Úvod
Apache Storm a Spark jsou platformy pro zpracování velkých dat, které pracují s datovými toky v reálném čase. Základní rozdíl mezi těmito dvěma technologiemi je ve způsobu zpracování dat. Storm paralelizuje výpočty úloh, zatímco Spark paralelizuje výpočty dat. Mezi rozhraními API však existují další základní rozdíly.
Tento článek poskytuje podrobné srovnání Apache Storm vs. Spark Streaming.

Storm vs. Spark:Definice
Apache Storm je rámec pro zpracování streamů v reálném čase. Trident abstrakční vrstva poskytuje Stormu alternativní rozhraní a přidává analytické operace v reálném čase.
Na druhou stranu Apache Spark je obecný analytický rámec pro rozsáhlá data. Spark Streaming API je k dispozici pro streamování dat téměř v reálném čase spolu s dalšími analytickými nástroji v rámci.
Storm vs. Spark:Srovnání
Storm i Spark jsou volně použitelné a open-source projekty Apache s podobným záměrem. Níže uvedená tabulka nastiňuje hlavní rozdíl mezi těmito dvěma technologiemi:
| Bouř | Spark | |
|---|---|---|
| Programovací jazyky | Vícejazyčná integrace | Podpora pro Python, R, Java, Scala |
| Model zpracování | Zpracování streamu s mikrodávkováním dostupným prostřednictvím Trident | Dávkové zpracování s mikrodávkováním dostupné prostřednictvím streamování |
| Primitiva | Tuple stream Tuple várka Oddíl | DSstream |
| Spolehlivost | Přesně jednou (Trident) Alespoň jednou Maximálně jednou | Přesně jednou |
| Tolerance chyb | Automatické restartování procesem supervizora | Restartování pracovníka prostřednictvím správců zdrojů |
| Správa státu | Podporováno prostřednictvím Trident | Podporováno prostřednictvím streamování |
| Snadné použití | Těžší provoz a nasazení | Snazší správa a nasazení |
Programovací jazyky
Dostupnost integrace s jinými programovacími jazyky je jedním z hlavních faktorů při výběru mezi Storm a Spark a jedním z klíčových rozdílů mezi těmito dvěma technologiemi.
Bouř
Storm má více jazyků Díky tomu je dostupný prakticky pro jakýkoli programovací jazyk. Trident API pro streamování a zpracování je kompatibilní s:
- Java
- Clojure
- Scala
Spark
Spark poskytuje rozhraní API pro streamování na vysoké úrovni pro následující jazyky:
- Java
- Scala
- Python
Některé pokročilé funkce, jako je streamování z vlastních zdrojů, nejsou pro Python dostupné. Streamování z pokročilých externích zdrojů, jako je Kafka nebo Kinesis, je však dostupné pro všechny tři jazyky.
Model zpracování
Model zpracování definuje, jak je streamování dat aktualizováno. Informace jsou zpracovávány jedním z následujících způsobů:
- Jeden záznam po druhém.
- V diskretizovaných dávkách.
Bouř
Model zpracování jádra Storm funguje přímo na n-ticových proudech, jeden záznam po druhém , což z něj dělá správnou technologii streamování v reálném čase. Trident API přidává možnost používat mikrodávky .
Spark
Model zpracování Spark rozděluje data do dávek , seskupování záznamů před dalším zpracováním. Spark Streaming API poskytuje možnost rozdělit data do mikrodávek .
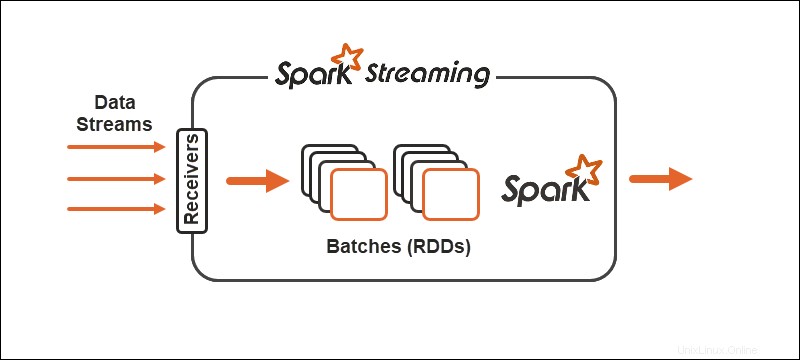
Primitiva
Primitiva představují základní stavební kameny obou technologií a způsob, jakým se transformační operace provádějí na datech.
Bouř
Core Storm funguje na několika streamech , zatímco Trident pracuje na násobku dávek a oddíly . Trident API funguje na kolekcích podobným způsobem srovnatelným s abstrakcemi na vysoké úrovni pro Hadoop. Hlavní primitivové Stormu jsou:
- Výtok které generují stream v reálném čase ze zdroje.
- Šrouby které provádějí zpracování dat a uchovávají perzistenci.
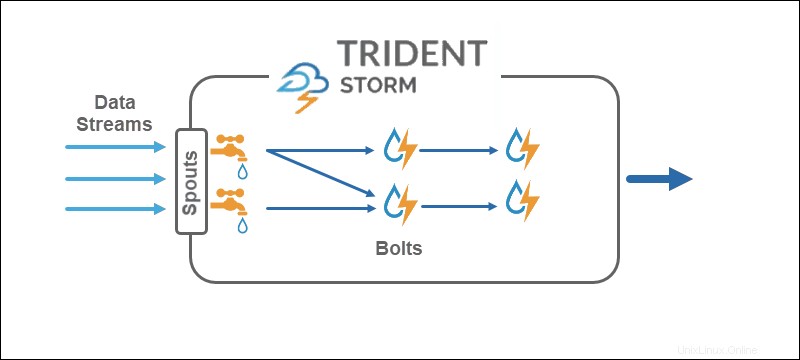
V topologii Trident se operace seskupují do šroubů. Seskupit podle, spojení, agregace, spouštěcí funkce a filtry jsou k dispozici v izolovaných dávkách a napříč různými kolekcemi. Agregace trvale ukládá v paměti podporovanou HDFS nebo v nějakém jiném obchodě, jako je Cassandra.
Spark
Díky Spark Streaming se nepřetržitý tok dat rozdělí na diskretizované toky (DStreams), sekvence Odolných distribuovaných databází (RDD).
Spark umožňuje dva obecné typy operátorů na primitivech:
1. Operátory transformace streamu kde se jeden DSstream transformuje na jiný DSstream.
2. Operátory výstupu pomáhá zapisovat informace do externích systémů.
Spolehlivost
Spolehlivost se týká zajištění doručení dat. Jsou tři možné záruky při řešení spolehlivosti datového toku:
- Alespoň jednou . Data se doručují jednou, přičemž je možné i více doručení.
- Maximálně jednou . Data se doručují pouze jednou a všechny duplikáty zaniknou. Existuje možnost, že data nedorazí.
- Přesně jednou . Data se doručují jednou, bez jakýchkoli ztrát nebo duplicit. Možnost záruky je optimální pro streamování dat, i když je obtížné ji dosáhnout.
Bouř
Storm je flexibilní, pokud jde o spolehlivost streamování dat. V jádru alespoň jednou a nejvýše jednou možnosti jsou možné. Společně s Trident API jsou k dispozici všechny tři konfigurace .
Spark
Spark se snaží zvolit optimální trasu tím, že se zaměří na přesně-jednou konfigurace streamování dat. Pokud pracovník nebo řidič selže, alespoň jednou platí sémantika.
Tolerance chyb
Tolerance chyb definuje chování streamovacích technologií v případě selhání. Spark i Storm jsou odolné vůči chybám na podobné úrovni.
Spark
V případě selhání pracovníka Spark restartuje pracovníky prostřednictvím správce zdrojů, jako je YARN. Selhání ovladače používá k obnově kontrolní bod dat.
Bouř
Pokud proces ve Storm nebo Trident selže, dohlížející proces se o restart postará automaticky. ZooKeeper hraje klíčovou roli při obnově a správě státu.
Správa státu
Spark Streaming i Storm Trident mají vestavěné technologie správy stavu. Sledování stavů pomáhá dosáhnout odolnosti proti chybám a také záruky přesně na jedno doručení.
Snadné použití a vývoj
Snadné použití a vývoj závisí na tom, jak dobře je technologie zdokumentována a jak snadné je provozovat streamy.
Spark
Spark se snadněji nasazuje a vyvíjí z těchto dvou technologií. Streamování je dobře zdokumentováno a nasazuje se na clustery Spark. Streamové úlohy jsou zaměnitelné s dávkovými úlohami.
Bouř
Storm je trochu složitější na konfiguraci a vývoj, protože obsahuje závislost na clusteru ZooKeeper. Výhoda při používání Storm je způsobena vícejazyčnou funkcí.
Storm vs. Spark:Jak si vybrat?
Volba mezi Storm a Spark závisí na projektu a dostupných technologiích. Jedním z hlavních faktorů je programovací jazyk a záruky spolehlivosti doručování dat.
I když existují rozdíly mezi streamováním a zpracováním dat, nejlepší cestou je otestovat obě technologie, abyste zjistili, co vám nejlépe vyhovuje, a jaký datový tok máte po ruce.