tar.gz $ mv hadoop-3.1.2 hadoop
Typy klastrů hadoop
Existují tři typy shluků Hadoop:
- Místní (samostatný) režim – Běží jako jediný proces Java.
- Pseudodistribuovaný režim – Každý démon Hadoop běží jako samostatný proces.
- Plně distribuovaný režim – víceuzlový cluster. Od několika uzlů až po extrémně velký shluk.
Nastavení proměnných prostředí
Zde nakonfigurujeme Hadoop v Pseudo-distribuovaném režimu. Nejprve nastavíme proměnné prostředí v souboru ~/.bashrc.
Změňte položky proměnných JAVA_HOME a HADOOP_HOME v souboru v závislosti na vašem prostředí.export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.201.b09-2.el8.x86_64/ export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Použijte proměnné prostředí na vaši aktuální relaci terminálu.
$ source ~/.bashrc
Nakonfigurujte Hadoop
Upravte soubor prostředí Hadoop a aktualizujte proměnnou, jak je uvedeno níže.
$ vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Aktualizujte proměnnou JAVA_HOME podle vašeho prostředí.
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.201.b09-2.el8.x86_64/
Nyní upravíme konfigurační soubory Hadoopu v závislosti na režimu clusteru, který jsme nastavili (Pseudo-Distributed).
$ cd $HADOOP_HOME/etc/hadoop
Upravte soubor core-site.xml a aktualizujte soubor s názvem hostitele HDFS.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://rhel8.itzgeek.local:9000</value>
</property>
</configuration>
Vytvořte adresáře namenode a datanode v adresáři hadoop user home /home/hadoop.
$ mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}
Upravte soubor hdfs-site.xml a aktualizujte soubor informacemi o adresáři NameNode a DataNode.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
Upravit mapred-site.xml.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> Upravte soubor yarn-site.xml.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> Naformátujte NameNode pomocí následujícího příkazu.
$ hdfs namenode -format
Výstup:
. . . . . . 2019-05-13 19:33:14,720 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1601223288-192.168.1.10-1557756194643 2019-05-13 19:33:15,100 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted. 2019-05-13 19:33:15,436 INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 2019-05-13 19:33:16,804 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 393 bytes saved in 1 seconds . 2019-05-13 19:33:17,106 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2019-05-13 19:33:17,150 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at rhel8.itzgeek.local/192.168.1.10 ************************************************************/
Firewall
Spusťte níže uvedené příkazy a povolte připojení Apache Hadoop přes bránu firewall. Spusťte tyto příkazy jako uživatel root.
firewall-cmd --permanent --add-port=9870/tcp firewall-cmd --permanent --add-port=8088/tcp firewall-cmd --reload
Spustit Hadoop &Yarn
Spusťte démony NameNode i DataNode pomocí skriptů poskytovaných Hadoopem.
$ start-dfs.sh
Výstup:
Starting namenodes on [rhel8.itzgeek.local] rhel8.itzgeek.local: Warning: Permanently added 'rhel8.itzgeek.local,fe80::4480:83a5:c52:ea80%enp0s3' (ECDSA) to the list of known hosts. Starting datanodes localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts. Starting secondary namenodes [rhel8.itzgeek.local] 2019-05-13 19:39:00,698 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Otevřete prohlížeč a přejděte na níže uvedenou adresu, abyste získali přístup k Namenode.
http://ip.ad.dre.ss:9870/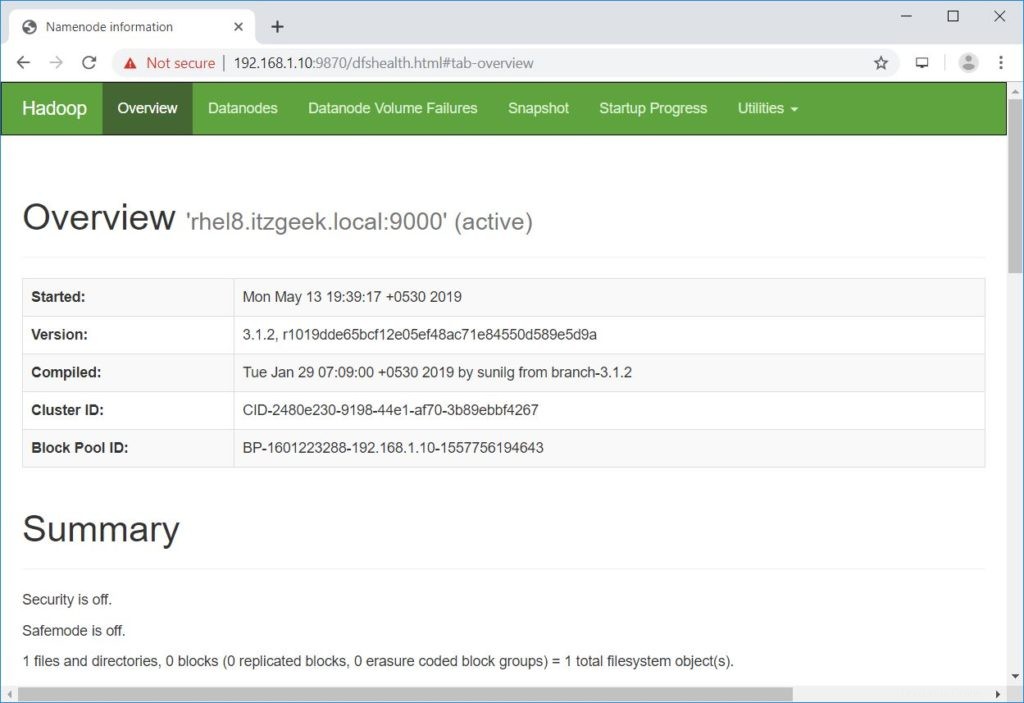
Spusťte ResourceManager a NodeManager.
$ start-yarn.sh
Výstup:
Starting resourcemanager Starting nodemanagers
Otevřete prohlížeč a přejděte na níže uvedenou adresu, abyste získali přístup k ResourceManager.
http://ip.ad.dre.ss:8088/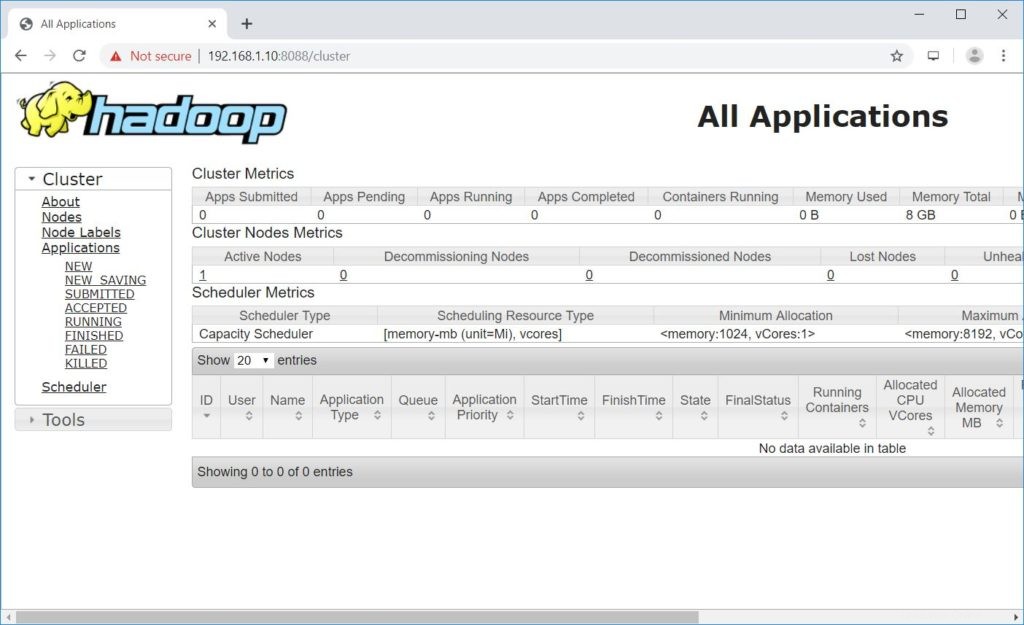
Otestujte Apache Hadoop
Nyní otestujeme Apache Hadoop tak, že na něj nahrajeme ukázkový soubor. Před nahráním souboru do HDFS vytvořte adresář v HDFS.
$ hdfs dfs -mkdir /raj
Ověřte, že vytvořený adresář existuje v HDFS.
hdfs dfs -ls /
Výstup:
Found 1 items drwxr-xr-x - hadoop supergroup 0 2019-05-08 13:20 /raj
Nahrajte soubor do adresáře HDFS raj pomocí následujícího příkazu.
$ hdfs dfs -put ~/.bashrc /raj
Nahrané soubory lze zobrazit spuštěním příkazu níže.
$ hdfs dfs -ls /raj
NEBO
Přejděte na NameNode>> Nástroje >> Procházet systém souborů v NameNode.
http://ip.ad.dre.ss:9870/explorer.html#/raj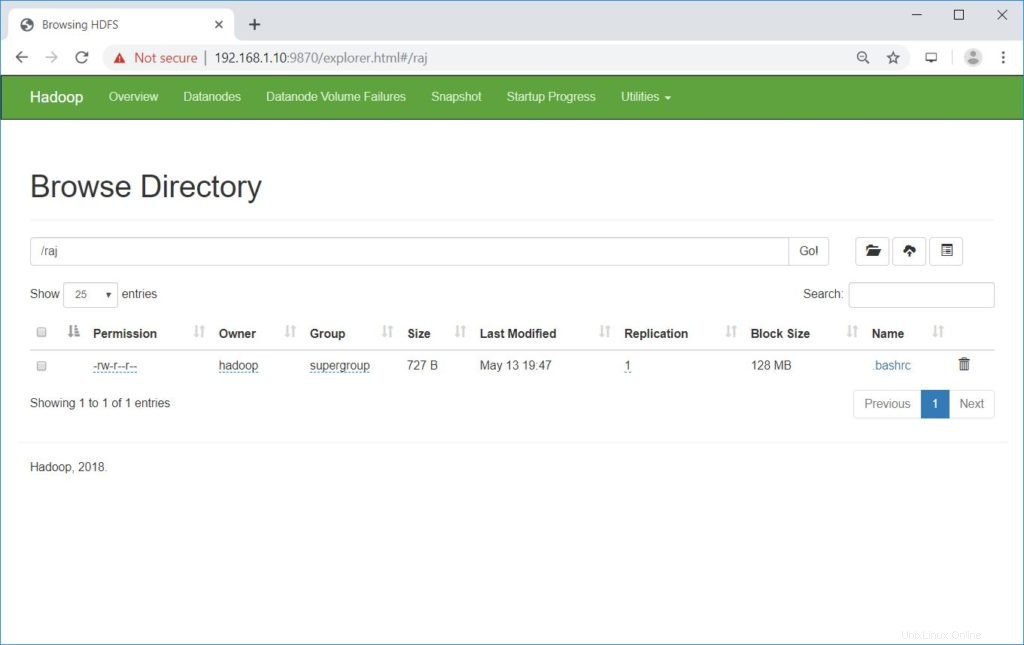
Pomocí níže uvedeného příkazu můžete zkopírovat soubory z HDFS do místních systémů souborů.
$ hdfs dfs -get /raj /tmp/
V případě potřeby můžete smazat soubory a adresáře v HDFS pomocí následujících příkazů.
$ hdfs dfs -rm -f /raj/.bashrc $ hdfs dfs -rmdir /raj
Závěr
Doufám, že vám tento příspěvek pomohl nainstalovat a nakonfigurovat jeden uzel Apache Hadoop cluster na RHEL 8. Další informace si můžete přečíst v oficiální dokumentaci Hadoopu. Podělte se o svůj názor v sekci komentářů.