Úvod
Apache Spark je open-source framework, který zpracovává velké objemy streamovaných dat z více zdrojů. Spark se používá v distribuovaných výpočtech s aplikacemi strojového učení, analýzou dat a grafově paralelním zpracováním.
Tato příručka vám ukáže, jak nainstalovat Apache Spark na Windows 10 a otestujte instalaci.

Předpoklady
- Systém se systémem Windows 10
- Uživatelský účet s oprávněními správce (vyžadovaný k instalaci softwaru, úpravě oprávnění k souborům a úpravě systémové PATH)
- Příkazový řádek nebo Powershell
- Nástroj pro extrahování souborů .tar, jako je 7-Zip
Nainstalujte Apache Spark na Windows
Instalace Apache Spark na Windows 10 se může začínajícím uživatelům zdát složitá, ale tento jednoduchý návod vám pomůže. Pokud již máte nainstalované Java 8 a Python 3, můžete přeskočit první dva kroky.
Krok 1:Nainstalujte Java 8
Apache Spark vyžaduje Java 8. Můžete zkontrolovat, zda je Java nainstalována pomocí příkazového řádku.
Otevřete příkazový řádek kliknutím na Start> zadejte cmd> klikněte na Příkazový řádek .
Do příkazového řádku zadejte následující příkaz:
java -versionPokud je Java nainstalována, odpoví následujícím výstupem:
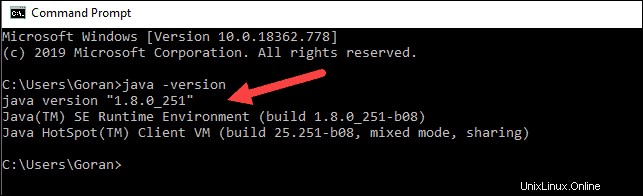
Vaše verze se může lišit. Druhá číslice je verze Java – v tomto případě Java 8.
Pokud nemáte nainstalovanou Javu:
1. Otevřete okno prohlížeče a přejděte na https://java.com/en/download/.
2. Klikněte na Stažení Java a uložte soubor do vámi zvoleného umístění.
3. Po dokončení stahování dvakrát klikněte na soubor a nainstalujte Java.
Krok 2:Nainstalujte Python
1. Chcete-li nainstalovat správce balíčků Python, přejděte ve webovém prohlížeči na https://www.python.org/.
2. Najeďte myší na Stáhnout a klikněte na Python 3.8.3 . 3.8.3 je nejnovější verze v době psaní článku.
3. Po dokončení stahování spusťte soubor.
4. V dolní části prvního dialogového okna nastavení zaškrtněte možnost Přidat Python 3.8 do PATH . Nechte druhé políčko zaškrtnuté.
5. Dále klikněte na Přizpůsobit instalaci .
6. V tomto kroku můžete nechat zaškrtnutá všechna políčka, nebo můžete zrušit zaškrtnutí možností, které nechcete.
7. Klikněte na Další .
8. Zaškrtněte políčko Instalovat pro všechny uživatele a ostatní boxy ponechte tak, jak jsou.
9. V části Přizpůsobit umístění instalace klikněte na Procházet a přejděte na jednotku C. Přidejte novou složku a pojmenujte ji Python .
10. Vyberte tuto složku a klikněte na OK .
11. Klikněte na Instalovat a nechte instalaci dokončit.
12. Po dokončení instalace klikněte na Zakázat limit délky cesty v dolní části a poté klikněte na Zavřít .
13. Pokud máte otevřený příkazový řádek, restartujte jej. Ověřte instalaci kontrolou verze Pythonu:
python --version
Výstup by měl vytisknout Python 3.8.3 .
Krok 3:Stáhněte si Apache Spark
1. Otevřete prohlížeč a přejděte na https://spark.apache.org/downloads.html.
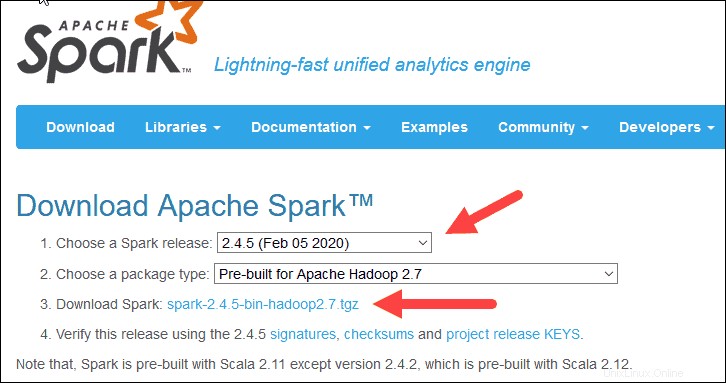
2. V části Stáhnout Apache Spark jsou zde dvě rozbalovací nabídky. Použijte aktuální verzi bez náhledu.
- V našem případě v části Vyberte verzi Spark z rozbalovací nabídky vyberte 2.4.5 (5. února 2020) .
- Ve druhém rozbalovacím seznamu Vyberte typ balíčku , ponechte výběr Pre-built for Apache Hadoop 2.7 .
3. Klikněte na spark-2.4.5-bin-hadoop2.7.tgz odkaz.
4. Načte se stránka se seznamem zrcadel, kde můžete vidět různé servery ke stažení. Vyberte libovolný ze seznamu a uložte soubor do složky Stažené soubory.
Krok 4:Ověřte soubor softwaru Spark
1. Ověřte integritu stahování kontrolou kontrolního součtu souboru. To zajišťuje, že pracujete s nezměněným, nepoškozeným softwarem.
2. Přejděte zpět na Spark Download a otevřete Kontrolní součet odkaz, nejlépe na nové kartě.
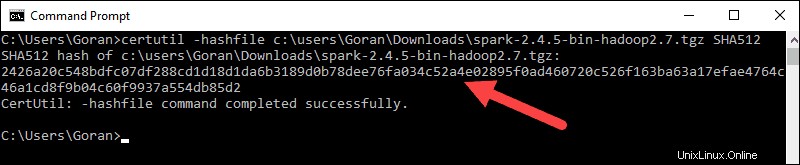
3. Dále otevřete příkazový řádek a zadejte následující příkaz:
certutil -hashfile c:\users\username\Downloads\spark-2.4.5-bin-hadoop2.7.tgz SHA512
4. Změňte uživatelské jméno na své uživatelské jméno. Systém zobrazí dlouhý alfanumerický kód spolu se zprávou Certutil: -hashfile completed successfully .
5. Porovnejte kód s kódem, který jste otevřeli na nové kartě prohlížeče. Pokud se shodují, váš stažený soubor není poškozen.
Krok 5:Nainstalujte Apache Spark
Instalace Apache Spark zahrnuje rozbalení staženého souboru na požadované místo.
1. Vytvořte novou složku s názvem Spark v kořenovém adresáři vašeho disku C:. Z příkazového řádku zadejte následující:
cd \
mkdir Spark2. V Průzkumníku vyhledejte soubor Spark, který jste stáhli.
3. Klepněte pravým tlačítkem na soubor a rozbalte jej do C:\Spark pomocí nástroje, který máte ve svém systému (např. 7-Zip).
4. Nyní vaše C:\Spark složka má novou složku spark-2.4.5-bin-hadoop2.7 s potřebnými soubory uvnitř.
Krok 6:Přidejte soubor winutils.exe
Stáhněte si winutils.exe soubor pro základní verzi Hadoop pro instalaci Spark, kterou jste si stáhli.
1. Přejděte na tuto adresu URL https://github.com/cdarlint/winutils a do přihrádky složku, vyhledejte winutils.exe a klikněte na něj.
2. Najděte Stáhnout tlačítko na pravé straně pro stažení souboru.
3. Nyní vytvořte nové složky Hadoop a přihrádka na C:pomocí Průzkumníka Windows nebo příkazového řádku.
4. Zkopírujte soubor winutils.exe ze složky Stažené soubory do C:\hadoop\bin .
Krok 7:Konfigurace proměnných prostředí
Konfigurace proměnných prostředí ve Windows přidá umístění Spark a Hadoop do vaší systémové PATH. Umožňuje vám spouštět prostředí Spark přímo z okna příkazového řádku.
1. Klikněte na Start a zadejte prostředí .
2. Vyberte výsledek označený Upravit systémové proměnné prostředí .
3. Zobrazí se dialogové okno Vlastnosti systému. V pravém dolním rohu klikněte na Proměnné prostředí a poté klikněte na Nový v dalším okně.
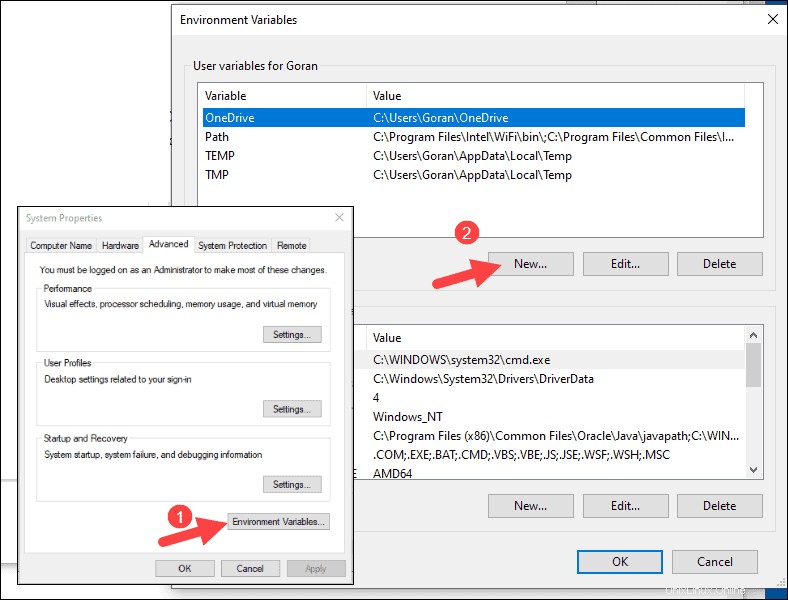
4. Pro Název proměnné zadejte SPARK_HOME .
5. Pro Hodnotu proměnné zadejte C:\Spark\spark-2.4.5-bin-hadoop2.7 a klepněte na OK. Pokud jste změnili cestu ke složce, použijte místo ní tuto.
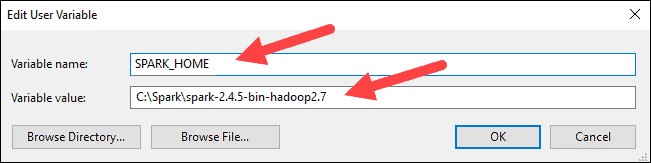
6. V horním poli klikněte na Cesta záznam a poté klikněte na Upravit . Buďte opatrní při úpravě systémové cesty. Neodstraňujte žádné položky, které jsou již v seznamu.
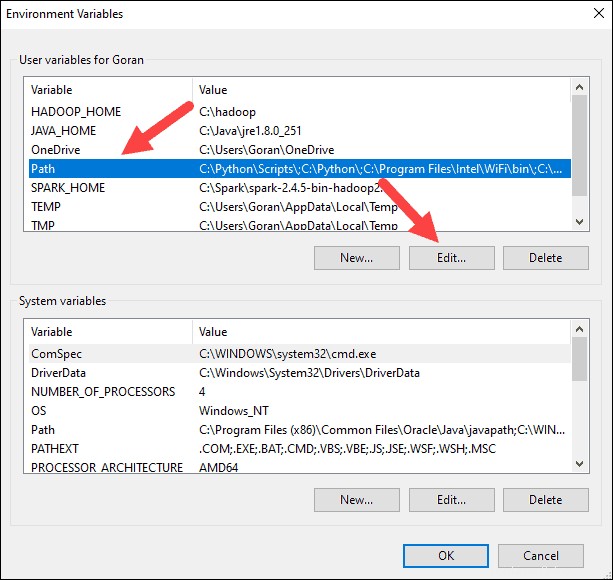
7. Vlevo by se mělo zobrazit pole se záznamy. Vpravo klikněte na Nový .
8. Systém zvýrazní nový řádek. Zadejte cestu ke složce Spark C:\Spark\spark-2.4.5-bin-hadoop2.7\bin . Doporučujeme používat %SPARK_HOME%\bin abyste se vyhnuli možným problémům s cestou.
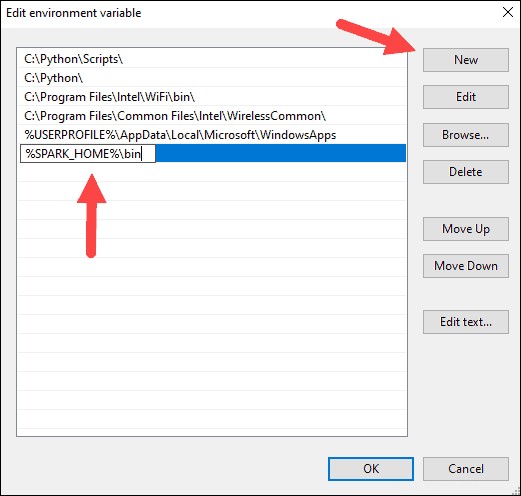
9. Opakujte tento proces pro Hadoop a Java.
- Pro Hadoop je název proměnné HADOOP_HOME a pro hodnotu použijte cestu ke složce, kterou jste vytvořili dříve:C:\hadoop. Přidejte C:\hadoop\bin do proměnné cesty pole, ale doporučujeme použít %HADOOP_HOME%\bin .
- Pro jazyk Java je název proměnné JAVA_HOME a pro hodnotu použijte cestu k vašemu adresáři Java JDK (v našem případě je to C:\Program Files\Java\jdk1.8.0_251 ).
10. Klikněte na OK zavřete všechna otevřená okna.
Krok 8:Spusťte Spark
1. Otevřete nové okno příkazového řádku kliknutím pravým tlačítkem myši a vyberte možnost Spustit jako správce :
2. Chcete-li spustit Spark, zadejte:
C:\Spark\spark-2.4.5-bin-hadoop2.7\bin\spark-shell
Pokud nastavíte cestu prostředí správně, můžete zadat spark-shell ke spuštění Sparku.
3. Systém by měl zobrazit několik řádků indikujících stav aplikace. Můžete získat vyskakovací okno Java. Vyberte možnost Povolit přístup pokračovat.
Nakonec se objeví logo Spark a výzva zobrazí Scala shell .
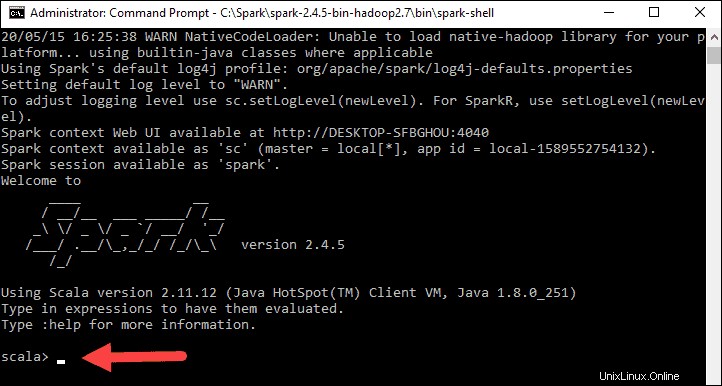
4. Otevřete webový prohlížeč a přejděte na http://localhost:4040/ .
5. Můžete nahradit localhost s názvem vašeho systému.
6. Měli byste vidět webové uživatelské rozhraní prostředí Apache Spark. Níže uvedený příklad ukazuje exekutory stránku.
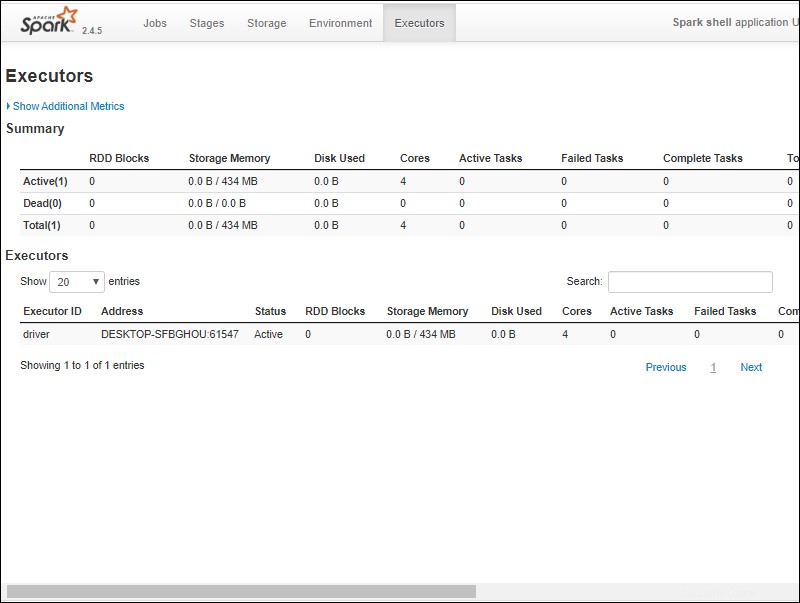
7. Chcete-li ukončit Spark a zavřít prostředí Scala, stiskněte ctrl-d v okně příkazového řádku.
Test Spark
V tomto příkladu spustíme Spark shell a použijeme Scala ke čtení obsahu souboru. Můžete použít existující soubor, například README soubor v adresáři Spark, nebo si můžete vytvořit svůj vlastní. Vytvořili jsme pnaptest s nějakým textem.
1. Otevřete okno příkazového řádku a přejděte do složky se souborem, který chcete použít, a spusťte prostředí Spark.
2. Nejprve zadejte proměnnou, kterou chcete použít v kontextu Spark, s názvem souboru. Nezapomeňte přidat příponu souboru, pokud existuje.
val x =sc.textFile("pnaptest")3. Výstup ukazuje, že je vytvořen RDD. Potom můžeme zobrazit obsah souboru pomocí tohoto příkazu k vyvolání akce:
x.take(11).foreach(println)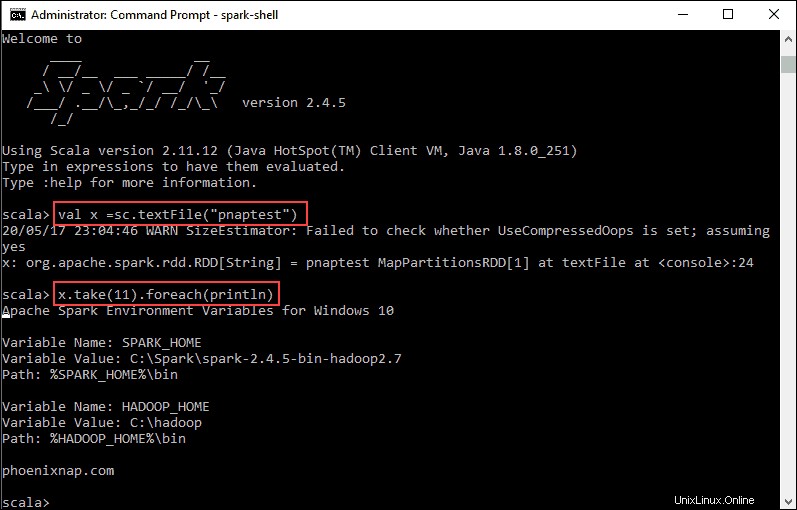
Tento příkaz dá Sparku pokyn, aby vytiskl 11 řádků ze souboru, který jste zadali. Chcete-li provést akci s tímto souborem (hodnota x ), přidejte další hodnotu y a proveďte transformaci mapy.
4. Můžete například vytisknout znaky obráceně pomocí tohoto příkazu:
val y = x.map(_.reverse)5. Systém vytvoří podřízený RDD ve vztahu k prvnímu. Poté určete, kolik řádků chcete vytisknout z hodnoty y :
y.take(11).foreach(println)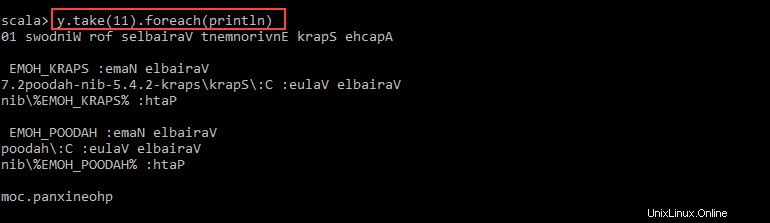
Výstup vytiskne 11 řádků pnaptestu soubor v opačném pořadí.
Po dokončení ukončete shell pomocí ctrl-d .